 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Conditional Multi-Task Learning for Streamflow Modeling
Oct 18, 2024Streamflow, vital for water resource management, is governed by complex hydrological systems involving intermediate processes driven by meteorological forces. While deep learning models have achieved state-of-the-art results of streamflow prediction, their end-to-end single-task learning approach often fails to capture the causal relationships within these systems. To address this, we propose Hierarchical Conditional Multi-Task Learning (HCMTL), a hierarchical approach that jointly models soil water and snowpack processes based on their causal connections to streamflow. HCMTL utilizes task embeddings to connect network modules, enhancing flexibility and expressiveness while capturing unobserved processes beyond soil water and snowpack. It also incorporates the Conditional Mini-Batch strategy to improve long time series modeling. We compare HCMTL with five baselines on a global dataset. HCMTL's superior performance across hundreds of drainage basins over extended periods shows that integrating domain-specific causal knowledge into deep learning enhances both prediction accuracy and interpretability. This is essential for advancing our understanding of complex hydrological systems and supporting efficient water resource management to mitigate natural disasters like droughts and floods.
Towards a Knowledge guided Multimodal Foundation Model for Spatio-Temporal Remote Sensing Applications
Jul 29, 2024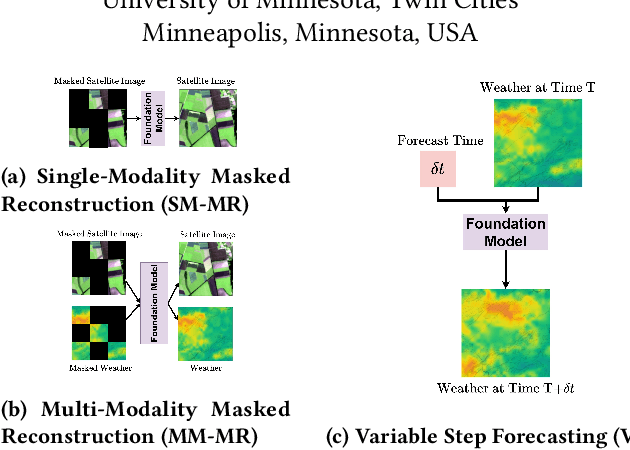
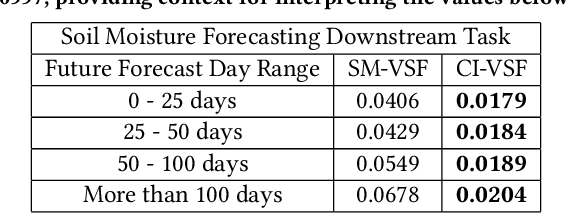
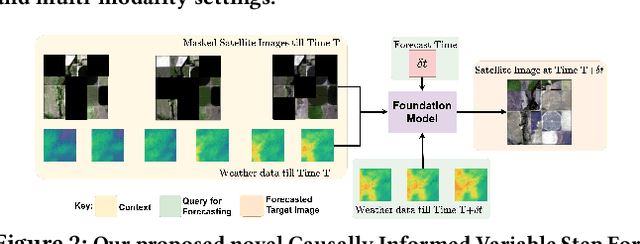
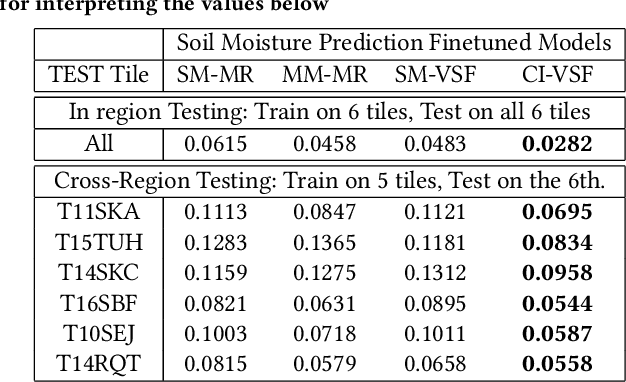
In recent years, there is increased interest in foundation models for geoscience due to vast amount of earth observing satellite imagery. Existing remote sensing foundation models make use of the various sources of spectral imagery to create large models pretrained on masked reconstruction task. The embeddings from these foundation models are then used for various downstream remote sensing applications. In this paper we propose a foundational modeling framework for remote sensing geoscience applications, that goes beyond these traditional single modality masked autoencoder family of foundation models. This framework leverages the knowledge guided principles that the spectral imagery captures the impact of the physical drivers on the environmental system, and that the relationship between them is governed by the characteristics of the system. Specifically, our method, called MultiModal Variable Step Forecasting (MM-VSF), uses mutlimodal data (spectral imagery and weather) as its input and a variable step forecasting task as its pretraining objective. In our evaluation we show forecasting of satellite imagery using weather can be used as an effective pretraining task for foundation models. We further show the effectiveness of the embeddings from MM-VSF on the downstream task of pixel wise crop mapping, when compared with a model trained in the traditional setting of single modality input and masked reconstruction based pretraining.
