 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Guided Fair Graph Sampling for Water Temperature Prediction in River Networks
Dec 21, 2024



This work introduces a novel graph neural networks (GNNs)-based method to predict stream water temperature and reduce model bias across locations of different income and education levels. Traditional physics-based models often have limited accuracy because they are necessarily approximations of reality. Recently, there has been an increasing interest of using GNNs in modeling complex water dynamics in stream networks. Despite their promise in improving the accuracy, GNNs can bring additional model bias through the aggregation process, where node features are updated by aggregating neighboring nodes. The bias can be especially pronounced when nodes with similar sensitive attributes are frequently connected. We introduce a new method that leverages physical knowledge to represent the node influence in GNNs, and then utilizes physics-based influence to refine the selection and weights over the neighbors. The objective is to facilitate equitable treatment over different sensitive groups in the graph aggregation, which helps reduce spatial bias over locations, especially for those in underprivileged groups. The results on the Delaware River Basin demonstrate the effectiveness of the proposed method in preserving equitable performance across locations in different sensitive groups.
PAIL: Performance based Adversarial Imitation Learning Engine for Carbon Neutral Optimization
Jul 12, 2024

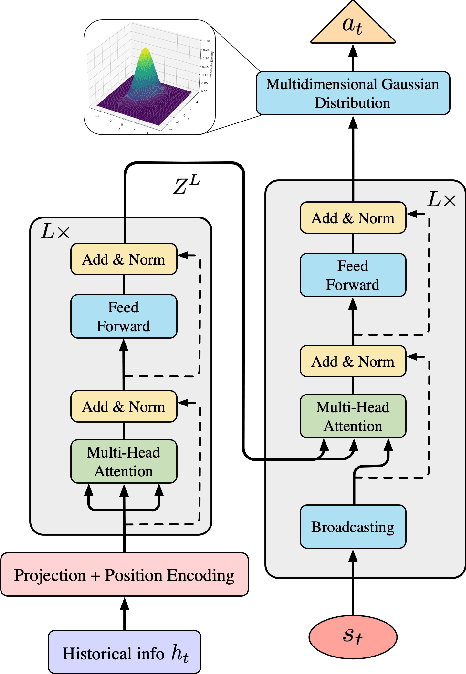
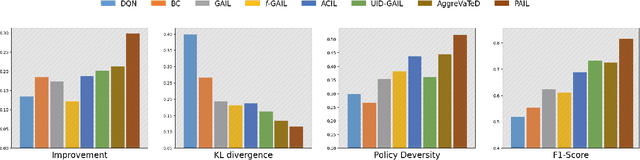
Achieving carbon neutrality within industrial operations has become increasingly imperative for sustainable development. It is both a significant challenge and a key opportunity for operational optimization in industry 4.0. In recent years, Deep Reinforcement Learning (DRL) based methods offer promising enhancements for sequential optimization processes and can be used for reducing carbon emissions. However, existing DRL methods need a pre-defined reward function to assess the impact of each action on the final sustainable development goals (SDG). In many real applications, such a reward function cannot be given in advance. To address the problem, this study proposes a Performance based Adversarial Imitation Learning (PAIL) engine. It is a novel method to acquire optimal operational policies for carbon neutrality without any pre-defined action rewards. Specifically, PAIL employs a Transformer-based policy generator to encode historical information and predict following actions within a multi-dimensional space. The entire action sequence will be iteratively updated by an environmental simulator. Then PAIL uses a discriminator to minimize the discrepancy between generated sequences and real-world samples of high SDG. In parallel, a Q-learning framework based performance estimator is designed to estimate the impact of each action on SDG. Based on these estimations, PAIL refines generated policies with the rewards from both discriminator and performance estimator. PAIL is evaluated on multiple real-world application cases and datasets. The experiment results demonstrate the effectiveness of PAIL comparing to other state-of-the-art baselines. In addition, PAIL offers meaningful interpretability for the optimization in carbon neutrality.
