 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-aware Execution Migration Tool for Data Science Jupyter Notebooks on Hybrid Clouds
Jul 01, 2021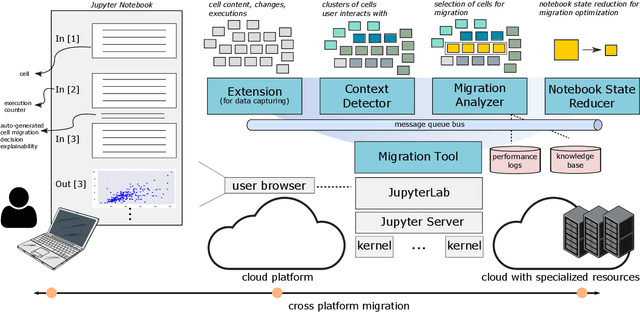
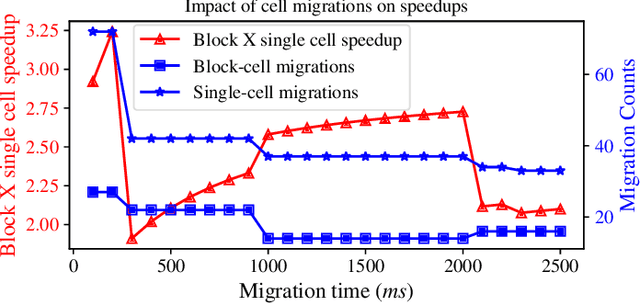
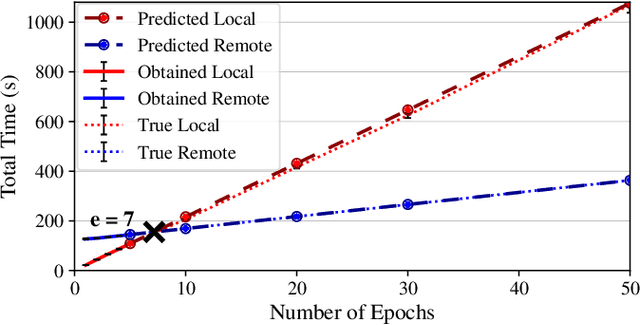
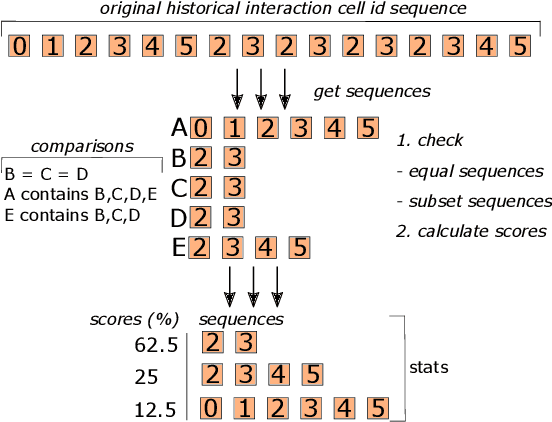
Interactive computing notebooks, such as Jupyter notebooks, have become a popular tool for developing and improving data-driven models. Such notebooks tend to be executed either in the user's own machine or in a cloud environment, having drawbacks and benefits in both approaches. This paper presents a solution developed as a Jupyter extension that automatically selects which cells, as well as in which scenarios, such cells should be migrated to a more suitable platform for execution. We describe how we reduce the execution state of the notebook to decrease migration time and we explore the knowledge of user interactivity patterns with the notebook to determine which blocks of cells should be migrated. Using notebooks from Earth science (remote sensing), image recognition, and hand written digit identification (machine learning), our experiments show notebook state reductions of up to 55x and migration decisions leading to performance gains of up to 3.25x when the user interactivity with the notebook is taken into consideration.
A Scalable Machine Learning System for Pre-Season Agriculture Yield Forecast
Oct 15, 2018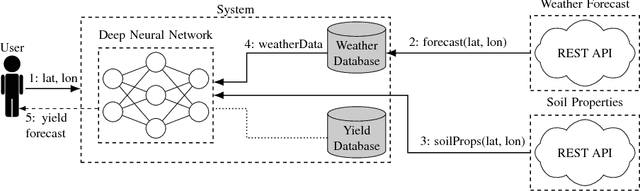


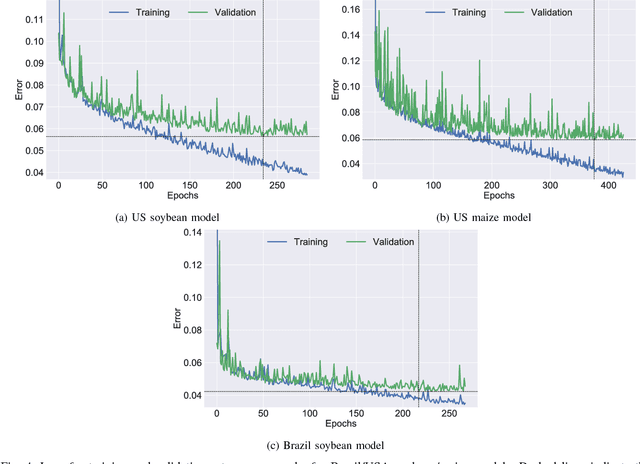
Yield forecast is essential to agriculture stakeholders and can be obtained with the use of machine learning models and data coming from multiple sources. Most solutions for yield forecast rely on NDVI (Normalized Difference Vegetation Index) data, which is time-consuming to be acquired and processed. To bring scalability for yield forecast, in the present paper we describe a system that incorporates satellite-derived precipitation and soil properties datasets, seasonal climate forecasting data from physical models and other sources to produce a pre-season prediction of soybean/maize yield---with no need of NDVI data. This system provides significantly useful results by the exempting the need for high-resolution remote-sensing data and allowing farmers to prepare for adverse climate influence on the crop cycle. In our studies, we forecast the soybean and maize yields for Brazil and USA, which corresponded to 44% of the world's grain production in 2016. Results show the error metrics for soybean and maize yield forecasts are comparable to similar systems that only provide yield forecast information in the first weeks to months of the crop cycle.
