 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInjecting New Knowledge into Large Language Models via Supervised Fine-Tuning
Apr 02, 2024

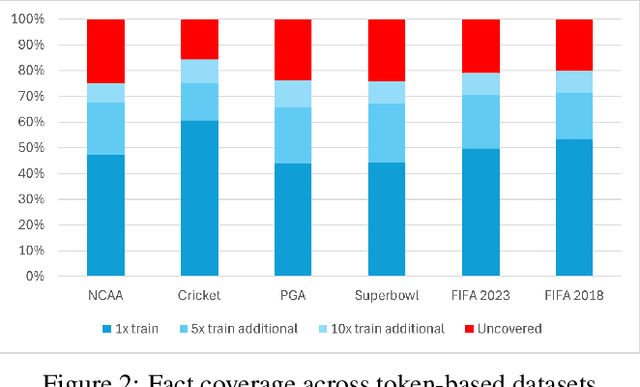

In recent years, Large Language Models (LLMs) have shown remarkable performance in generating human-like text, proving to be a valuable asset across various applications. However, adapting these models to incorporate new, out-of-domain knowledge remains a challenge, particularly for facts and events that occur after the model's knowledge cutoff date. This paper investigates the effectiveness of Supervised Fine-Tuning (SFT) as a method for knowledge injection in LLMs, specifically focusing on the domain of recent sporting events. We compare different dataset generation strategies -- token-based and fact-based scaling -- to create training data that helps the model learn new information. Our experiments on GPT-4 demonstrate that while token-based scaling can lead to improvements in Q&A accuracy, it may not provide uniform coverage of new knowledge. Fact-based scaling, on the other hand, offers a more systematic approach to ensure even coverage across all facts. We present a novel dataset generation process that leads to more effective knowledge ingestion through SFT, and our results show considerable performance improvements in Q&A tasks related to out-of-domain knowledge. This study contributes to the understanding of domain adaptation for LLMs and highlights the potential of SFT in enhancing the factuality of LLM responses in specific knowledge domains.
RAG vs Fine-tuning: Pipelines, Tradeoffs, and a Case Study on Agriculture
Jan 30, 2024There are two common ways in which developers are incorporating proprietary and domain-specific data when building applications of Large Language Models (LLMs): Retrieval-Augmented Generation (RAG) and Fine-Tuning. RAG augments the prompt with the external data, while fine-Tuning incorporates the additional knowledge into the model itself. However, the pros and cons of both approaches are not well understood. In this paper, we propose a pipeline for fine-tuning and RAG, and present the tradeoffs of both for multiple popular LLMs, including Llama2-13B, GPT-3.5, and GPT-4. Our pipeline consists of multiple stages, including extracting information from PDFs, generating questions and answers, using them for fine-tuning, and leveraging GPT-4 for evaluating the results. We propose metrics to assess the performance of different stages of the RAG and fine-Tuning pipeline. We conduct an in-depth study on an agricultural dataset. Agriculture as an industry has not seen much penetration of AI, and we study a potentially disruptive application - what if we could provide location-specific insights to a farmer? Our results show the effectiveness of our dataset generation pipeline in capturing geographic-specific knowledge, and the quantitative and qualitative benefits of RAG and fine-tuning. We see an accuracy increase of over 6 p.p. when fine-tuning the model and this is cumulative with RAG, which increases accuracy by 5 p.p. further. In one particular experiment, we also demonstrate that the fine-tuned model leverages information from across geographies to answer specific questions, increasing answer similarity from 47% to 72%. Overall, the results point to how systems built using LLMs can be adapted to respond and incorporate knowledge across a dimension that is critical for a specific industry, paving the way for further applications of LLMs in other industrial domains.
DeepG2P: Fusing Multi-Modal Data to Improve Crop Production
Nov 11, 2022



Agriculture is at the heart of the solution to achieve sustainability in feeding the world population, but advancing our understanding on how agricultural output responds to climatic variability is still needed. Precision Agriculture (PA), which is a management strategy that uses technology such as remote sensing, Geographical Information System (GIS), and machine learning for decision making in the field, has emerged as a promising approach to enhance crop production, increase yield, and reduce water and nutrient losses and environmental impacts. In this context, multiple models to predict agricultural phenotypes, such as crop yield, from genomics (G), environment (E), weather and soil, and field management practices (M) have been developed. These models have traditionally been based on mechanistic or statistical approaches. However, AI approaches are intrinsically well-suited to model complex interactions and have more recently been developed, outperforming classical methods. Here, we present a Natural Language Processing (NLP)-based neural network architecture to process the G, E and M inputs and their interactions. We show that by modeling DNA as natural language, our approach performs better than previous approaches when tested for new environments and similarly to other approaches for unseen seed varieties.
