 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlow Learners for PDEs: Toward a Physics-to-Physics Paradigm for Scientific Computing
Apr 02, 2026Partial differential equations (PDEs) govern nearly every physical process in science and engineering, yet solving them at scale remains prohibitively expensive. Generative AI has transformed language, vision, and protein science, but learned PDE solvers have not undergone a comparable shift. Existing paradigms each capture part of the problem. Physics-informed neural networks embed residual structure, yet they are often difficult to optimize in stiff, multiscale, or large-domain regimes. Neural operators amortize across instances, yet they commonly inherit a snapshot-prediction view of solving and can degrade over long rollouts. Diffusion-based solvers model uncertainty, yet they are often built on a solver template that still centers on state regression. We argue that the core issue is the abstraction used to train learned solvers. Many models are asked to predict states, while many scientific settings require modeling how uncertainty moves through constrained dynamics. The relevant object is transport over physically admissible futures. This motivates \emph{flow learners}: models that parameterize transport vector fields and generate trajectories through integration, echoing the continuous dynamics that define PDE evolution. This physics-to-physics alignment supports continuous-time prediction, native uncertainty quantification, and new opportunities for physics-aware solver design. We explain why transport-based learning offers a stronger organizing principle for learned PDE solving and outline the research agenda that follows from this shift.
Role-Aware Conditional Inference for Spatiotemporal Ecosystem Carbon Flux Prediction
Mar 03, 2026Accurate prediction of terrestrial ecosystem carbon fluxes (e.g., CO$_2$, GPP, and CH$_4$) is essential for understanding the global carbon cycle and managing its impacts. However, prediction remains challenging due to strong spatiotemporal heterogeneity: ecosystem flux responses are constrained by slowly varying regime conditions, while short-term fluctuations are driven by high-frequency dynamic forcings. Most existing learning-based approaches treat environmental covariates as a homogeneous input space, implicitly assuming a global response function, which leads to brittle generalization across heterogeneous ecosystems. In this work, we propose Role-Aware Conditional Inference (RACI), a process-informed learning framework that formulates ecosystem flux prediction as a conditional inference problem. RACI employs hierarchical temporal encoding to disentangle slow regime conditioners from fast dynamic drivers, and incorporates role-aware spatial retrieval that supplies functionally similar and geographically local context for each role. By explicitly modeling these distinct functional roles, RACI enables a model to adapt its predictions across diverse environmental regimes without training separate local models or relying on fixed spatial structures. We evaluate RACI across multiple ecosystem types (wetlands and agricultural systems), carbon fluxes (CO$_2$, GPP, CH$_4$), and data sources, including both process-based simulations and observational measurements. Across all settings, RACI consistently outperforms competitive spatiotemporal baselines, demonstrating improved accuracy and spatial generalization under pronounced environmental heterogeneity.
PEST: Physics-Enhanced Swin Transformer for 3D Turbulence Simulation
Feb 09, 2026Accurate simulation of turbulent flows is fundamental to scientific and engineering applications. Direct numerical simulation (DNS) offers the highest fidelity but is computationally prohibitive, while existing data-driven alternatives struggle with stable long-horizon rollouts, physical consistency, and faithful simulation of small-scale structures. These challenges are particularly acute in three-dimensional (3D) settings, where the cubic growth of spatial degrees of freedom dramatically amplifies computational cost, memory demand, and the difficulty of capturing multi-scale interactions. To address these challenges, we propose a Physics-Enhanced Swin Transformer (PEST) for 3D turbulence simulation. PEST leverages a window-based self-attention mechanism to effectively model localized PDE interactions while maintaining computational efficiency. We introduce a frequency-domain adaptive loss that explicitly emphasizes small-scale structures, enabling more faithful simulation of high-frequency dynamics. To improve physical consistency, we incorporate Navier--Stokes residual constraints and divergence-free regularization directly into the learning objective. Extensive experiments on two representative turbulent flow configurations demonstrate that PEST achieves accurate, physically consistent, and stable autoregressive long-term simulations, outperforming existing data-driven baselines.
