 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing and Exploring Training Recipes for Large-Scale Transformer-Based Weather Prediction
Apr 30, 2024



The rapid rise of deep learning (DL) in numerical weather prediction (NWP) has led to a proliferation of models which forecast atmospheric variables with comparable or superior skill than traditional physics-based NWP. However, among these leading DL models, there is a wide variance in both the training settings and architecture used. Further, the lack of thorough ablation studies makes it hard to discern which components are most critical to success. In this work, we show that it is possible to attain high forecast skill even with relatively off-the-shelf architectures, simple training procedures, and moderate compute budgets. Specifically, we train a minimally modified SwinV2 transformer on ERA5 data, and find that it attains superior forecast skill when compared against IFS. We present some ablations on key aspects of the training pipeline, exploring different loss functions, model sizes and depths, and multi-step fine-tuning to investigate their effect. We also examine the model performance with metrics beyond the typical ACC and RMSE, and investigate how the performance scales with model size.
* 9 pages, 6 figures
Time Series Predictions in Unmonitored Sites: A Survey of Machine Learning Techniques in Water Resources
Aug 18, 2023Prediction of dynamic environmental variables in unmonitored sites remains a long-standing challenge for water resources science. The majority of the world's freshwater resources have inadequate monitoring of critical environmental variables needed for management. Yet, the need to have widespread predictions of hydrological variables such as river flow and water quality has become increasingly urgent due to climate and land use change over the past decades, and their associated impacts on water resources. Modern machine learning methods increasingly outperform their process-based and empirical model counterparts for hydrologic time series prediction with their ability to extract information from large, diverse data sets. We review relevant state-of-the art applications of machine learning for streamflow, water quality, and other water resources prediction and discuss opportunities to improve the use of machine learning with emerging methods for incorporating watershed characteristics into deep learning models, transfer learning, and incorporating process knowledge into machine learning models. The analysis here suggests most prior efforts have been focused on deep learning learning frameworks built on many sites for predictions at daily time scales in the United States, but that comparisons between different classes of machine learning methods are few and inadequate. We identify several open questions for time series predictions in unmonitored sites that include incorporating dynamic inputs and site characteristics, mechanistic understanding and spatial context, and explainable AI techniques in modern machine learning frameworks.
Predicting Water Temperature Dynamics of Unmonitored Lakes with Meta Transfer Learning
Nov 10, 2020
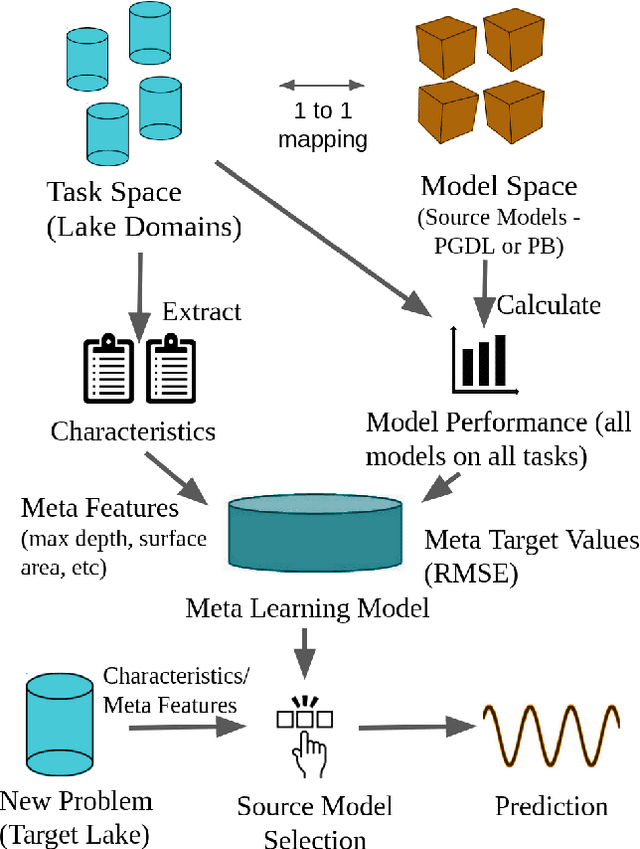
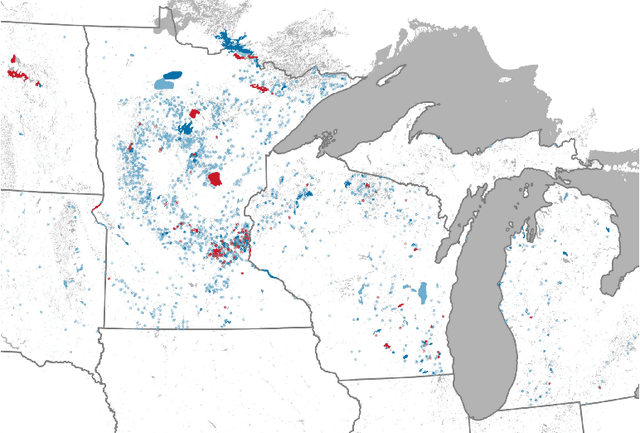
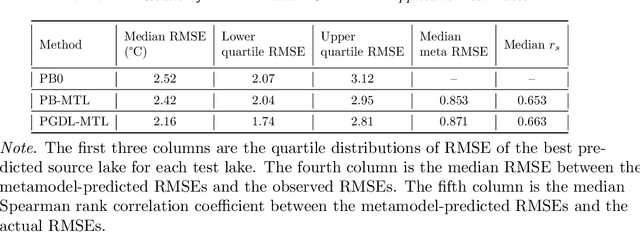
Most environmental data come from a minority of well-observed sites. An ongoing challenge in the environmental sciences is transferring knowledge from monitored sites to unobserved sites. Here, we demonstrate a novel transfer learning framework that accurately predicts temperature in unobserved lakes (targets) by borrowing models from highly observed lakes (sources). This method, Meta Transfer Learning (MTL), builds a meta-learning model to predict transfer performance from candidate source models to targets using lake attributes and candidates' past performance. We constructed source models at 145 well-observed lakes using calibrated process-based modeling (PB) and a recently developed approach called process-guided deep learning (PGDL). We applied MTL to either PB or PGDL source models (PB-MTL or PGDL-MTL, respectively) to predict temperatures in 305 target lakes treated as unobserved in the Upper Midwestern United States. We show significantly improved performance relative to the uncalibrated process-based General Lake Model, where the median RMSE for the target lakes is $2.52^{\circ}C$. PB-MTL yielded a median RMSE of $2.43^{\circ}C$; PGDL-MTL yielded $2.16^{\circ}C$; and a PGDL-MTL ensemble of nine sources per target yielded $1.88^{\circ}C$. For sparsely observed target lakes, PGDL-MTL often outperformed PGDL models trained on the target lakes themselves. Differences in maximum depth between the source and target were consistently the most important predictors. Our approach readily scales to thousands of lakes in the Midwestern United States, demonstrating that MTL with meaningful predictor variables and high-quality source models is a promising approach for many kinds of unmonitored systems and environmental variables.