 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint Tracking in Surgery--The 2024 Surgical Tattoos in Infrared (STIR) Challenge
Mar 31, 2025Understanding tissue motion in surgery is crucial to enable applications in downstream tasks such as segmentation, 3D reconstruction, virtual tissue landmarking, autonomous probe-based scanning, and subtask autonomy. Labeled data are essential to enabling algorithms in these downstream tasks since they allow us to quantify and train algorithms. This paper introduces a point tracking challenge to address this, wherein participants can submit their algorithms for quantification. The submitted algorithms are evaluated using a dataset named surgical tattoos in infrared (STIR), with the challenge aptly named the STIR Challenge 2024. The STIR Challenge 2024 comprises two quantitative components: accuracy and efficiency. The accuracy component tests the accuracy of algorithms on in vivo and ex vivo sequences. The efficiency component tests the latency of algorithm inference. The challenge was conducted as a part of MICCAI EndoVis 2024. In this challenge, we had 8 total teams, with 4 teams submitting before and 4 submitting after challenge day. This paper details the STIR Challenge 2024, which serves to move the field towards more accurate and efficient algorithms for spatial understanding in surgery. In this paper we summarize the design, submissions, and results from the challenge. The challenge dataset is available here: https://zenodo.org/records/14803158 , and the code for baseline models and metric calculation is available here: https://github.com/athaddius/STIRMetrics
TerraTrace: Temporal Signature Land Use Mapping System
Feb 25, 2025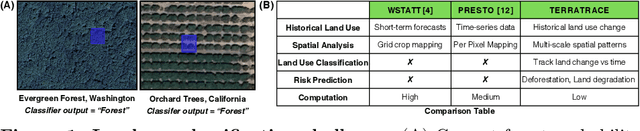
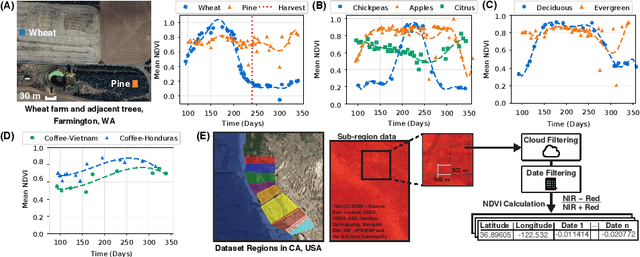
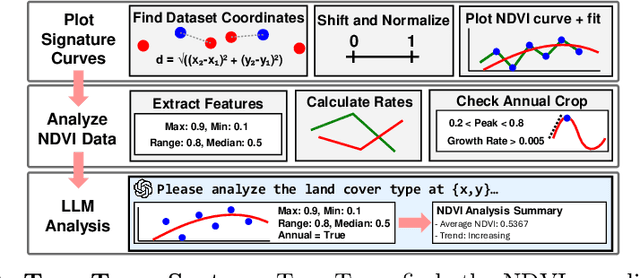

Understanding land use over time is critical to tracking events related to climate change, like deforestation. However, satellite-based remote sensing tools which are used for monitoring struggle to differentiate vegetation types in farms and orchards from forests. We observe that metrics such as the Normalized Difference Vegetation Index (NDVI), based on plant photosynthesis, have unique temporal signatures that reflect agricultural practices and seasonal cycles. We analyze yearly NDVI changes on 20 farms for 10 unique crops. Initial results show that NDVI curves are coherent with agricultural practices, are unique to each crop, consistent globally, and can differentiate farms from forests. We develop a novel longitudinal NDVI dataset for the state of California from 2020-2023 with 500~m resolution and over 70 million points. We use this to develop the TerraTrace platform, an end-to-end analytic tool that classifies land use using NDVI signatures and allows users to query the system through an LLM chatbot and graphical interface.