Combining Satellite and Weather Data for Crop Type Mapping: An Inverse Modelling Approach
Jan 29, 2024



Accurate and timely crop mapping is essential for yield estimation, insurance claims, and conservation efforts. Over the years, many successful machine learning models for crop mapping have been developed that use just the multi-spectral imagery from satellites to predict crop type over the area of interest. However, these traditional methods do not account for the physical processes that govern crop growth. At a high level, crop growth can be envisioned as physical parameters, such as weather and soil type, acting upon the plant leading to crop growth which can be observed via satellites. In this paper, we propose Weather-based Spatio-Temporal segmentation network with ATTention (WSTATT), a deep learning model that leverages this understanding of crop growth by formulating it as an inverse model that combines weather (Daymet) and satellite imagery (Sentinel-2) to generate accurate crop maps. We show that our approach provides significant improvements over existing algorithms that solely rely on spectral imagery by comparing segmentation maps and F1 classification scores. Furthermore, effective use of attention in WSTATT architecture enables detection of crop types earlier in the season (up to 5 months in advance), which is very useful for improving food supply projections. We finally discuss the impact of weather by correlating our results with crop phenology to show that WSTATT is able to capture physical properties of crop growth.
Task Aware Modulation using Representation Learning: An Approach for Few Shot Learning in Heterogeneous Systems
Oct 07, 2023



We present a Task-aware modulation using Representation Learning (TAM-RL) framework that enhances personalized predictions in few-shot settings for heterogeneous systems when individual task characteristics are not known. TAM-RL extracts embeddings representing the actual inherent characteristics of these entities and uses these characteristics to personalize the predictions for each entity/task. Using real-world hydrological and flux tower benchmark data sets, we show that TAM-RL can significantly outperform existing baseline approaches such as MAML and multi-modal MAML (MMAML) while being much faster and simpler to train due to less complexity. Specifically, TAM-RL eliminates the need for sensitive hyper-parameters like inner loop steps and inner loop learning rate, which are crucial for model convergence in MAML, MMAML. We further present an empirical evaluation via synthetic data to explore the impact of heterogeneity amongst the entities on the relative performance of MAML, MMAML, and TAM-RL. We show that TAM-RL significantly improves predictive performance for cases where it is possible to learn distinct representations for different tasks.
Message Propagation Through Time: An Algorithm for Sequence Dependency Retention in Time Series Modeling
Sep 28, 2023



Time series modeling, a crucial area in science, often encounters challenges when training Machine Learning (ML) models like Recurrent Neural Networks (RNNs) using the conventional mini-batch training strategy that assumes independent and identically distributed (IID) samples and initializes RNNs with zero hidden states. The IID assumption ignores temporal dependencies among samples, resulting in poor performance. This paper proposes the Message Propagation Through Time (MPTT) algorithm to effectively incorporate long temporal dependencies while preserving faster training times relative to the stateful solutions. MPTT utilizes two memory modules to asynchronously manage initial hidden states for RNNs, fostering seamless information exchange between samples and allowing diverse mini-batches throughout epochs. MPTT further implements three policies to filter outdated and preserve essential information in the hidden states to generate informative initial hidden states for RNNs, facilitating robust training. Experimental results demonstrate that MPTT outperforms seven strategies on four climate datasets with varying levels of temporal dependencies.
