 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning is about giving reasons
Aug 20, 2025Convincing someone of the truth value of a premise requires understanding and articulating the core logical structure of the argument which proves or disproves the premise. Understanding the logical structure of an argument refers to understanding the underlying "reasons" which make up the proof or disproof of the premise - as a function of the "logical atoms" in the argument. While it has been shown that transformers can "chain" rules to derive simple arguments, the challenge of articulating the "reasons" remains. Not only do current approaches to chaining rules suffer in terms of their interpretability, they are also quite constrained in their ability to accommodate extensions to theoretically equivalent reasoning tasks - a model trained to chain rules cannot support abduction or identify contradictions. In this work we suggest addressing these shortcomings by identifying an intermediate representation (which we call the Representation of the Logical Structure (RLS) of the argument) that possesses an understanding of the logical structure of a natural language argument - the logical atoms in the argument and the rules incorporating them. Given the logical structure, reasoning is deterministic and easy to compute. Therefore, our approach supports all forms of reasoning that depend on the logical structure of the natural language argument, including arbitrary depths of reasoning, on-the-fly mistake rectification and interactive discussion with respect to an argument. We show that we can identify and extract the logical structure of natural language arguments in three popular reasoning datasets with high accuracies, thus supporting explanation generation and extending the reasoning capabilities significantly.
What do we expect from Multiple-choice QA Systems?
Nov 20, 2020


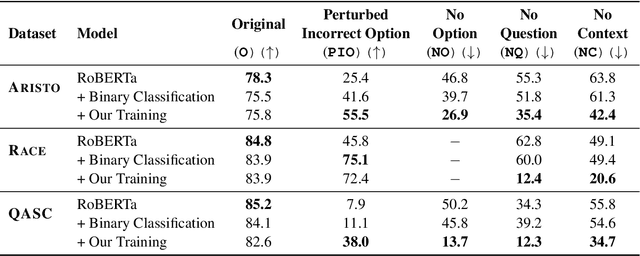
The recent success of machine learning systems on various QA datasets could be interpreted as a significant improvement in models' language understanding abilities. However, using various perturbations, multiple recent works have shown that good performance on a dataset might not indicate performance that correlates well with human's expectations from models that "understand" language. In this work we consider a top performing model on several Multiple Choice Question Answering (MCQA) datasets, and evaluate it against a set of expectations one might have from such a model, using a series of zero-information perturbations of the model's inputs. Our results show that the model clearly falls short of our expectations, and motivates a modified training approach that forces the model to better attend to the inputs. We show that the new training paradigm leads to a model that performs on par with the original model while better satisfying our expectations.
* Findings of EMNLP 2020
Large Scale Question Answering using Tourism Data
Sep 08, 2019
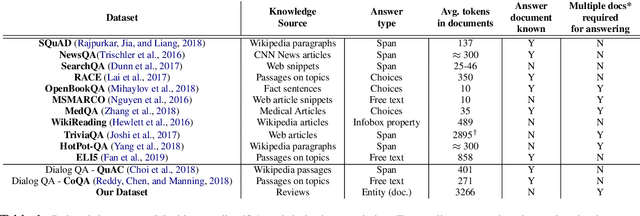
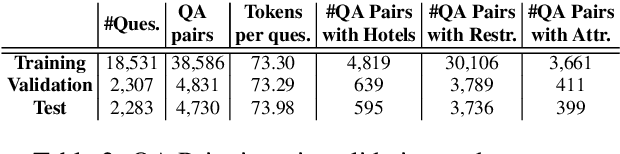
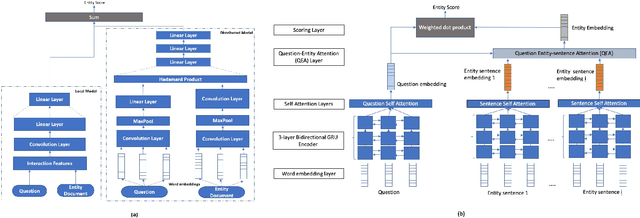
Real world question answering can be significantly more complex than what most existing QA datasets reflect. Questions posed by users on websites, such as online travel forums, may consist of multiple sentences and not everything mentioned in a question may be relevant for finding its answer. Such questions typically have a huge candidate answer space and require complex reasoning over large knowledge corpora. We introduce the novel task of answering entity-seeking recommendation questions using a collection of reviews that describe candidate answer entities. We harvest a QA dataset that contains 48,147 paragraph-sized real user questions from travelers seeking recommendations for hotels, attractions and restaurants. Each candidate answer is associated with a collection of unstructured reviews. This dataset is challenging because commonly used neural architectures for QA are prohibitively expensive for a task of this scale. As a solution, we design a scalable cluster-select-rerank approach. It first clusters text for each entity to identify exemplar sentences describing an entity. It then uses a scalable neural information retrieval (IR) module to subselect a set of potential entities from the large candidate set. A reranker uses a deeper attention-based architecture to pick the best answers from the selected entities. This strategy performs better than a pure IR or a pure attention-based reasoning approach yielding nearly 10% relative improvement in Accuracy@3 over both approaches.