Injecting New Knowledge into Large Language Models via Supervised Fine-Tuning
Apr 02, 2024

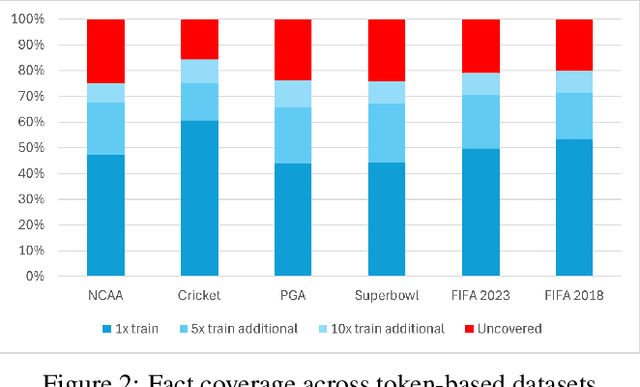

In recent years, Large Language Models (LLMs) have shown remarkable performance in generating human-like text, proving to be a valuable asset across various applications. However, adapting these models to incorporate new, out-of-domain knowledge remains a challenge, particularly for facts and events that occur after the model's knowledge cutoff date. This paper investigates the effectiveness of Supervised Fine-Tuning (SFT) as a method for knowledge injection in LLMs, specifically focusing on the domain of recent sporting events. We compare different dataset generation strategies -- token-based and fact-based scaling -- to create training data that helps the model learn new information. Our experiments on GPT-4 demonstrate that while token-based scaling can lead to improvements in Q&A accuracy, it may not provide uniform coverage of new knowledge. Fact-based scaling, on the other hand, offers a more systematic approach to ensure even coverage across all facts. We present a novel dataset generation process that leads to more effective knowledge ingestion through SFT, and our results show considerable performance improvements in Q&A tasks related to out-of-domain knowledge. This study contributes to the understanding of domain adaptation for LLMs and highlights the potential of SFT in enhancing the factuality of LLM responses in specific knowledge domains.
Exploring Optical Flow Inclusion into nnU-Net Framework for Surgical Instrument Segmentation
Mar 15, 2024Surgical instrument segmentation in laparoscopy is essential for computer-assisted surgical systems. Despite the Deep Learning progress in recent years, the dynamic setting of laparoscopic surgery still presents challenges for precise segmentation. The nnU-Net framework excelled in semantic segmentation analyzing single frames without temporal information. The framework's ease of use, including its ability to be automatically configured, and its low expertise requirements, have made it a popular base framework for comparisons. Optical flow (OF) is a tool commonly used in video tasks to estimate motion and represent it in a single frame, containing temporal information. This work seeks to employ OF maps as an additional input to the nnU-Net architecture to improve its performance in the surgical instrument segmentation task, taking advantage of the fact that instruments are the main moving objects in the surgical field. With this new input, the temporal component would be indirectly added without modifying the architecture. Using CholecSeg8k dataset, three different representations of movement were estimated and used as new inputs, comparing them with a baseline model. Results showed that the use of OF maps improves the detection of classes with high movement, even when these are scarce in the dataset. To further improve performance, future work may focus on implementing other OF-preserving augmentations.
RAG vs Fine-tuning: Pipelines, Tradeoffs, and a Case Study on Agriculture
Jan 30, 2024There are two common ways in which developers are incorporating proprietary and domain-specific data when building applications of Large Language Models (LLMs): Retrieval-Augmented Generation (RAG) and Fine-Tuning. RAG augments the prompt with the external data, while fine-Tuning incorporates the additional knowledge into the model itself. However, the pros and cons of both approaches are not well understood. In this paper, we propose a pipeline for fine-tuning and RAG, and present the tradeoffs of both for multiple popular LLMs, including Llama2-13B, GPT-3.5, and GPT-4. Our pipeline consists of multiple stages, including extracting information from PDFs, generating questions and answers, using them for fine-tuning, and leveraging GPT-4 for evaluating the results. We propose metrics to assess the performance of different stages of the RAG and fine-Tuning pipeline. We conduct an in-depth study on an agricultural dataset. Agriculture as an industry has not seen much penetration of AI, and we study a potentially disruptive application - what if we could provide location-specific insights to a farmer? Our results show the effectiveness of our dataset generation pipeline in capturing geographic-specific knowledge, and the quantitative and qualitative benefits of RAG and fine-tuning. We see an accuracy increase of over 6 p.p. when fine-tuning the model and this is cumulative with RAG, which increases accuracy by 5 p.p. further. In one particular experiment, we also demonstrate that the fine-tuned model leverages information from across geographies to answer specific questions, increasing answer similarity from 47% to 72%. Overall, the results point to how systems built using LLMs can be adapted to respond and incorporate knowledge across a dimension that is critical for a specific industry, paving the way for further applications of LLMs in other industrial domains.