AgroFlux: A Spatial-Temporal Benchmark for Carbon and Nitrogen Flux Prediction in Agricultural Ecosystems
Feb 02, 2026Agroecosystem, which heavily influenced by human actions and accounts for a quarter of global greenhouse gas emissions (GHGs), plays a crucial role in mitigating global climate change and securing environmental sustainability. However, we can't manage what we can't measure. Accurately quantifying the pools and fluxes in the carbon, nutrient, and water nexus of the agroecosystem is therefore essential for understanding the underlying drivers of GHG and developing effective mitigation strategies. Conventional approaches like soil sampling, process-based models, and black-box machine learning models are facing challenges such as data sparsity, high spatiotemporal heterogeneity, and complex subsurface biogeochemical and physical processes. Developing new trustworthy approaches such as AI-empowered models, will require the AI-ready benchmark dataset and outlined protocols, which unfortunately do not exist. In this work, we introduce a first-of-its-kind spatial-temporal agroecosystem GHG benchmark dataset that integrates physics-based model simulations from Ecosys and DayCent with real-world observations from eddy covariance flux towers and controlled-environment facilities. We evaluate the performance of various sequential deep learning models on carbon and nitrogen flux prediction, including LSTM-based models, temporal CNN-based model, and Transformer-based models. Furthermore, we explored transfer learning to leverage simulated data to improve the generalization of deep learning models on real-world observations. Our benchmark dataset and evaluation framework contribute to the development of more accurate and scalable AI-driven agroecosystem models, advancing our understanding of ecosystem-climate interactions.
Learning PDE Solvers with Physics and Data: A Unifying View of Physics-Informed Neural Networks and Neural Operators
Jan 20, 2026Partial differential equations (PDEs) are central to scientific modeling. Modern workflows increasingly rely on learning-based components to support model reuse, inference, and integration across large computational processes. Despite the emergence of various physics-aware data-driven approaches, the field still lacks a unified perspective to uncover their relationships, limitations, and appropriate roles in scientific workflows. To this end, we propose a unifying perspective to place two dominant paradigms: Physics-Informed Neural Networks (PINNs) and Neural Operators (NOs), within a shared design space. We organize existing methods from three fundamental dimensions: what is learned, how physical structures are integrated into the learning process, and how the computational load is amortized across problem instances. In this way, many challenges can be best understood as consequences of these structural properties of learning PDEs. By analyzing advances through this unifying view, our survey aims to facilitate the development of reliable learning-based PDE solvers and catalyze a synthesis of physics and data.
Accelerating MHC-II Epitope Discovery via Multi-Scale Prediction in Antigen Presentation
Dec 16, 2025

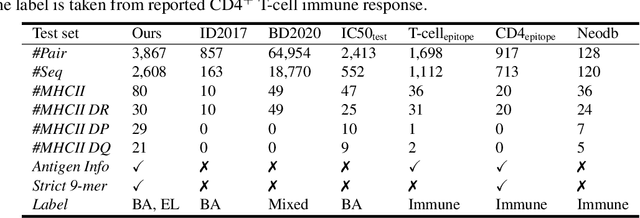
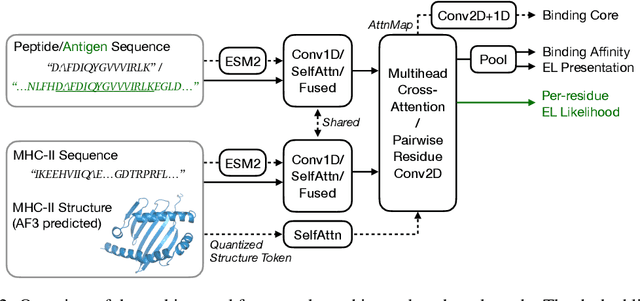
Antigenic epitope presented by major histocompatibility complex II (MHC-II) proteins plays an essential role in immunotherapy. However, compared to the more widely studied MHC-I in computational immunotherapy, the study of MHC-II antigenic epitope poses significantly more challenges due to its complex binding specificity and ambiguous motif patterns. Consequently, existing datasets for MHC-II interactions are smaller and less standardized than those available for MHC-I. To address these challenges, we present a well-curated dataset derived from the Immune Epitope Database (IEDB) and other public sources. It not only extends and standardizes existing peptide-MHC-II datasets, but also introduces a novel antigen-MHC-II dataset with richer biological context. Leveraging this dataset, we formulate three major machine learning (ML) tasks of peptide binding, peptide presentation, and antigen presentation, which progressively capture the broader biological processes within the MHC-II antigen presentation pathway. We further employ a multi-scale evaluation framework to benchmark existing models, along with a comprehensive analysis over various modeling designs to this problem with a modular framework. Overall, this work serves as a valuable resource for advancing computational immunotherapy, providing a foundation for future research in ML guided epitope discovery and predictive modeling of immune responses.