Entity Aware Modelling: A Survey
Feb 16, 2023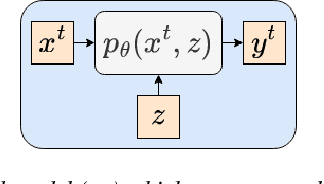
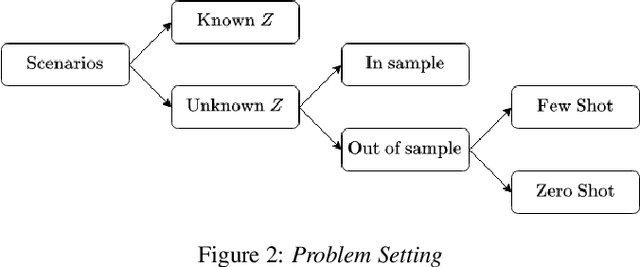
Personalized prediction of responses for individual entities caused by external drivers is vital across many disciplines. Recent machine learning (ML) advances have led to new state-of-the-art response prediction models. Models built at a population level often lead to sub-optimal performance in many personalized prediction settings due to heterogeneity in data across entities (tasks). In personalized prediction, the goal is to incorporate inherent characteristics of different entities to improve prediction performance. In this survey, we focus on the recent developments in the ML community for such entity-aware modeling approaches. ML algorithms often modulate the network using these entity characteristics when they are readily available. However, these entity characteristics are not readily available in many real-world scenarios, and different ML methods have been proposed to infer these characteristics from the data. In this survey, we have organized the current literature on entity-aware modeling based on the availability of these characteristics as well as the amount of training data. We highlight how recent innovations in other disciplines, such as uncertainty quantification, fairness, and knowledge-guided machine learning, can improve entity-aware modeling.
Mini-Batch Learning Strategies for modeling long term temporal dependencies: A study in environmental applications
Oct 15, 2022
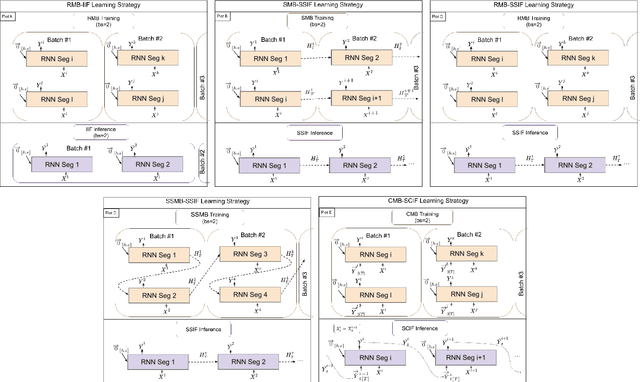
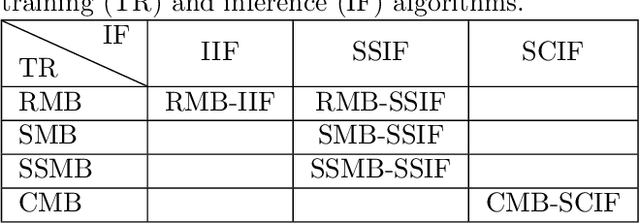
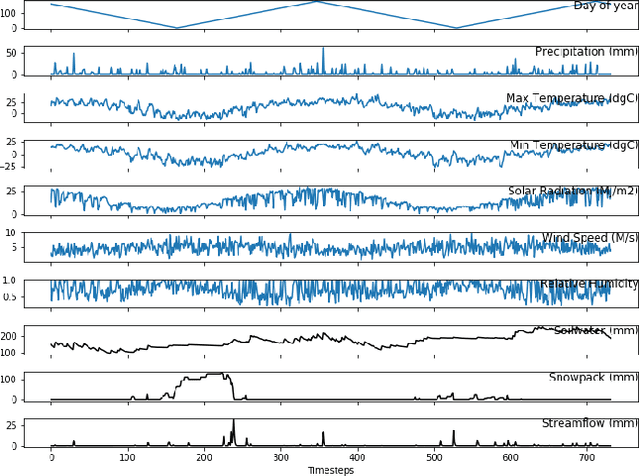
In many environmental applications, recurrent neural networks (RNNs) are often used to model physical variables with long temporal dependencies. However, due to mini-batch training, temporal relationships between training segments within the batch (intra-batch) as well as between batches (inter-batch) are not considered, which can lead to limited performance. Stateful RNNs aim to address this issue by passing hidden states between batches. Since Stateful RNNs ignore intra-batch temporal dependency, there exists a trade-off between training stability and capturing temporal dependency. In this paper, we provide a quantitative comparison of different Stateful RNN modeling strategies, and propose two strategies to enforce both intra- and inter-batch temporal dependency. First, we extend Stateful RNNs by defining a batch as a temporally ordered set of training segments, which