GPT-4 as an Agronomist Assistant? Answering Agriculture Exams Using Large Language Models
Oct 12, 2023



Large language models (LLMs) have demonstrated remarkable capabilities in natural language understanding across various domains, including healthcare and finance. For some tasks, LLMs achieve similar or better performance than trained human beings, therefore it is reasonable to employ human exams (e.g., certification tests) to assess the performance of LLMs. We present a comprehensive evaluation of popular LLMs, such as Llama 2 and GPT, on their ability to answer agriculture-related questions. In our evaluation, we also employ RAG (Retrieval-Augmented Generation) and ER (Ensemble Refinement) techniques, which combine information retrieval, generation capabilities, and prompting strategies to improve the LLMs' performance. To demonstrate the capabilities of LLMs, we selected agriculture exams and benchmark datasets from three of the largest agriculture producer countries: Brazil, India, and the USA. Our analysis highlights GPT-4's ability to achieve a passing score on exams to earn credits for renewing agronomist certifications, answering 93% of the questions correctly and outperforming earlier general-purpose models, which achieved 88% accuracy. On one of our experiments, GPT-4 obtained the highest performance when compared to human subjects. This performance suggests that GPT-4 could potentially pass on major graduate education admission tests or even earn credits for renewing agronomy certificates. We also explore the models' capacity to address general agriculture-related questions and generate crop management guidelines for Brazilian and Indian farmers, utilizing robust datasets from the Brazilian Agency of Agriculture (Embrapa) and graduate program exams from India. The results suggest that GPT-4, ER, and RAG can contribute meaningfully to agricultural education, assessment, and crop management practice, offering valuable insights to farmers and agricultural professionals.
Strength in Diversity: Multi-Branch Representation Learning for Vehicle Re-Identification
Oct 02, 2023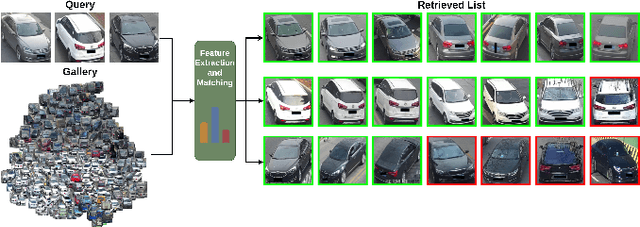
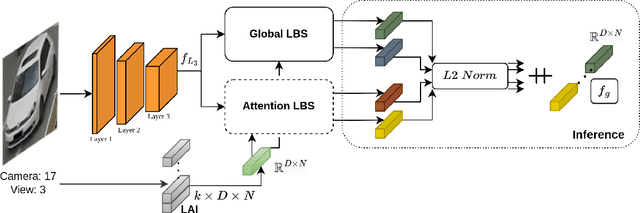
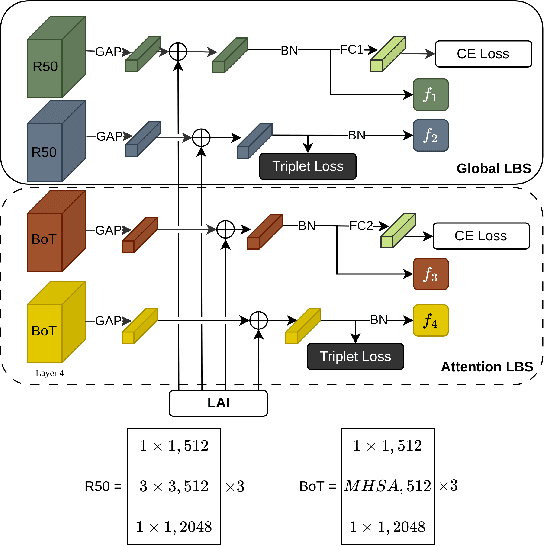
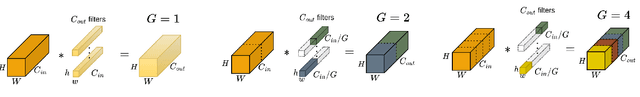
