 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAG vs Fine-tuning: Pipelines, Tradeoffs, and a Case Study on Agriculture
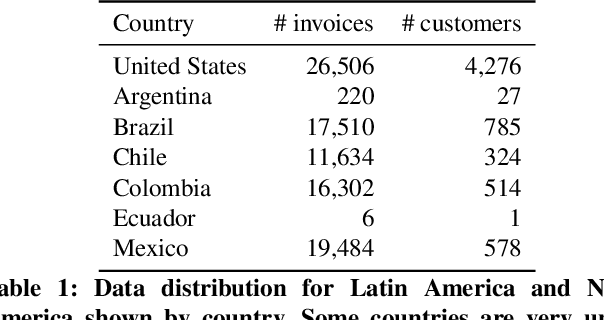
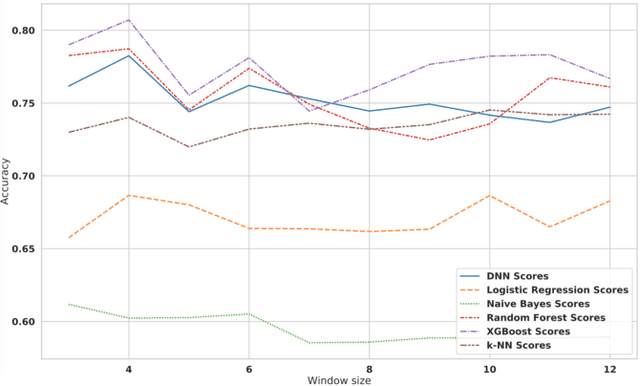
Jan 30, 2024There are two common ways in which developers are incorporating proprietary and domain-specific data when building applications of Large Language Models (LLMs): Retrieval-Augmented Generation (RAG) and Fine-Tuning. RAG augments the prompt with the external data, while fine-Tuning incorporates the additional knowledge into the model itself. However, the pros and cons of both approaches are not well understood. In this paper, we propose a pipeline for fine-tuning and RAG, and present the tradeoffs of both for multiple popular LLMs, including Llama2-13B, GPT-3.5, and GPT-4. Our pipeline consists of multiple stages, including extracting information from PDFs, generating questions and answers, using them for fine-tuning, and leveraging GPT-4 for evaluating the results. We propose metrics to assess the performance of different stages of the RAG and fine-Tuning pipeline. We conduct an in-depth study on an agricultural dataset. Agriculture as an industry has not seen much penetration of AI, and we study a potentially disruptive application - what if we could provide location-specific insights to a farmer? Our results show the effectiveness of our dataset generation pipeline in capturing geographic-specific knowledge, and the quantitative and qualitative benefits of RAG and fine-tuning. We see an accuracy increase of over 6 p.p. when fine-tuning the model and this is cumulative with RAG, which increases accuracy by 5 p.p. further. In one particular experiment, we also demonstrate that the fine-tuned model leverages information from across geographies to answer specific questions, increasing answer similarity from 47% to 72%. Overall, the results point to how systems built using LLMs can be adapted to respond and incorporate knowledge across a dimension that is critical for a specific industry, paving the way for further applications of LLMs in other industrial domains.
A Comprehensive Modeling Approach for Crop Yield Forecasts using AI-based Methods and Crop Simulation Models
Jun 16, 2023



Numerous solutions for yield estimation are either based on data-driven models, or on crop-simulation models (CSMs). Researchers tend to build data-driven models using nationwide crop information databases provided by agencies such as the USDA. On the opposite side of the spectrum, CSMs require fine data that may be hard to generalize from a handful of fields. In this paper, we propose a comprehensive approach for yield forecasting that combines data-driven solutions, crop simulation models, and model surrogates to support multiple user-profiles and needs when dealing with crop management decision-making. To achieve this goal, we have developed a solution to calibrate CSMs at scale, a surrogate model of a CSM assuring faster execution, and a neural network-based approach that performs efficient risk assessment in such settings. Our data-driven modeling approach outperforms previous works with yield correlation predictions close to 91\%. The crop simulation modeling architecture achieved 6% error; the proposed crop simulation model surrogate performs predictions almost 100 times faster than the adopted crop simulator with similar accuracy levels.
On the impact of MDP design for Reinforcement Learning agents in Resource Management
Sep 07, 2021The recent progress in Reinforcement Learning applications to Resource Management presents MDPs without a deeper analysis of the impacts of design decisions on agent performance. In this paper, we compare and contrast four different MDP variations, discussing their computational requirements and impacts on agent performance by means of an empirical analysis. We conclude by showing that, in our experiments, when using Multi-Layer Perceptrons as approximation function, a compact state representation allows transfer of agents between environments, and that transferred agents have good performance and outperform specialized agents in 80\% of the tested scenarios, even without retraining.
Predicting Account Receivables with Machine Learning
Aug 11, 2020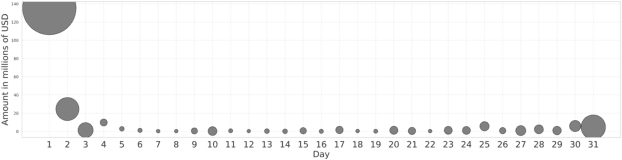

Being able to predict when invoices will be paid is valuable in multiple industries and supports decision-making processes in most financial workflows. However, due to the complexity of data related to invoices and the fact that the decision-making process is not registered in the accounts receivable system, performing this prediction becomes a challenge. In this paper, we present a prototype able to support collectors in predicting the payment of invoices. This prototype is part of a solution developed in partnership with a multinational bank and it has reached up to 81% of prediction accuracy, which improved the prioritization of customers and supported the daily work of collectors. Our simulations show that the adoption of our model to prioritize the work o collectors saves up to ~1.75 million dollars per month. The methodology and results presented in this paper will allow researchers and practitioners in dealing with the problem of invoice payment prediction, providing insights and examples of how to tackle issues present in real data.
Estimating crop yields with remote sensing and deep learning
Jul 21, 2020
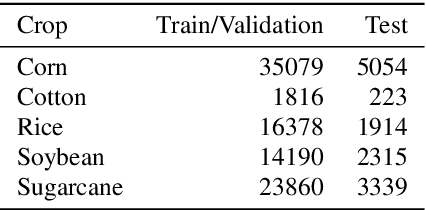

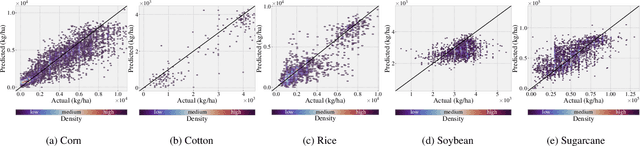
Increasing the accuracy of crop yield estimates may allow improvements in the whole crop production chain, allowing farmers to better plan for harvest, and for insurers to better understand risks of production, to name a few advantages. To perform their predictions, most current machine learning models use NDVI data, which can be hard to use, due to the presence of clouds and their shadows in acquired images, and due to the absence of reliable crop masks for large areas, especially in developing countries. In this paper, we present a deep learning model able to perform pre-season and in-season predictions for five different crops. Our model uses crop calendars, easy-to-obtain remote sensing data and weather forecast information to provide accurate yield estimates.