enables intra-batch sharing of temporal information. While this approach significantly improves the performance, it leads to much larger training times due to highly sequential training. To address this issue, we further propose a new strategy which augments a training segment with an initial value of the target variable from the timestep right before the starting of the training segment. In other words, we provide an initial value of the target variable as additional input so that the network can focus on learning changes relative to that initial value. By using this strategy, samples can be passed in any order (mini-batch training) which significantly reduces the training time while maintaining the performance. In demonstrating our approach in hydrological modeling, we observe that the most significant gains in predictive accuracy occur when these methods are applied to state variables whose values change more slowly, such as soil water and snowpack, rather than continuously moving flux variables such as streamflow.
Spatiotemporal Classification with limited labels using Constrained Clustering for large datasets
Oct 14, 2022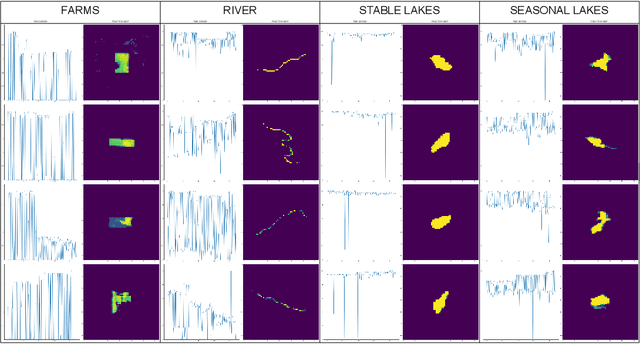

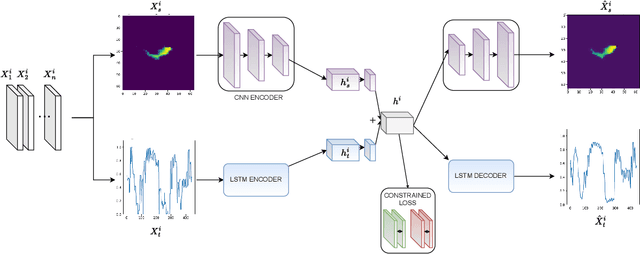

Creating separable representations via representation learning and clustering is critical in analyzing large unstructured datasets with only a few labels. Separable representations can lead to supervised models with better classification capabilities and additionally aid in generating new labeled samples. Most unsupervised and semisupervised methods to analyze large datasets do not leverage the existing small amounts of labels to get better representations. In this paper, we propose a spatiotemporal clustering paradigm that uses spatial and temporal features combined with a constrained loss to produce separable representations. We show the working of this method on the newly published dataset ReaLSAT, a dataset of surface water dynamics for over 680,000 lakes across the world, making it an essential dataset in terms of ecology and sustainability. Using this large unlabelled dataset, we first show how a spatiotemporal representation is better compared to just spatial or temporal representation. We then show how we can learn even better representation using a constrained loss with few labels. We conclude by showing how our method, using few labels, can pick out new labeled samples from the unlabeled data, which can be used to augment supervised methods leading to better classification.
