 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferential Analysis of Pseudo Haptic Feedback: Novel Comparative Study of Visual and Auditory Cue Integration for Psychophysical Evaluation
Oct 10, 2025Pseudo-haptics exploit carefully crafted visual or auditory cues to trick the brain into "feeling" forces that are never physically applied, offering a low-cost alternative to traditional haptic hardware. Here, we present a comparative psychophysical study that quantifies how visual and auditory stimuli combine to evoke pseudo-haptic pressure sensations on a commodity tablet. Using a Unity-based Rollball game, participants (n = 4) guided a virtual ball across three textured terrains while their finger forces were captured in real time with a Robotous RFT40 force-torque sensor. Each terrain was paired with a distinct rolling-sound profile spanning 440 Hz - 4.7 kHz, 440 Hz - 13.1 kHz, or 440 Hz - 8.9 kHz; crevice collisions triggered additional "knocking" bursts to heighten realism. Average tactile forces increased systematically with cue intensity: 0.40 N, 0.79 N and 0.88 N for visual-only trials and 0.41 N, 0.81 N and 0.90 N for audio-only trials on Terrains 1-3, respectively. Higher audio frequencies and denser visual textures both elicited stronger muscle activation, and their combination further reduced the force needed to perceive surface changes, confirming multisensory integration. These results demonstrate that consumer-grade isometric devices can reliably induce and measure graded pseudo-haptic feedback without specialized actuators, opening a path toward affordable rehabilitation tools, training simulators and assistive interfaces.
Hierarchically Disentangled Recurrent Network for Factorizing System Dynamics of Multi-scale Systems
Jul 29, 2024We present a knowledge-guided machine learning (KGML) framework for modeling multi-scale processes, and study its performance in the context of streamflow forecasting in hydrology. Specifically, we propose a novel hierarchical recurrent neural architecture that factorizes the system dynamics at multiple temporal scales and captures their interactions. This framework consists of an inverse and a forward model. The inverse model is used to empirically resolve the system's temporal modes from data (physical model simulations, observed data, or a combination of them from the past), and these states are then used in the forward model to predict streamflow. In a hydrological system, these modes can represent different processes, evolving at different temporal scales (e.g., slow: groundwater recharge and baseflow vs. fast: surface runoff due to extreme rainfall). A key advantage of our framework is that once trained, it can incorporate new observations into the model's context (internal state) without expensive optimization approaches (e.g., EnKF) that are traditionally used in physical sciences for data assimilation. Experiments with several river catchments from the NWS NCRFC region show the efficacy of this ML-based data assimilation framework compared to standard baselines, especially for basins that have a long history of observations. Even for basins that have a shorter observation history, we present two orthogonal strategies of training our FHNN framework: (a) using simulation data from imperfect simulations and (b) using observation data from multiple basins to build a global model. We show that both of these strategies (that can be used individually or together) are highly effective in mitigating the lack of training data. The improvement in forecast accuracy is particularly noteworthy for basins where local models perform poorly because of data sparsity.
Domain Adaptation for Sustainable Soil Management using Causal and Contrastive Constraint Minimization
Jan 13, 2024Monitoring organic matter is pivotal for maintaining soil health and can help inform sustainable soil management practices. While sensor-based soil information offers higher-fidelity and reliable insights into organic matter changes, sampling and measuring sensor data is cost-prohibitive. We propose a multi-modal, scalable framework that can estimate organic matter from remote sensing data, a more readily available data source while leveraging sparse soil information for improving generalization. Using the sensor data, we preserve underlying causal relations among sensor attributes and organic matter. Simultaneously we leverage inherent structure in the data and train the model to discriminate among domains using contrastive learning. This causal and contrastive constraint minimization ensures improved generalization and adaptation to other domains. We also shed light on the interpretability of the framework by identifying attributes that are important for improving generalization. Identifying these key soil attributes that affect organic matter will aid in efforts to standardize data collection efforts.
