 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepG2P: Fusing Multi-Modal Data to Improve Crop Production
Nov 11, 2022



Agriculture is at the heart of the solution to achieve sustainability in feeding the world population, but advancing our understanding on how agricultural output responds to climatic variability is still needed. Precision Agriculture (PA), which is a management strategy that uses technology such as remote sensing, Geographical Information System (GIS), and machine learning for decision making in the field, has emerged as a promising approach to enhance crop production, increase yield, and reduce water and nutrient losses and environmental impacts. In this context, multiple models to predict agricultural phenotypes, such as crop yield, from genomics (G), environment (E), weather and soil, and field management practices (M) have been developed. These models have traditionally been based on mechanistic or statistical approaches. However, AI approaches are intrinsically well-suited to model complex interactions and have more recently been developed, outperforming classical methods. Here, we present a Natural Language Processing (NLP)-based neural network architecture to process the G, E and M inputs and their interactions. We show that by modeling DNA as natural language, our approach performs better than previous approaches when tested for new environments and similarly to other approaches for unseen seed varieties.
On-Device CPU Scheduling for Sense-React Systems
Aug 14, 2022

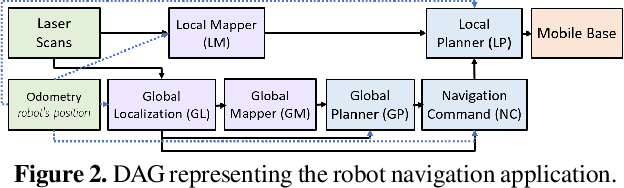
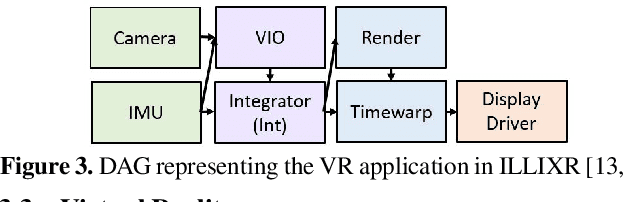
Sense-react systems (e.g. robotics and AR/VR) have to take highly responsive real-time actions, driven by complex decisions involving a pipeline of sensing, perception, planning, and reaction tasks. These tasks must be scheduled on resource-constrained devices such that the performance goals and the requirements of the application are met. This is a difficult scheduling problem that requires handling multiple scheduling dimensions, and variations in resource usage and availability. In practice, system designers manually tune parameters for their specific hardware and application, which results in poor generalization and increases the development burden. In this work, we highlight the emerging need for scheduling CPU resources at runtime in sense-react systems. We study three canonical applications (face tracking, robot navigation, and VR) to first understand the key scheduling requirements for such systems. Armed with this understanding, we develop a scheduling framework, Catan, that dynamically schedules compute resources across different components of an app so as to meet the specified application requirements. Through experiments with a prototype implemented on a widely-used robotics framework (ROS) and an open-source AR/VR platform, we show the impact of system scheduling on meeting the performance goals for the three applications, how Catan is able to achieve better application performance than hand-tuned configurations, and how it dynamically adapts to runtime variations.
Large Scale Question Answering using Tourism Data
Sep 08, 2019
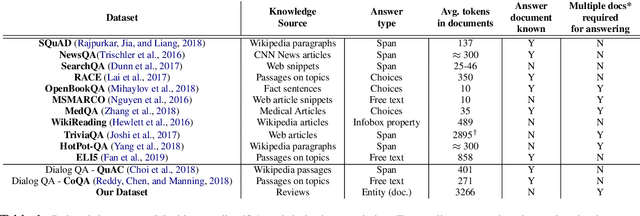
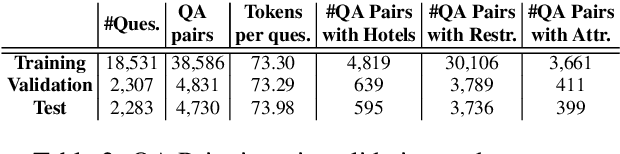
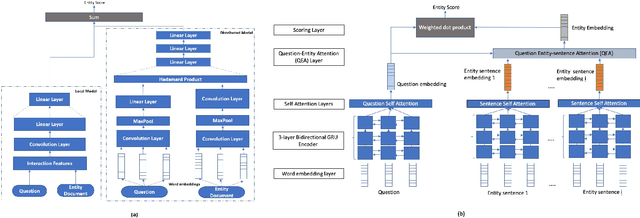
Real world question answering can be significantly more complex than what most existing QA datasets reflect. Questions posed by users on websites, such as online travel forums, may consist of multiple sentences and not everything mentioned in a question may be relevant for finding its answer. Such questions typically have a huge candidate answer space and require complex reasoning over large knowledge corpora. We introduce the novel task of answering entity-seeking recommendation questions using a collection of reviews that describe candidate answer entities. We harvest a QA dataset that contains 48,147 paragraph-sized real user questions from travelers seeking recommendations for hotels, attractions and restaurants. Each candidate answer is associated with a collection of unstructured reviews. This dataset is challenging because commonly used neural architectures for QA are prohibitively expensive for a task of this scale. As a solution, we design a scalable cluster-select-rerank approach. It first clusters text for each entity to identify exemplar sentences describing an entity. It then uses a scalable neural information retrieval (IR) module to subselect a set of potential entities from the large candidate set. A reranker uses a deeper attention-based architecture to pick the best answers from the selected entities. This strategy performs better than a pure IR or a pure attention-based reasoning approach yielding nearly 10% relative improvement in Accuracy@3 over both approaches.