Causal Modeling of Soil Processes for Improved Generalization
Nov 10, 2022
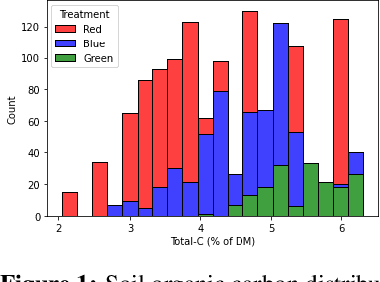
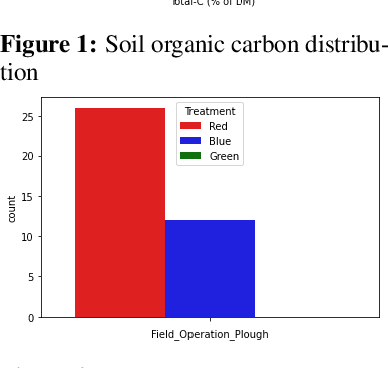
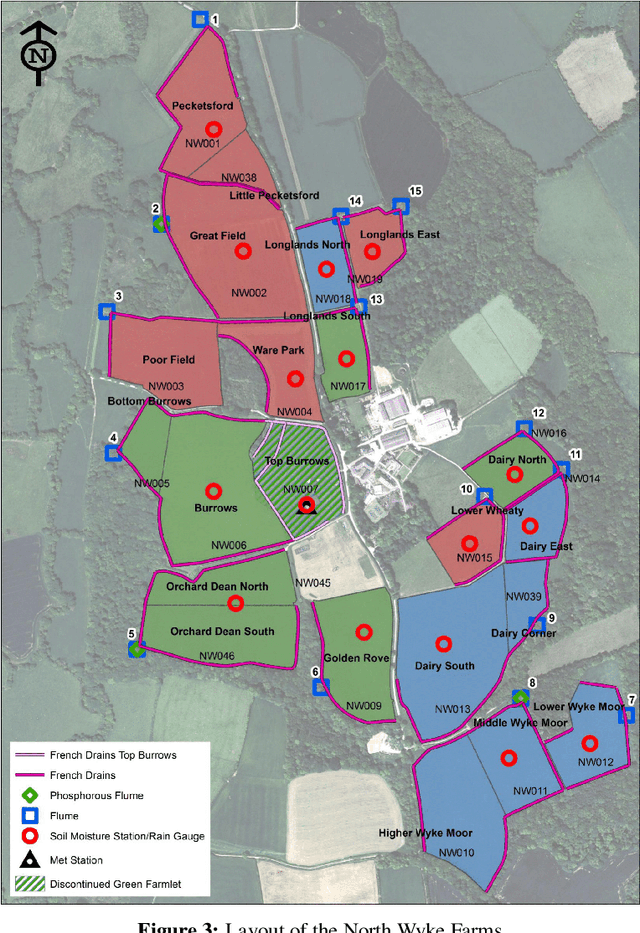
Measuring and monitoring soil organic carbon is critical for agricultural productivity and for addressing critical environmental problems. Soil organic carbon not only enriches nutrition in soil, but also has a gamut of co-benefits such as improving water storage and limiting physical erosion. Despite a litany of work in soil organic carbon estimation, current approaches do not generalize well across soil conditions and management practices. We empirically show that explicit modeling of cause-and-effect relationships among the soil processes improves the out-of-distribution generalizability of prediction models. We provide a comparative analysis of soil organic carbon estimation models where the skeleton is estimated using causal discovery methods. Our framework provide an average improvement of 81% in test mean squared error and 52% in test mean absolute error.
Machine learning can guide experimental approaches for protein digestibility estimations
Nov 01, 2022



Food protein digestibility and bioavailability are critical aspects in addressing human nutritional demands, particularly when seeking sustainable alternatives to animal-based proteins. In this study, we propose a machine learning approach to predict the true ileal digestibility coefficient of food items. The model makes use of a unique curated dataset that combines nutritional information from different foods with FASTA sequences of some of their protein families. We extracted the biochemical properties of the proteins and combined these properties with embeddings from a Transformer-based protein Language Model (pLM). In addition, we used SHAP to identify features that contribute most to the model prediction and provide interpretability. This first AI-based model for predicting food protein digestibility has an accuracy of 90% compared to existing experimental techniques. With this accuracy, our model can eliminate the need for lengthy in-vivo or in-vitro experiments, making the process of creating new foods faster, cheaper, and more ethical.