DeepDownscale: a Deep Learning Strategy for High-Resolution Weather Forecast
Aug 15, 2018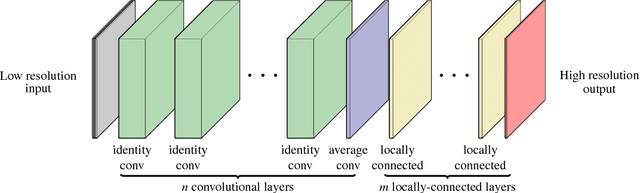
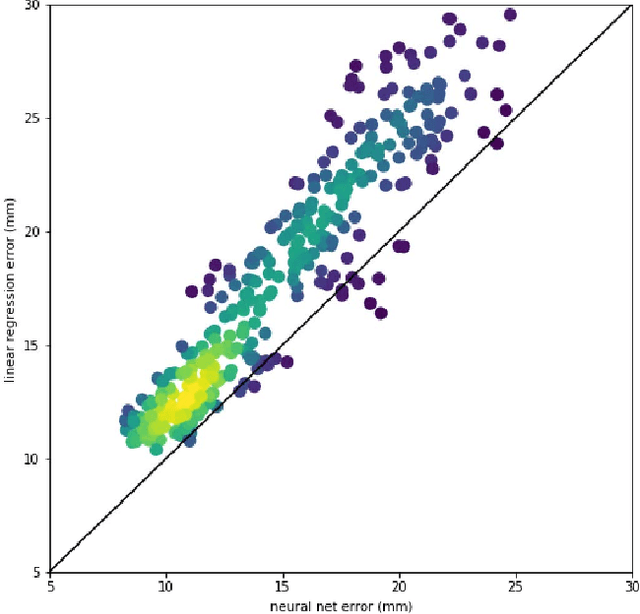
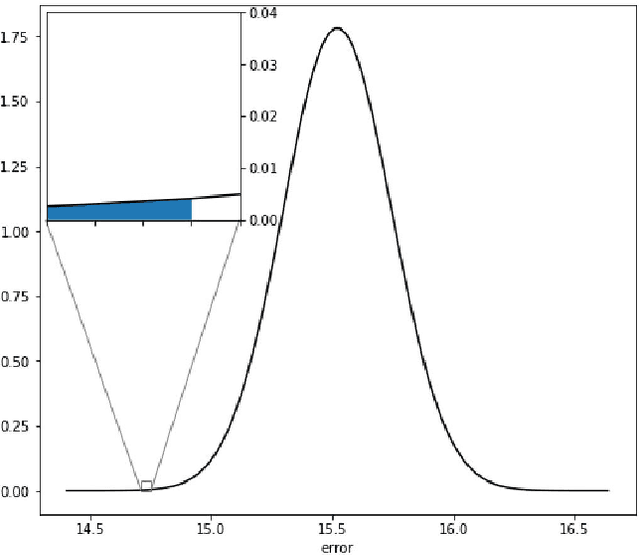
Running high-resolution physical models is computationally expensive and essential for many disciplines. Agriculture, transportation, and energy are sectors that depend on high-resolution weather models, which typically consume many hours of large High Performance Computing (HPC) systems to deliver timely results. Many users cannot afford to run the desired resolution and are forced to use low resolution output. One simple solution is to interpolate results for visualization. It is also possible to combine an ensemble of low resolution models to obtain a better prediction. However, these approaches fail to capture the redundant information and patterns in the low-resolution input that could help improve the quality of prediction. In this paper, we propose and evaluate a strategy based on a deep neural network to learn a high-resolution representation from low-resolution predictions using weather forecast as a practical use case. We take a supervised learning approach, since obtaining labeled data can be done automatically. Our results show significant improvement when compared with standard practices and the strategy is still lightweight enough to run on modest computer systems.