This paper presents an efficient and lightweight multi-branch deep architecture to improve vehicle re-identification (V-ReID). While most V-ReID work uses a combination of complex multi-branch architectures to extract robust and diversified embeddings towards re-identification, we advocate that simple and lightweight architectures can be designed to fulfill the Re-ID task without compromising performance. We propose a combination of Grouped-convolution and Loss-Branch-Split strategies to design a multi-branch architecture that improve feature diversity and feature discriminability. We combine a ResNet50 global branch architecture with a BotNet self-attention branch architecture, both designed within a Loss-Branch-Split (LBS) strategy. We argue that specialized loss-branch-splitting helps to improve re-identification tasks by generating specialized re-identification features. A lightweight solution using grouped convolution is also proposed to mimic the learning of loss-splitting into multiple embeddings while significantly reducing the model size. In addition, we designed an improved solution to leverage additional metadata, such as camera ID and pose information, that uses 97% less parameters, further improving re-identification performance. In comparison to state-of-the-art (SoTA) methods, our approach outperforms competing solutions in Veri-776 by achieving 85.6% mAP and 97.7% CMC1 and obtains competitive results in Veri-Wild with 88.1% mAP and 96.3% CMC1. Overall, our work provides important insights into improving vehicle re-identification and presents a strong basis for other retrieval tasks. Our code is available at the https://github.com/videturfortuna/vehicle_reid_itsc2023.
A Comprehensive Modeling Approach for Crop Yield Forecasts using AI-based Methods and Crop Simulation Models
Jun 16, 2023



Numerous solutions for yield estimation are either based on data-driven models, or on crop-simulation models (CSMs). Researchers tend to build data-driven models using nationwide crop information databases provided by agencies such as the USDA. On the opposite side of the spectrum, CSMs require fine data that may be hard to generalize from a handful of fields. In this paper, we propose a comprehensive approach for yield forecasting that combines data-driven solutions, crop simulation models, and model surrogates to support multiple user-profiles and needs when dealing with crop management decision-making. To achieve this goal, we have developed a solution to calibrate CSMs at scale, a surrogate model of a CSM assuring faster execution, and a neural network-based approach that performs efficient risk assessment in such settings. Our data-driven modeling approach outperforms previous works with yield correlation predictions close to 91\%. The crop simulation modeling architecture achieved 6% error; the proposed crop simulation model surrogate performs predictions almost 100 times faster than the adopted crop simulator with similar accuracy levels.