Knowledge Guided Representation Learning and Causal Structure Learning in Soil Science
Jun 15, 2023



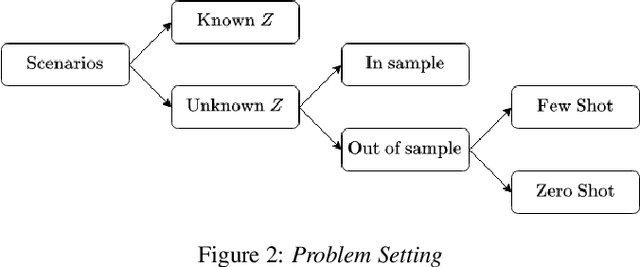
An improved understanding of soil can enable more sustainable land-use practices. Nevertheless, soil is called a complex, living medium due to the complex interaction of different soil processes that limit our understanding of soil. Process-based models and analyzing observed data provide two avenues for improving our understanding of soil processes. Collecting observed data is cost-prohibitive but reflects real-world behavior, while process-based models can be used to generate ample synthetic data which may not be representative of reality. We propose a framework, knowledge-guided representation learning, and causal structure learning (KGRCL), to accelerate scientific discoveries in soil science. The framework improves representation learning for simulated soil processes via conditional distribution matching with observed soil processes. Simultaneously, the framework leverages both observed and simulated data to learn a causal structure among the soil processes. The learned causal graph is more representative of ground truth than other graphs generated from other causal discovery methods. Furthermore, the learned causal graph is leveraged in a supervised learning setup to predict the impact of fertilizer use and changing weather on soil carbon. We present the results in five different locations to show the improvement in the prediction performance in out-of-sample and few-shots setting.
Entity Aware Modelling: A Survey
Feb 16, 2023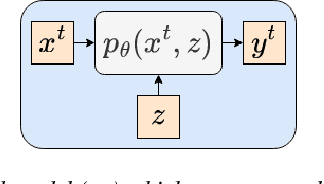
Personalized prediction of responses for individual entities caused by external drivers is vital across many disciplines. Recent machine learning (ML) advances have led to new state-of-the-art response prediction models. Models built at a population level often lead to sub-optimal performance in many personalized prediction settings due to heterogeneity in data across entities (tasks). In personalized prediction, the goal is to incorporate inherent characteristics of different entities to improve prediction performance. In this survey, we focus on the recent developments in the ML community for such entity-aware modeling approaches. ML algorithms often modulate the network using these entity characteristics when they are readily available. However, these entity characteristics are not readily available in many real-world scenarios, and different ML methods have been proposed to infer these characteristics from the data. In this survey, we have organized the current literature on entity-aware modeling based on the availability of these characteristics as well as the amount of training data. We highlight how recent innovations in other disciplines, such as uncertainty quantification, fairness, and knowledge-guided machine learning, can improve entity-aware modeling.
Causal Modeling of Soil Processes for Improved Generalization
Nov 10, 2022
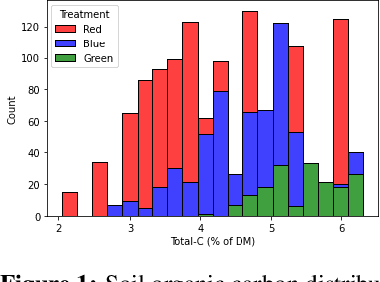
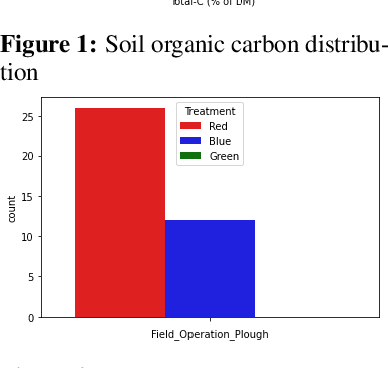
Measuring and monitoring soil organic carbon is critical for agricultural productivity and for addressing critical environmental problems. Soil organic carbon not only enriches nutrition in soil, but also has a gamut of co-benefits such as improving water storage and limiting physical erosion. Despite a litany of work in soil organic carbon estimation, current approaches do not generalize well across soil conditions and management practices. We empirically show that explicit modeling of cause-and-effect relationships among the soil processes improves the out-of-distribution generalizability of prediction models. We provide a comparative analysis of soil organic carbon estimation models where the skeleton is estimated using causal discovery methods. Our framework provide an average improvement of 81% in test mean squared error and 52% in test mean absolute error.
