 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeItem Matching using Text Description and Similarity Search
Jul 01, 2022
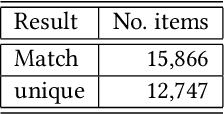
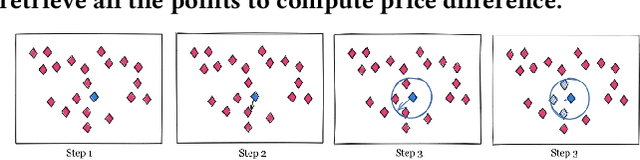

In this paper, we focus on the problem of item matching using only the description. Those specific items not only lack a unique code but also contain short text descriptions, making the item matching process difficult. Our goal is to compare products using only the description provided by the purchase process. Therefore, evaluating other characteristics and differences can uncover possible flaws during the acquiring phase. However, the text of the items that we were working on was very small, with numbers due to the nature of the products and we have a limited amount of time to develop the solution which was 8 weeks. As result, we showed that working using a well-oriented methodology we were able to deliver a successful MVP and achieve the results expected with up to 55% match.
Predicting Account Receivables with Machine Learning
Aug 11, 2020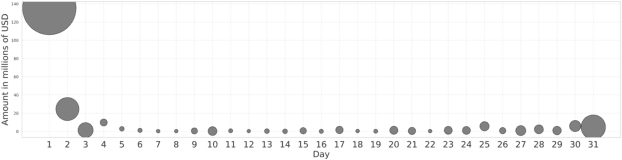
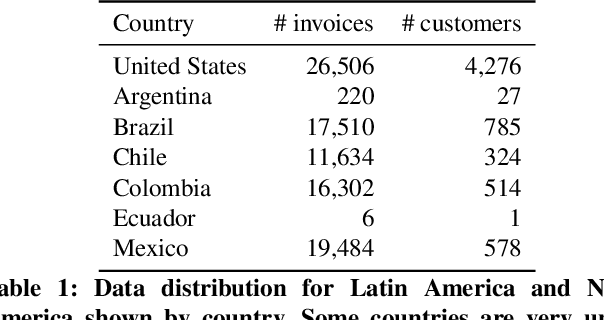