SurgT challenge: Benchmark of Soft-Tissue Trackers for Robotic Surgery
Feb 28, 2023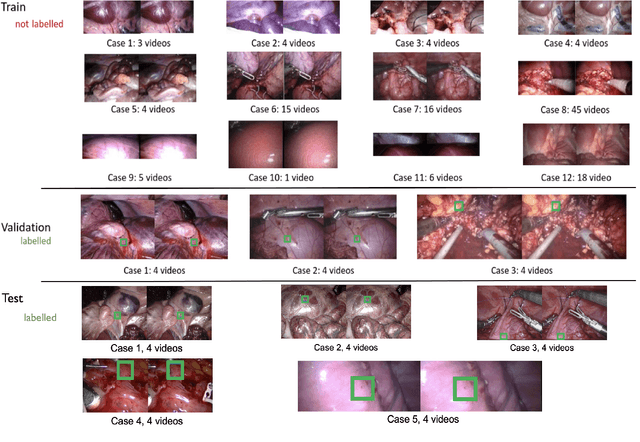
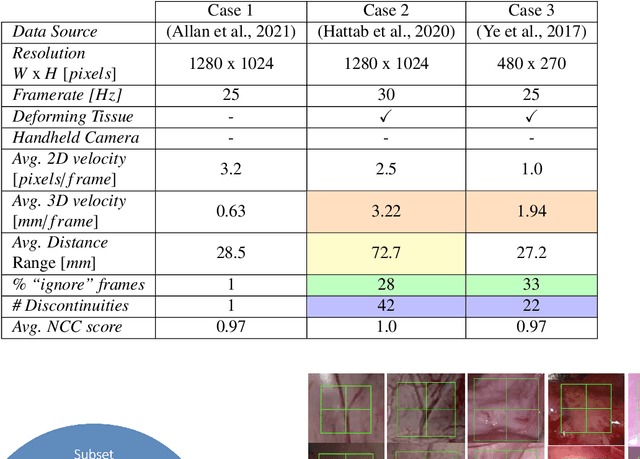
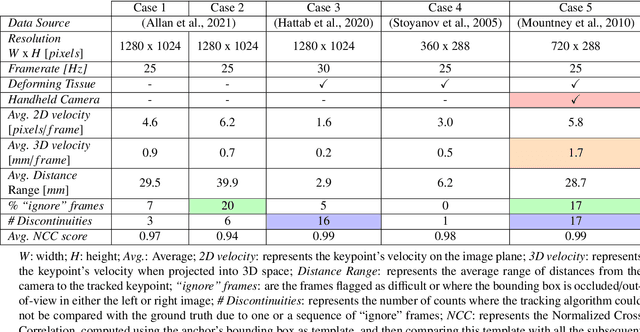
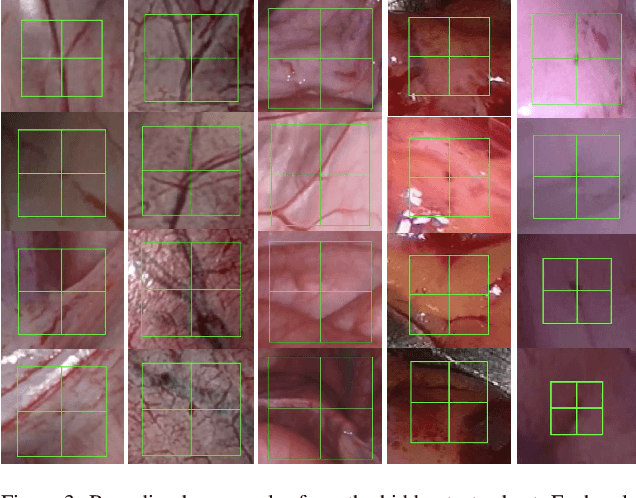
This paper introduces the "SurgT: Surgical Tracking" challenge which was organised in conjunction with the 25th International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI 2022). There were two purposes for the creation of this challenge: (1) the establishment of the first standardised benchmark for the research community to assess soft-tissue trackers; and (2) to encourage the development of unsupervised deep learning methods, given the lack of annotated data in surgery. A dataset of 157 stereo endoscopic videos from 20 clinical cases, along with stereo camera calibration parameters, have been provided. The participants were tasked with the development of algorithms to track a bounding box on stereo endoscopic videos. At the end of the challenge, the developed methods were assessed on a previously hidden test subset. This assessment uses benchmarking metrics that were purposely developed for this challenge and are now available online. The teams were ranked according to their Expected Average Overlap (EAO) score, which is a weighted average of the Intersection over Union (IoU) scores. The performance evaluation study verifies the efficacy of unsupervised deep learning algorithms in tracking soft-tissue. The best-performing method achieved an EAO score of 0.583 in the test subset. The dataset and benchmarking tool created for this challenge have been made publicly available. This challenge is expected to contribute to the development of autonomous robotic surgery and other digital surgical technologies.