Probabilistic Inverse Modeling: An Application in Hydrology
Oct 12, 2022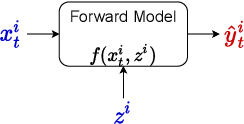
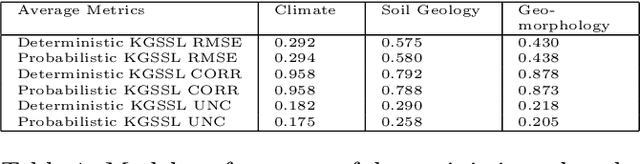
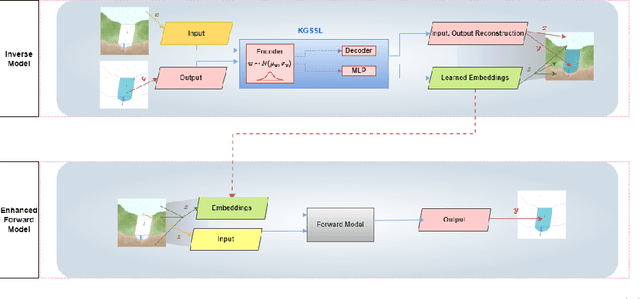
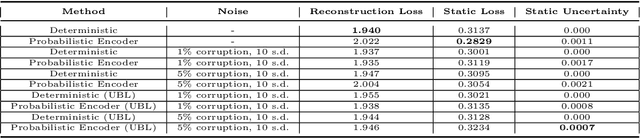
The astounding success of these methods has made it imperative to obtain more explainable and trustworthy estimates from these models. In hydrology, basin characteristics can be noisy or missing, impacting streamflow prediction. For solving inverse problems in such applications, ensuring explainability is pivotal for tackling issues relating to data bias and large search space. We propose a probabilistic inverse model framework that can reconstruct robust hydrology basin characteristics from dynamic input weather driver and streamflow response data. We address two aspects of building more explainable inverse models, uncertainty estimation and robustness. This can help improve the trust of water managers, handling of noisy data and reduce costs. We propose uncertainty based learning method that offers 6\% improvement in $R^2$ for streamflow prediction (forward modeling) from inverse model inferred basin characteristic estimates, 17\% reduction in uncertainty (40\% in presence of noise) and 4\% higher coverage rate for basin characteristics.
Approximate Bayesian Computation for Physical Inverse Modeling
Nov 26, 2021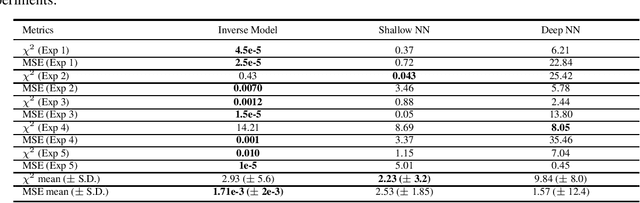
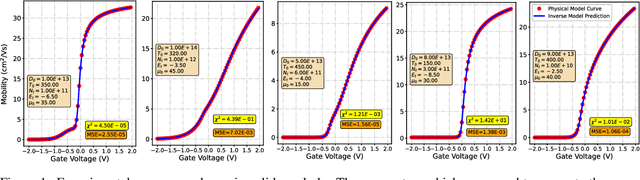
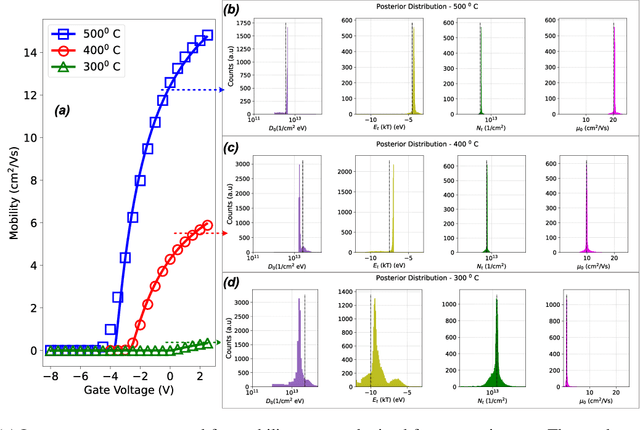
Semiconductor device models are essential to understand the charge transport in thin film transistors (TFTs). Using these TFT models to draw inference involves estimating parameters used to fit to the experimental data. These experimental data can involve extracted charge carrier mobility or measured current. Estimating these parameters help us draw inferences about device performance. Fitting a TFT model for a given experimental data using the model parameters relies on manual fine tuning of multiple parameters by human experts. Several of these parameters may have confounding effects on the experimental data, making their individual effect extraction a non-intuitive process during manual tuning. To avoid this convoluted process, we propose a new method for automating the model parameter extraction process resulting in an accurate model fitting. In this work, model choice based approximate Bayesian computation (aBc) is used for generating the posterior distribution of the estimated parameters using observed mobility at various gate voltage values. Furthermore, it is shown that the extracted parameters can be accurately predicted from the mobility curves using gradient boosted trees. This work also provides a comparative analysis of the proposed framework with fine-tuned neural networks wherein the proposed framework is shown to perform better.