Temporally Evolving Community Detection and Prediction in Content-Centric Networks
Jul 17, 2018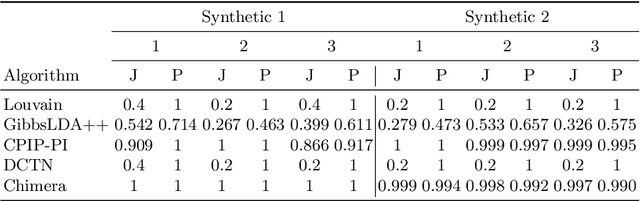
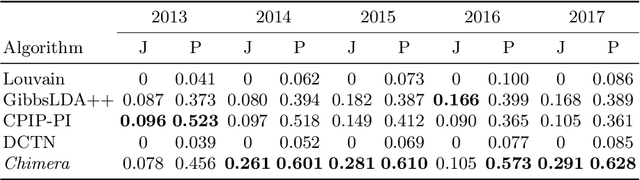


In this work, we consider the problem of combining link, content and temporal analysis for community detection and prediction in evolving networks. Such temporal and content-rich networks occur in many real-life settings, such as bibliographic networks and question answering forums. Most of the work in the literature (that uses both content and structure) deals with static snapshots of networks, and they do not reflect the dynamic changes occurring over multiple snapshots. Incorporating dynamic changes in the communities into the analysis can also provide useful insights about the changes in the network such as the migration of authors across communities. In this work, we propose Chimera, a shared factorization model that can simultaneously account for graph links, content, and temporal analysis. This approach works by extracting the latent semantic structure of the network in multidimensional form, but in a way that takes into account the temporal continuity of these embeddings. Such an approach simplifies temporal analysis of the underlying network by using the embedding as a surrogate. A consequence of this simplification is that it is also possible to use this temporal sequence of embeddings to predict future communities. We present experimental results illustrating the effectiveness of the approach.
Determining Song Similarity via Machine Learning Techniques and Tagging Information
Apr 12, 2017

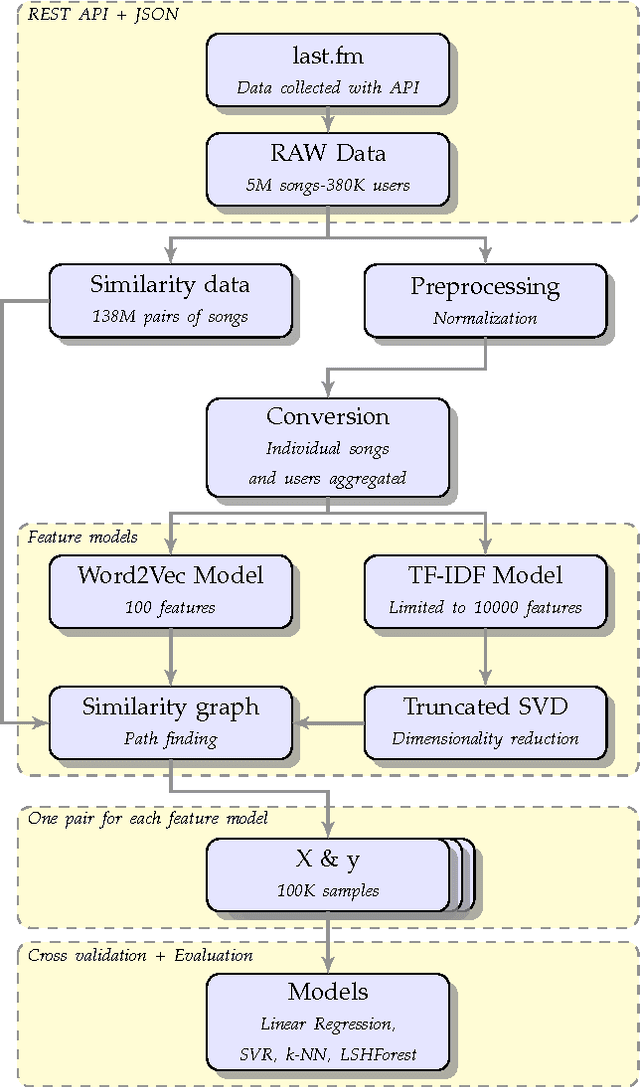
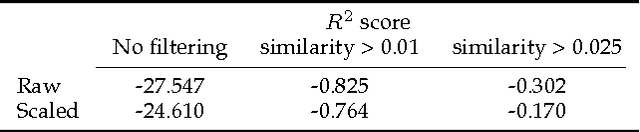
The task of determining item similarity is a crucial one in a recommender system. This constitutes the base upon which the recommender system will work to determine which items are more likely to be enjoyed by a user, resulting in more user engagement. In this paper we tackle the problem of determining song similarity based solely on song metadata (such as the performer, and song title) and on tags contributed by users. We evaluate our approach under a series of different machine learning algorithms. We conclude that tf-idf achieves better results than Word2Vec to model the dataset to feature vectors. We also conclude that k-NN models have better performance than SVMs and Linear Regression for this problem.