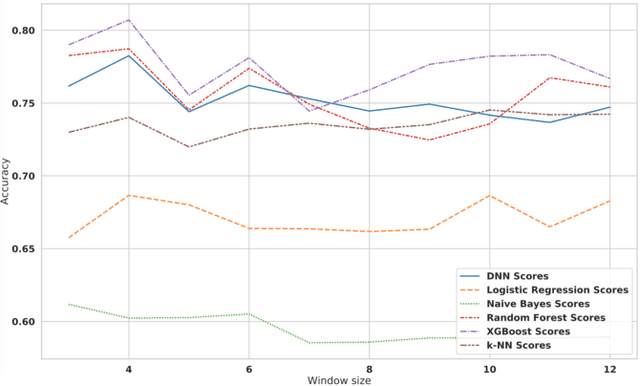
Being able to predict when invoices will be paid is valuable in multiple industries and supports decision-making processes in most financial workflows. However, due to the complexity of data related to invoices and the fact that the decision-making process is not registered in the accounts receivable system, performing this prediction becomes a challenge. In this paper, we present a prototype able to support collectors in predicting the payment of invoices. This prototype is part of a solution developed in partnership with a multinational bank and it has reached up to 81% of prediction accuracy, which improved the prioritization of customers and supported the daily work of collectors. Our simulations show that the adoption of our model to prioritize the work o collectors saves up to ~1.75 million dollars per month. The methodology and results presented in this paper will allow researchers and practitioners in dealing with the problem of invoice payment prediction, providing insights and examples of how to tackle issues present in real data.
Optimize Cash Collection: Use Machine learning to Predicting Invoice Payment
Dec 20, 2019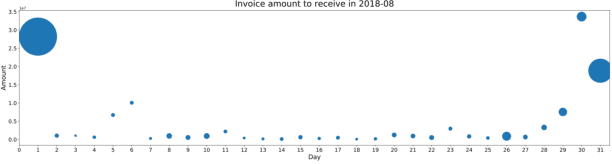
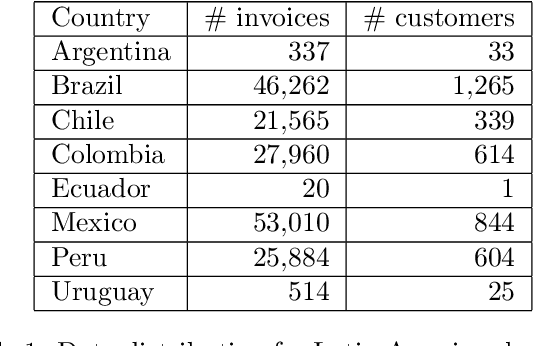
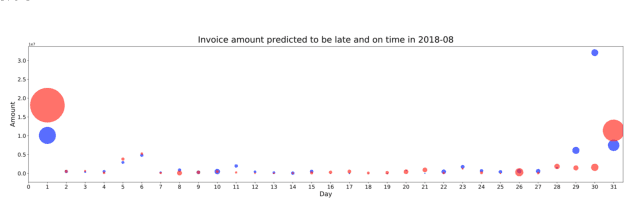
Predicting invoice payment is valuable in multiple industries and supports decision-making processes in most financial workflows. However, the challenge in this realm involves dealing with complex data and the lack of data related to decisions-making processes not registered in the accounts receivable system. This work presents a prototype developed as a solution devised during a partnership with a multinational bank to support collectors in predicting invoices payment. The proposed prototype reached up to 77\% of accuracy, which improved the prioritization of customers and supported the daily work of collectors. With the presented results, one expects to support researchers dealing with the problem of invoice payment prediction to get insights and examples of how to tackle issues present in real data.
Temporally Evolving Community Detection and Prediction in Content-Centric Networks
Jul 17, 2018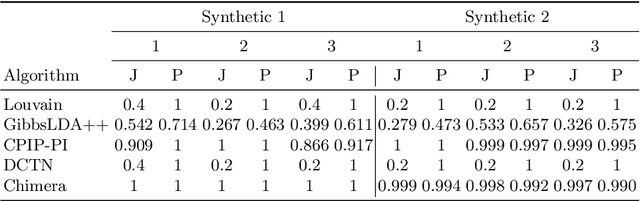
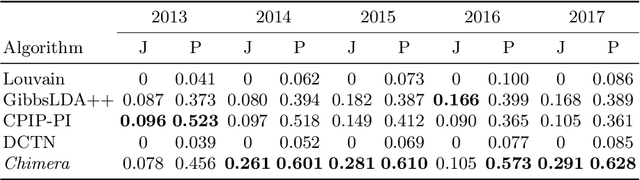


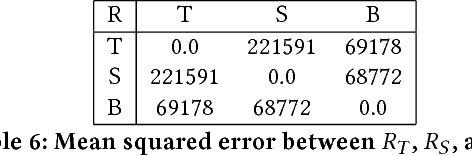
In this work, we consider the problem of combining link, content and temporal analysis for community detection and prediction in evolving networks. Such temporal and content-rich networks occur in many real-life settings, such as bibliographic networks and question answering forums. Most of the work in the literature (that uses both content and structure) deals with static snapshots of networks, and they do not reflect the dynamic changes occurring over multiple snapshots. Incorporating dynamic changes in the communities into the analysis can also provide useful insights about the changes in the network such as the migration of authors across communities. In this work, we propose Chimera, a shared factorization model that can simultaneously account for graph links, content, and temporal analysis. This approach works by extracting the latent semantic structure of the network in multidimensional form, but in a way that takes into account the temporal continuity of these embeddings. Such an approach simplifies temporal analysis of the underlying network by using the embedding as a surrogate. A consequence of this simplification is that it is also possible to use this temporal sequence of embeddings to predict future communities. We present experimental results illustrating the effectiveness of the approach.
Combining Textual Content and Structure to Improve Dialog Similarity
Feb 20, 2018


Chatbots, taking advantage of the success of the messaging apps and recent advances in Artificial Intelligence, have become very popular, from helping business to improve customer services to chatting to users for the sake of conversation and engagement (celebrity or personal bots). However, developing and improving a chatbot requires understanding their data generated by its users. Dialog data has a different nature of a simple question and answering interaction, in which context and temporal properties (turn order) creates a different understanding of such data. In this paper, we propose a novelty metric to compute dialogs' similarity based not only on the text content but also on the information related to the dialog structure. Our experimental results performed over the Switchboard dataset show that using evidence from both textual content and the dialog structure leads to more accurate results than using each measure in isolation.