Knowledge-guided Self-supervised Learning for estimating River-Basin Characteristics
Sep 14, 2021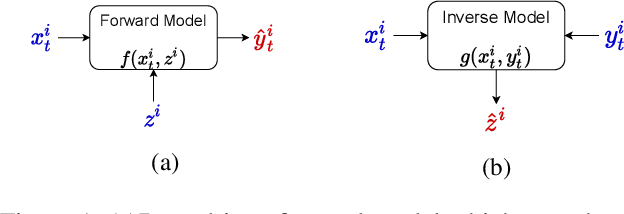

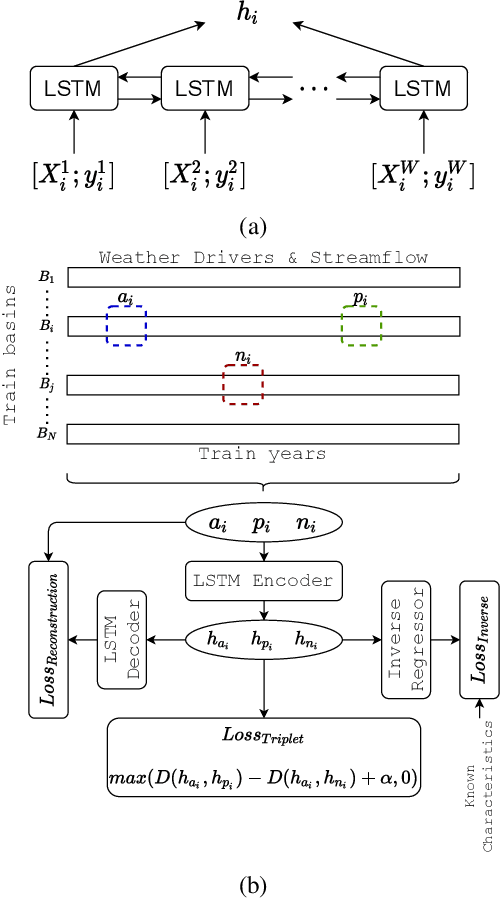
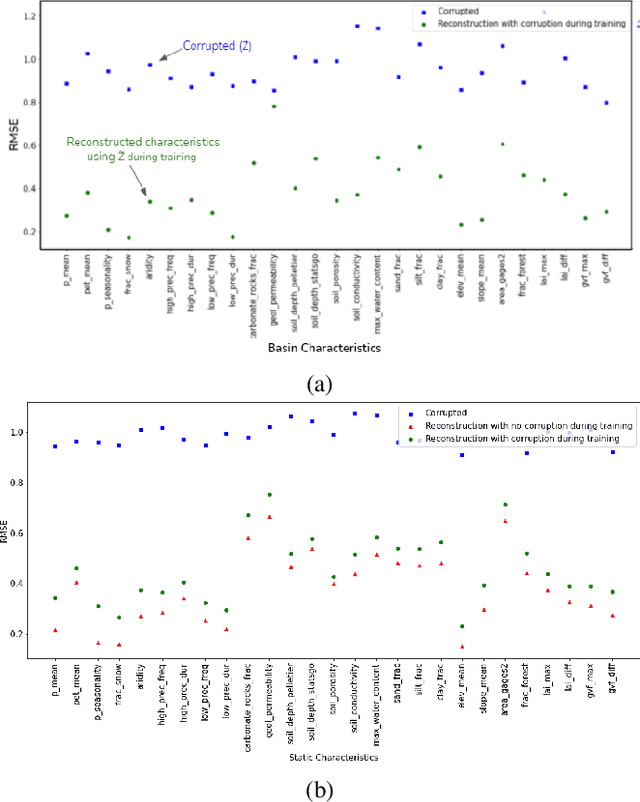
Machine Learning is being extensively used in hydrology, especially streamflow prediction of basins/watersheds. Basin characteristics are essential for modeling the rainfall-runoff response of these watersheds and therefore data-driven methods must take into account this ancillary characteristics data. However there are several limitations, namely uncertainty in the measured characteristics, partially missing characteristics for some of the basins or unknown characteristics that may not be present in the known measured set. In this paper we present an inverse model that uses a knowledge-guided self-supervised learning algorithm to infer basin characteristics using the meteorological drivers and streamflow response data. We evaluate our model on the the CAMELS dataset and the results validate its ability to reduce measurement uncertainty, impute missing characteristics, and identify unknown characteristics.
