 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRLTHF: Targeted Human Feedback for LLM Alignment
Feb 19, 2025



Fine-tuning large language models (LLMs) to align with user preferences is challenging due to the high cost of quality human annotations in Reinforcement Learning from Human Feedback (RLHF) and the generalizability limitations of AI Feedback. To address these challenges, we propose RLTHF, a human-AI hybrid framework that combines LLM-based initial alignment with selective human annotations to achieve full-human annotation alignment with minimal effort. RLTHF identifies hard-to-annotate samples mislabeled by LLMs using a reward model's reward distribution and iteratively enhances alignment by integrating strategic human corrections while leveraging LLM's correctly labeled samples. Evaluations on HH-RLHF and TL;DR datasets show that RLTHF reaches full-human annotation-level alignment with only 6-7% of the human annotation effort. Furthermore, models trained on RLTHF's curated datasets for downstream tasks outperform those trained on fully human-annotated datasets, underscoring the effectiveness of RLTHF's strategic data curation.
Enabling Adoption of Regenerative Agriculture through Soil Carbon Copilots
Nov 25, 2024



Mitigating climate change requires transforming agriculture to minimize environ mental impact and build climate resilience. Regenerative agricultural practices enhance soil organic carbon (SOC) levels, thus improving soil health and sequestering carbon. A challenge to increasing regenerative agriculture practices is cheaply measuring SOC over time and understanding how SOC is affected by regenerative agricultural practices and other environmental factors and farm management practices. To address this challenge, we introduce an AI-driven Soil Organic Carbon Copilot that automates the ingestion of complex multi-resolution, multi-modal data to provide large-scale insights into soil health and regenerative practices. Our data includes extreme weather event data (e.g., drought and wildfire incidents), farm management data (e.g., cropland information and tillage predictions), and SOC predictions. We find that integrating public data and specialized models enables large-scale, localized analysis for sustainable agriculture. In comparisons of agricultural practices across California counties, we find evidence that diverse agricultural activity may mitigate the negative effects of tillage; and that while extreme weather conditions heavily affect SOC, composting may mitigate SOC loss. Finally, implementing role-specific personas empowers agronomists, farm consultants, policymakers, and other stakeholders to implement evidence-based strategies that promote sustainable agriculture and build climate resilience.
RAG vs Fine-tuning: Pipelines, Tradeoffs, and a Case Study on Agriculture
Jan 30, 2024There are two common ways in which developers are incorporating proprietary and domain-specific data when building applications of Large Language Models (LLMs): Retrieval-Augmented Generation (RAG) and Fine-Tuning. RAG augments the prompt with the external data, while fine-Tuning incorporates the additional knowledge into the model itself. However, the pros and cons of both approaches are not well understood. In this paper, we propose a pipeline for fine-tuning and RAG, and present the tradeoffs of both for multiple popular LLMs, including Llama2-13B, GPT-3.5, and GPT-4. Our pipeline consists of multiple stages, including extracting information from PDFs, generating questions and answers, using them for fine-tuning, and leveraging GPT-4 for evaluating the results. We propose metrics to assess the performance of different stages of the RAG and fine-Tuning pipeline. We conduct an in-depth study on an agricultural dataset. Agriculture as an industry has not seen much penetration of AI, and we study a potentially disruptive application - what if we could provide location-specific insights to a farmer? Our results show the effectiveness of our dataset generation pipeline in capturing geographic-specific knowledge, and the quantitative and qualitative benefits of RAG and fine-tuning. We see an accuracy increase of over 6 p.p. when fine-tuning the model and this is cumulative with RAG, which increases accuracy by 5 p.p. further. In one particular experiment, we also demonstrate that the fine-tuned model leverages information from across geographies to answer specific questions, increasing answer similarity from 47% to 72%. Overall, the results point to how systems built using LLMs can be adapted to respond and incorporate knowledge across a dimension that is critical for a specific industry, paving the way for further applications of LLMs in other industrial domains.
Domain Adaptation for Sustainable Soil Management using Causal and Contrastive Constraint Minimization
Jan 13, 2024Monitoring organic matter is pivotal for maintaining soil health and can help inform sustainable soil management practices. While sensor-based soil information offers higher-fidelity and reliable insights into organic matter changes, sampling and measuring sensor data is cost-prohibitive. We propose a multi-modal, scalable framework that can estimate organic matter from remote sensing data, a more readily available data source while leveraging sparse soil information for improving generalization. Using the sensor data, we preserve underlying causal relations among sensor attributes and organic matter. Simultaneously we leverage inherent structure in the data and train the model to discriminate among domains using contrastive learning. This causal and contrastive constraint minimization ensures improved generalization and adaptation to other domains. We also shed light on the interpretability of the framework by identifying attributes that are important for improving generalization. Identifying these key soil attributes that affect organic matter will aid in efforts to standardize data collection efforts.
The Age of Synthetic Realities: Challenges and Opportunities
Jun 09, 2023