GREAT: Generalizable Representation Enhancement via Auxiliary Transformations for Zero-Shot Environmental Prediction
Nov 17, 2025Environmental modeling faces critical challenges in predicting ecosystem dynamics across unmonitored regions due to limited and geographically imbalanced observation data. This challenge is compounded by spatial heterogeneity, causing models to learn spurious patterns that fit only local data. Unlike conventional domain generalization, environmental modeling must preserve invariant physical relationships and temporal coherence during augmentation. In this paper, we introduce Generalizable Representation Enhancement via Auxiliary Transformations (GREAT), a framework that effectively augments available datasets to improve predictions in completely unseen regions. GREAT guides the augmentation process to ensure that the original governing processes can be recovered from the augmented data, and the inclusion of the augmented data leads to improved model generalization. Specifically, GREAT learns transformation functions at multiple layers of neural networks to augment both raw environmental features and temporal influence. They are refined through a novel bi-level training process that constrains augmented data to preserve key patterns of the original source data. We demonstrate GREAT's effectiveness on stream temperature prediction across six ecologically diverse watersheds in the eastern U.S., each containing multiple stream segments. Experimental results show that GREAT significantly outperforms existing methods in zero-shot scenarios. This work provides a practical solution for environmental applications where comprehensive monitoring is infeasible.
Geo-Aware Models for Stream Temperature Prediction across Different Spatial Regions and Scales
Oct 10, 2025Understanding environmental ecosystems is vital for the sustainable management of our planet. However,existing physics-based and data-driven models often fail to generalize to varying spatial regions and scales due to the inherent data heterogeneity presented in real environmental ecosystems. This generalization issue is further exacerbated by the limited observation samples available for model training. To address these issues, we propose Geo-STARS, a geo-aware spatio-temporal modeling framework for predicting stream water temperature across different watersheds and spatial scales. The major innovation of Geo-STARS is the introduction of geo-aware embedding, which leverages geographic information to explicitly capture shared principles and patterns across spatial regions and scales. We further integrate the geo-aware embedding into a gated spatio-temporal graph neural network. This design enables the model to learn complex spatial and temporal patterns guided by geographic and hydrological context, even with sparse or no observational data. We evaluate Geo-STARS's efficacy in predicting stream water temperature, which is a master factor for water quality. Using real-world datasets spanning 37 years across multiple watersheds along the eastern coast of the United States, Geo-STARS demonstrates its superior generalization performance across both regions and scales, outperforming state-of-the-art baselines. These results highlight the promise of Geo-STARS for scalable, data-efficient environmental monitoring and decision-making.
Learning to Retrieve for Environmental Knowledge Discovery: An Augmentation-Adaptive Self-Supervised Learning Framework
Sep 18, 2025The discovery of environmental knowledge depends on labeled task-specific data, but is often constrained by the high cost of data collection. Existing machine learning approaches usually struggle to generalize in data-sparse or atypical conditions. To this end, we propose an Augmentation-Adaptive Self-Supervised Learning (A$^2$SL) framework, which retrieves relevant observational samples to enhance modeling of the target ecosystem. Specifically, we introduce a multi-level pairwise learning loss to train a scenario encoder that captures varying degrees of similarity among scenarios. These learned similarities drive a retrieval mechanism that supplements a target scenario with relevant data from different locations or time periods. Furthermore, to better handle variable scenarios, particularly under atypical or extreme conditions where traditional models struggle, we design an augmentation-adaptive mechanism that selectively enhances these scenarios through targeted data augmentation. Using freshwater ecosystems as a case study, we evaluate A$^2$SL in modeling water temperature and dissolved oxygen dynamics in real-world lakes. Experimental results show that A$^2$SL significantly improves predictive accuracy and enhances robustness in data-scarce and atypical scenarios. Although this study focuses on freshwater ecosystems, the A$^2$SL framework offers a broadly applicable solution in various scientific domains.