Context-aware Execution Migration Tool for Data Science Jupyter Notebooks on Hybrid Clouds
Jul 01, 2021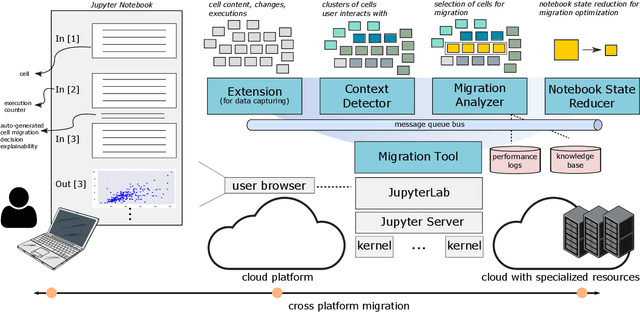
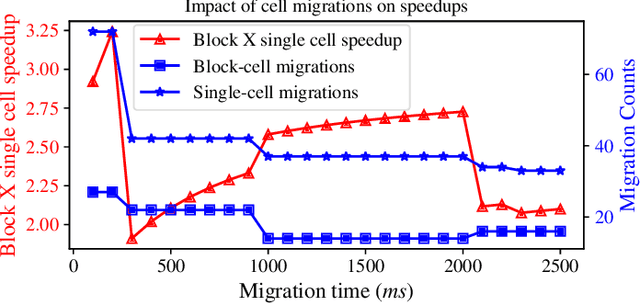
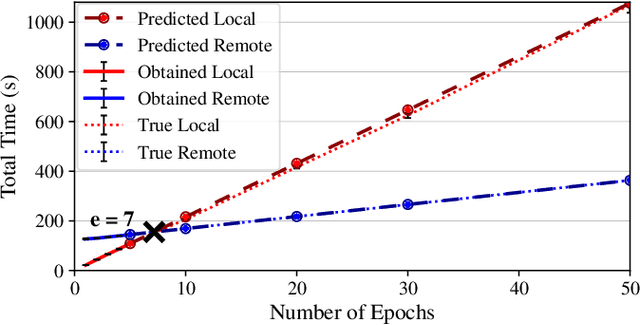
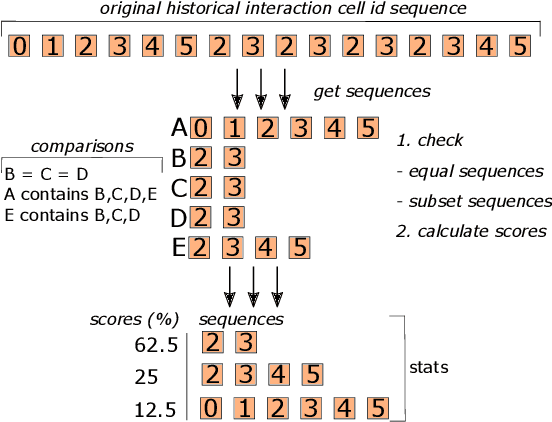
Interactive computing notebooks, such as Jupyter notebooks, have become a popular tool for developing and improving data-driven models. Such notebooks tend to be executed either in the user's own machine or in a cloud environment, having drawbacks and benefits in both approaches. This paper presents a solution developed as a Jupyter extension that automatically selects which cells, as well as in which scenarios, such cells should be migrated to a more suitable platform for execution. We describe how we reduce the execution state of the notebook to decrease migration time and we explore the knowledge of user interactivity patterns with the notebook to determine which blocks of cells should be migrated. Using notebooks from Earth science (remote sensing), image recognition, and hand written digit identification (machine learning), our experiments show notebook state reductions of up to 55x and migration decisions leading to performance gains of up to 3.25x when the user interactivity with the notebook is taken into consideration.