Synthetic realities are digital creations or augmentations that are contextually generated through the use of Artificial Intelligence (AI) methods, leveraging extensive amounts of data to construct new narratives or realities, regardless of the intent to deceive. In this paper, we delve into the concept of synthetic realities and their implications for Digital Forensics and society at large within the rapidly advancing field of AI. We highlight the crucial need for the development of forensic techniques capable of identifying harmful synthetic creations and distinguishing them from reality. This is especially important in scenarios involving the creation and dissemination of fake news, disinformation, and misinformation. Our focus extends to various forms of media, such as images, videos, audio, and text, as we examine how synthetic realities are crafted and explore approaches to detecting these malicious creations. Additionally, we shed light on the key research challenges that lie ahead in this area. This study is of paramount importance due to the rapid progress of AI generative techniques and their impact on the fundamental principles of Forensic Science.
Content-Based Detection of Temporal Metadata Manipulation
Mar 08, 2021
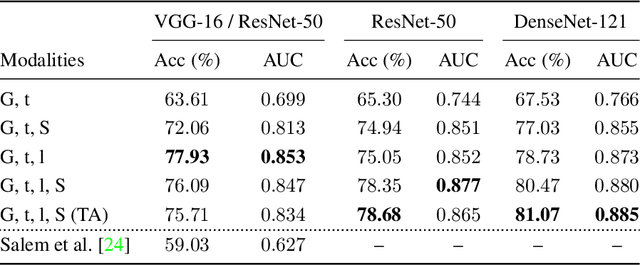
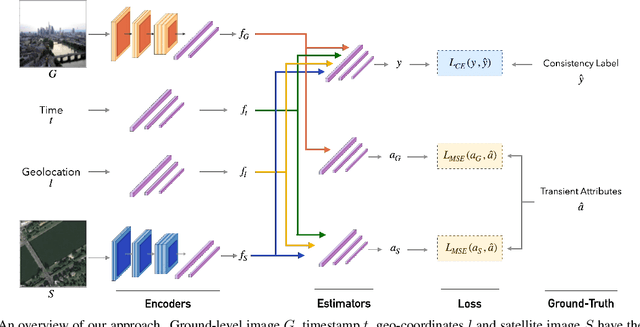
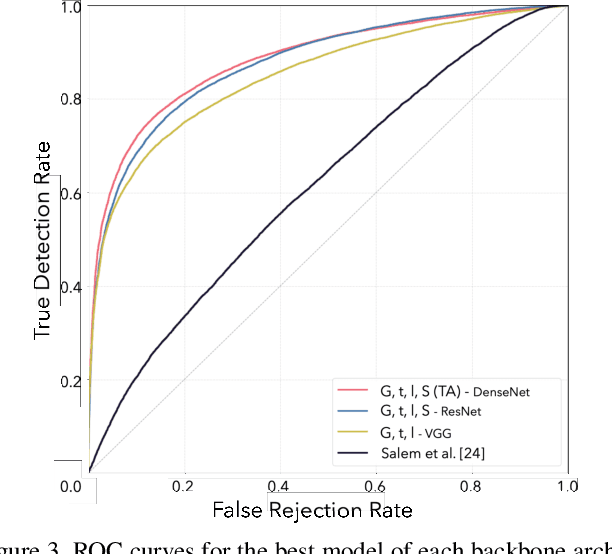
Most pictures shared online are accompanied by a temporal context (i.e., the moment they were taken) that aids their understanding and the history behind them. Claiming that these images were captured in a different moment can be misleading and help to convey a distorted version of reality. In this work, we present the nascent problem of detecting timestamp manipulation. We propose an end-to-end approach to verify whether the purported time of capture of an image is consistent with its content and geographic location. The central idea is the use of supervised consistency verification, in which we predict the probability that the image content, capture time, and geographical location are consistent. We also include a pair of auxiliary tasks, which can be used to explain the network decision. Our approach improves upon previous work on a large benchmark dataset, increasing the classification accuracy from 59.03% to 81.07%. Finally, an ablation study highlights the importance of various components of the method, showing what types of tampering are detectable using our approach.