Unveiling Confirmation Bias in Chain-of-Thought Reasoning
Jun 14, 2025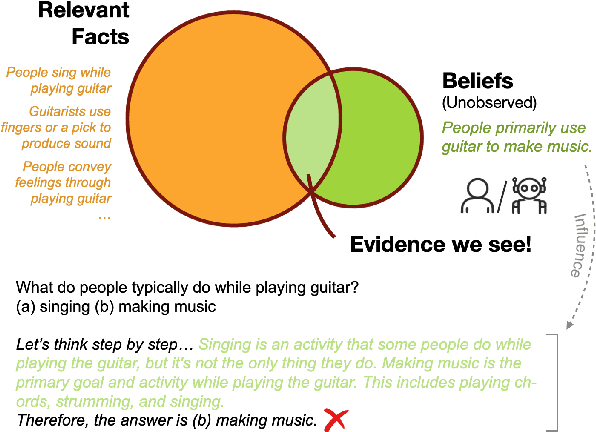
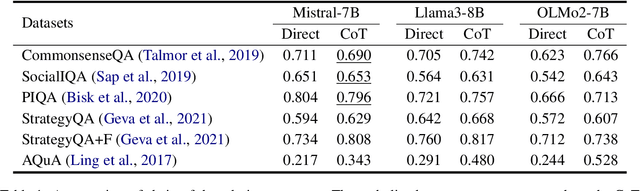
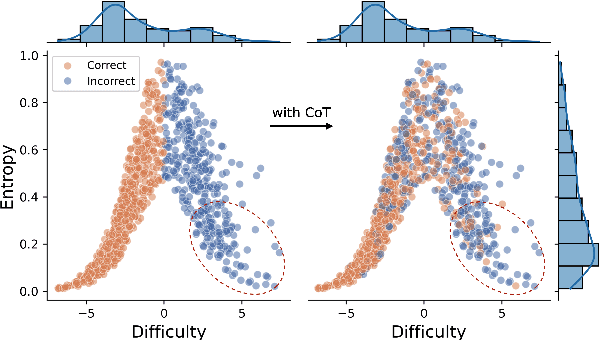
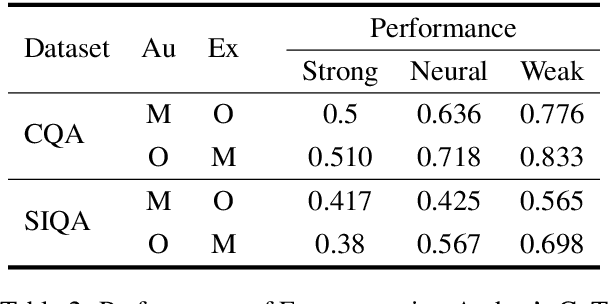
Chain-of-thought (CoT) prompting has been widely adopted to enhance the reasoning capabilities of large language models (LLMs). However, the effectiveness of CoT reasoning is inconsistent across tasks with different reasoning types. This work presents a novel perspective to understand CoT behavior through the lens of \textit{confirmation bias} in cognitive psychology. Specifically, we examine how model internal beliefs, approximated by direct question-answering probabilities, affect both reasoning generation ($Q \to R$) and reasoning-guided answer prediction ($QR \to A$) in CoT. By decomposing CoT into a two-stage process, we conduct a thorough correlation analysis in model beliefs, rationale attributes, and stage-wise performance. Our results provide strong evidence of confirmation bias in LLMs, such that model beliefs not only skew the reasoning process but also influence how rationales are utilized for answer prediction. Furthermore, the interplay between task vulnerability to confirmation bias and the strength of beliefs also provides explanations for CoT effectiveness across reasoning tasks and models. Overall, this study provides a valuable insight for the needs of better prompting strategies that mitigate confirmation bias to enhance reasoning performance. Code is available at \textit{https://github.com/yuewan2/biasedcot}.