 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Guided Foundation Model for Scientific Discovery: An Application to Aquatic Science
Feb 10, 2025Physics-guided machine learning (PGML) has become a prevalent approach in studying scientific systems due to its ability to integrate scientific theories for enhancing machine learning (ML) models. However, most PGML approaches are tailored to isolated and relatively simple tasks, which limits their applicability to complex systems involving multiple interacting processes and numerous influencing features. In this paper, we propose a \textit{\textbf{P}hysics-\textbf{G}uided \textbf{F}oundation \textbf{M}odel (\textbf{PGFM})} that combines pre-trained ML models and physics-based models and leverages their complementary strengths to improve the modeling of multiple coupled processes. To effectively conduct pre-training, we construct a simulated environmental system that encompasses a wide range of influencing features and various simulated variables generated by physics-based models. The model is pre-trained in this system to adaptively select important feature interactions guided by multi-task objectives. We then fine-tune the model for each specific task using true observations, while maintaining consistency with established physical theories, such as the principles of mass and energy conservation. We demonstrate the effectiveness of this methodology in modeling water temperature and dissolved oxygen dynamics in real-world lakes. The proposed PGFM is also broadly applicable to a range of scientific fields where physics-based models are being used.
Spatiotemporal Classification with limited labels using Constrained Clustering for large datasets
Oct 14, 2022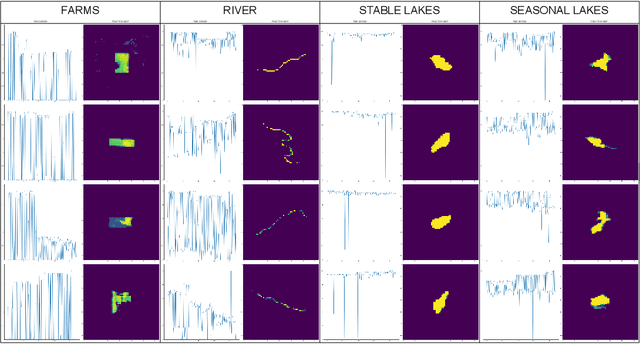

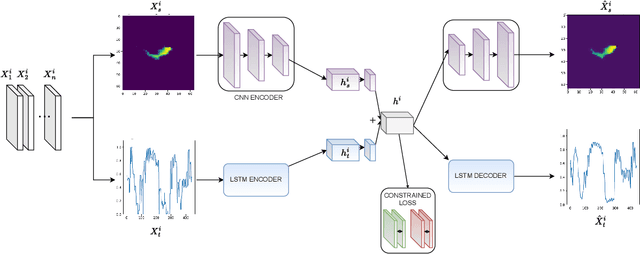

Creating separable representations via representation learning and clustering is critical in analyzing large unstructured datasets with only a few labels. Separable representations can lead to supervised models with better classification capabilities and additionally aid in generating new labeled samples. Most unsupervised and semisupervised methods to analyze large datasets do not leverage the existing small amounts of labels to get better representations. In this paper, we propose a spatiotemporal clustering paradigm that uses spatial and temporal features combined with a constrained loss to produce separable representations. We show the working of this method on the newly published dataset ReaLSAT, a dataset of surface water dynamics for over 680,000 lakes across the world, making it an essential dataset in terms of ecology and sustainability. Using this large unlabelled dataset, we first show how a spatiotemporal representation is better compared to just spatial or temporal representation. We then show how we can learn even better representation using a constrained loss with few labels. We conclude by showing how our method, using few labels, can pick out new labeled samples from the unlabeled data, which can be used to augment supervised methods leading to better classification.