Referee-Meta-Learning for Fast Adaptation of Locational Fairness
Feb 20, 2024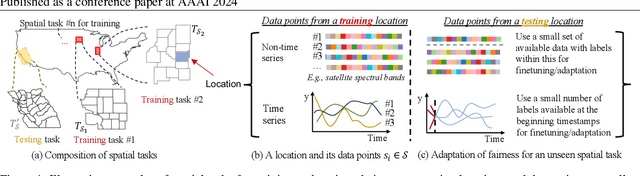
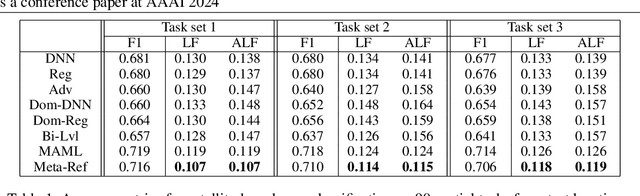
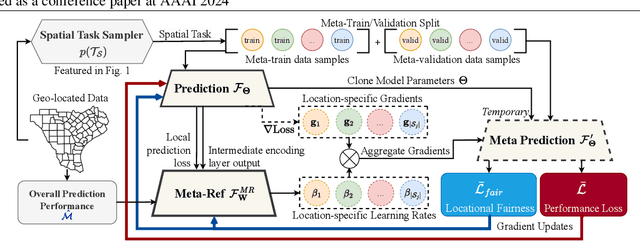
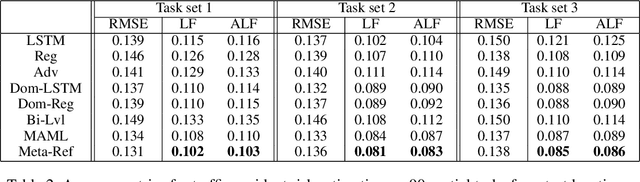
When dealing with data from distinct locations, machine learning algorithms tend to demonstrate an implicit preference of some locations over the others, which constitutes biases that sabotage the spatial fairness of the algorithm. This unfairness can easily introduce biases in subsequent decision-making given broad adoptions of learning-based solutions in practice. However, locational biases in AI are largely understudied. To mitigate biases over locations, we propose a locational meta-referee (Meta-Ref) to oversee the few-shot meta-training and meta-testing of a deep neural network. Meta-Ref dynamically adjusts the learning rates for training samples of given locations to advocate a fair performance across locations, through an explicit consideration of locational biases and the characteristics of input data. We present a three-phase training framework to learn both a meta-learning-based predictor and an integrated Meta-Ref that governs the fairness of the model. Once trained with a distribution of spatial tasks, Meta-Ref is applied to samples from new spatial tasks (i.e., regions outside the training area) to promote fairness during the fine-tune step. We carried out experiments with two case studies on crop monitoring and transportation safety, which show Meta-Ref can improve locational fairness while keeping the overall prediction quality at a similar level.
Entity Aware Modelling: A Survey
Feb 16, 2023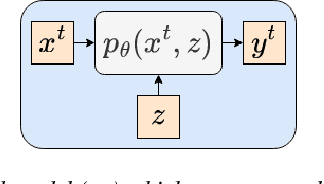
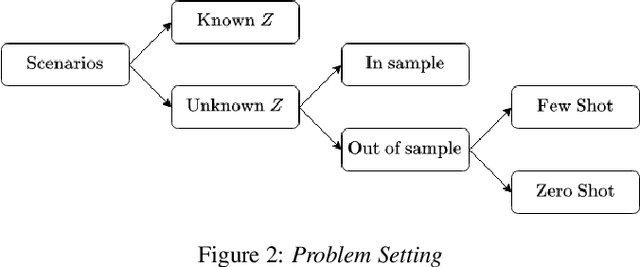
Personalized prediction of responses for individual entities caused by external drivers is vital across many disciplines. Recent machine learning (ML) advances have led to new state-of-the-art response prediction models. Models built at a population level often lead to sub-optimal performance in many personalized prediction settings due to heterogeneity in data across entities (tasks). In personalized prediction, the goal is to incorporate inherent characteristics of different entities to improve prediction performance. In this survey, we focus on the recent developments in the ML community for such entity-aware modeling approaches. ML algorithms often modulate the network using these entity characteristics when they are readily available. However, these entity characteristics are not readily available in many real-world scenarios, and different ML methods have been proposed to infer these characteristics from the data. In this survey, we have organized the current literature on entity-aware modeling based on the availability of these characteristics as well as the amount of training data. We highlight how recent innovations in other disciplines, such as uncertainty quantification, fairness, and knowledge-guided machine learning, can improve entity-aware modeling.