Machine learning approaches for localized lockdown during COVID-19: a case study analysis
Jan 03, 2022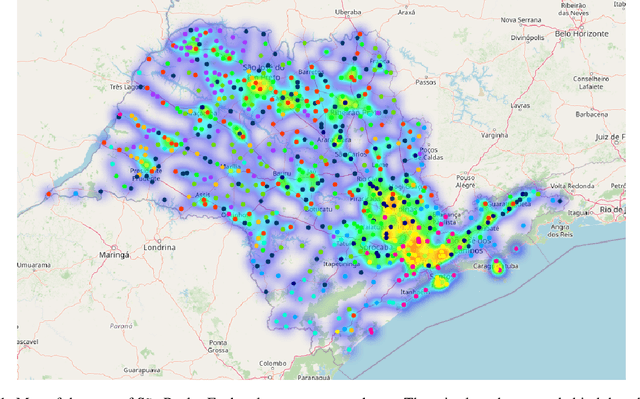
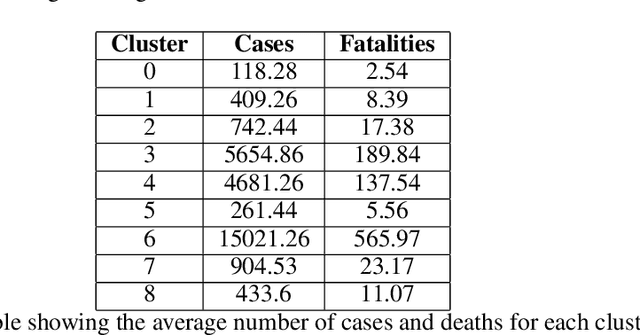
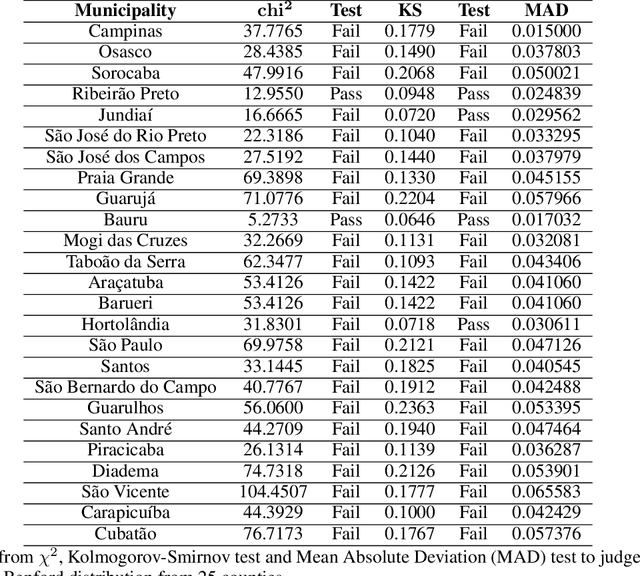
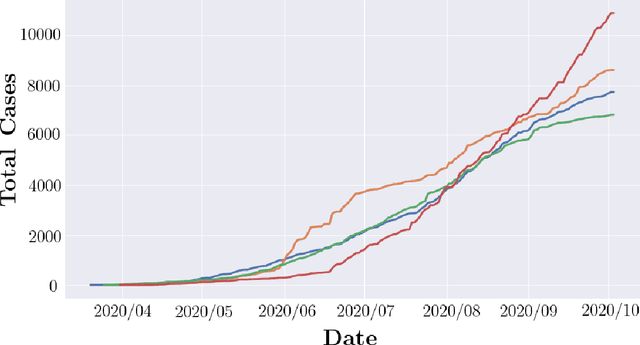
At the end of 2019, the latest novel coronavirus Sars-CoV-2 emerged as a significant acute respiratory disease that has become a global pandemic. Countries like Brazil have had difficulty in dealing with the virus due to the high socioeconomic difference of states and municipalities. Therefore, this study presents a new approach using different machine learning and deep learning algorithms applied to Brazilian COVID-19 data. First, a clustering algorithm is used to identify counties with similar sociodemographic behavior, while Benford's law is used to check for data manipulation. Based on these results we are able to correctly model SARIMA models based on the clusters to predict new daily cases. The unsupervised machine learning techniques optimized the process of defining the parameters of the SARIMA model. This framework can also be useful to propose confinement scenarios during the so-called second wave. We have used the 645 counties from S\~ao Paulo state, the most populous state in Brazil. However, this methodology can be used in other states or countries. This paper demonstrates how different techniques of machine learning, deep learning, data mining and statistics can be used together to produce important results when dealing with pandemic data. Although the findings cannot be used exclusively to assess and influence policy decisions, they offer an alternative to the ineffective measures that have been used.