CalCROP21: A Georeferenced multi-spectral dataset of Satellite Imagery and Crop Labels
Jul 26, 2021
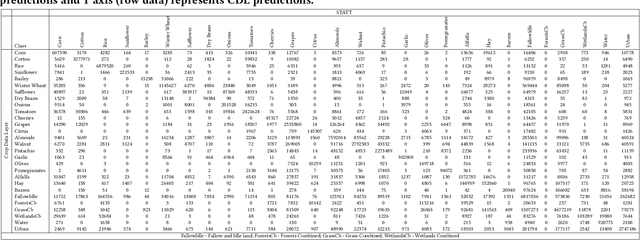
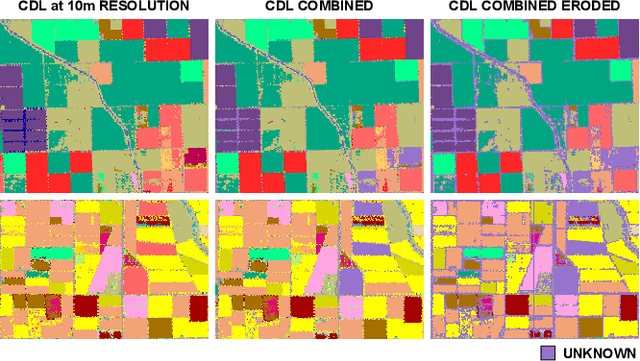
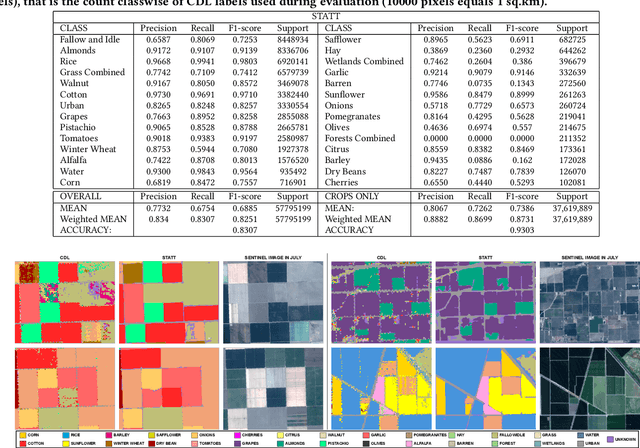
Mapping and monitoring crops is a key step towards sustainable intensification of agriculture and addressing global food security. A dataset like ImageNet that revolutionized computer vision applications can accelerate development of novel crop mapping techniques. Currently, the United States Department of Agriculture (USDA) annually releases the Cropland Data Layer (CDL) which contains crop labels at 30m resolution for the entire United States of America. While CDL is state of the art and is widely used for a number of agricultural applications, it has a number of limitations (e.g., pixelated errors, labels carried over from previous errors and absence of input imagery along with class labels). In this work, we create a new semantic segmentation benchmark dataset, which we call CalCROP21, for the diverse crops in the Central Valley region of California at 10m spatial resolution using a Google Earth Engine based robust image processing pipeline and a novel attention based spatio-temporal semantic segmentation algorithm STATT. STATT uses re-sampled (interpolated) CDL labels for training, but is able to generate a better prediction than CDL by leveraging spatial and temporal patterns in Sentinel2 multi-spectral image series to effectively capture phenologic differences amongst crops and uses attention to reduce the impact of clouds and other atmospheric disturbances. We also present a comprehensive evaluation to show that STATT has significantly better results when compared to the resampled CDL labels. We have released the dataset and the processing pipeline code for generating the benchmark dataset.