 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Spatio-Temporal World Scene Graph Generation from Monocular Videos
Mar 13, 2026Spatio-temporal scene graphs provide a principled representation for modeling evolving object interactions, yet existing methods remain fundamentally frame-centric: they reason only about currently visible objects, discard entities upon occlusion, and operate in 2D. To address this, we first introduce ActionGenome4D, a dataset that upgrades Action Genome videos into 4D scenes via feed-forward 3D reconstruction, world-frame oriented bounding boxes for every object involved in actions, and dense relationship annotations including for objects that are temporarily unobserved due to occlusion or camera motion. Building on this data, we formalize World Scene Graph Generation (WSGG), the task of constructing a world scene graph at each timestamp that encompasses all interacting objects in the scene, both observed and unobserved. We then propose three complementary methods, each exploring a different inductive bias for reasoning about unobserved objects: PWG (Persistent World Graph), which implements object permanence via a zero-order feature buffer; MWAE (Masked World Auto-Encoder), which reframes unobserved-object reasoning as masked completion with cross-view associative retrieval; and 4DST (4D Scene Transformer), which replaces the static buffer with differentiable per-object temporal attention enriched by 3D motion and camera-pose features. We further design and evaluate the performance of strong open-source Vision-Language Models on the WSGG task via a suite of Graph RAG-based approaches, establishing baselines for unlocalized relationship prediction. WSGG thus advances video scene understanding toward world-centric, temporally persistent, and interpretable scene reasoning.
Can Multimodal LLMs Solve the Basic Perception Problems of Percept-V?
Aug 28, 2025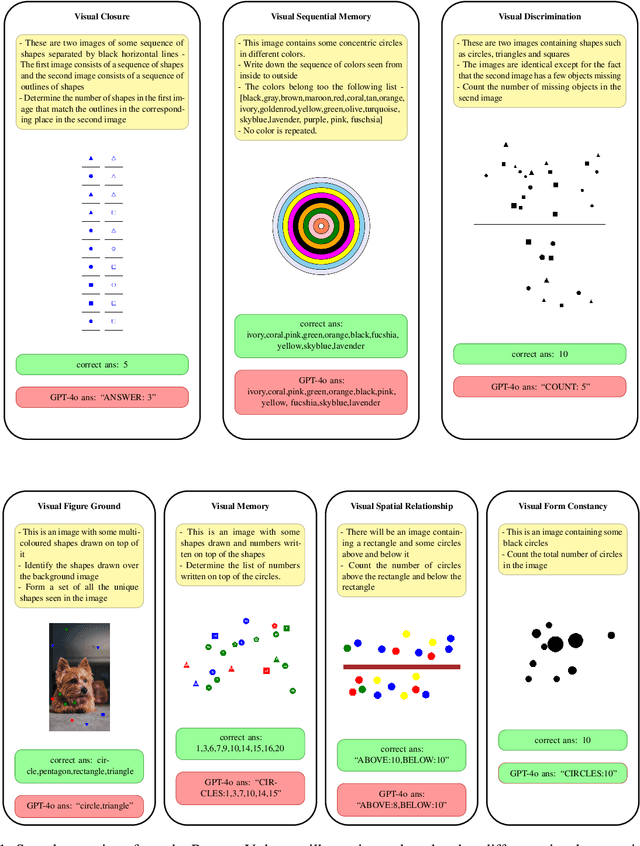
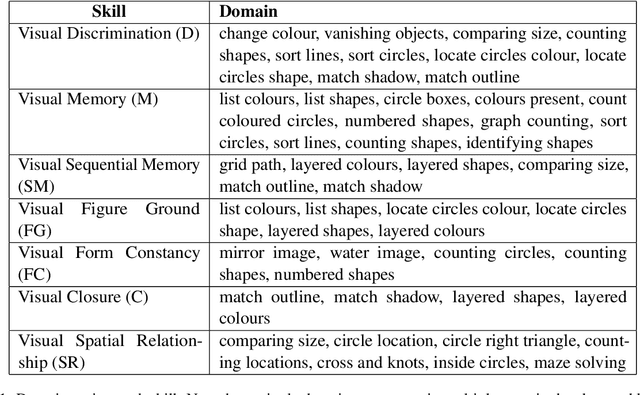

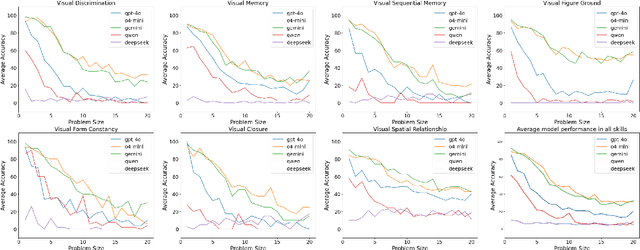
The reasoning abilities of Multimodal Large Language Models (MLLMs) have garnered a lot of attention in recent times, with advances made in frontiers like coding, mathematics, and science. However, very limited experiments have been done to assess their performance in simple perception tasks performed over uncontaminated, generated images containing basic shapes and structures. To address this issue, the paper introduces a dataset, Percept-V, containing a total of 7200 program-generated images equally divided into 30 categories, each testing a combination of visual perception skills. Unlike previously proposed datasets, Percept-V comprises very basic tasks of varying complexity that test the perception abilities of MLLMs. This dataset is then tested on state-of-the-art MLLMs like GPT-4o, Gemini, and Claude as well as Large Reasoning Models (LRMs) like OpenAI o4-mini and DeepSeek R1 to gauge their performance. Contrary to the evidence that MLLMs excel in many complex tasks, our experiments show a significant drop in the models' performance with increasing problem complexity across all categories. An analysis of the performances also reveals that the tested MLLMs exhibit a similar trend in accuracy across categories, testing a particular cognitive skill and find some skills to be more difficult than others.
CETBench: A Novel Dataset constructed via Transformations over Programs for Benchmarking LLMs for Code-Equivalence Checking
Jun 04, 2025


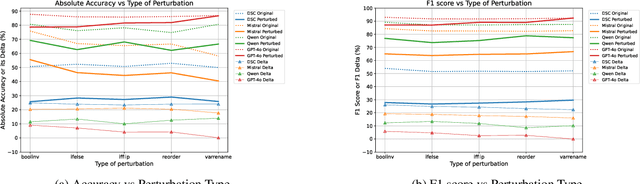
LLMs have been extensively used for the task of automated code generation. In this work, we examine the applicability of LLMs for the related but relatively unexplored task of code-equivalence checking, i.e., given two programs, whether they are functionally equivalent or not. This is an important problem since benchmarking code equivalence can play a critical role in evaluating LLM capabilities for tasks such as code re-writing and code translation. Towards this end, we present CETBench - Code Equivalence with Transformations Benchmark, constructed via a repository of programs, where two programs in the repository may be solving the same or different tasks. Each instance in our dataset is obtained by taking a pair of programs in the repository and applying a random series of pre-defined code transformations, resulting in (non-)equivalent pairs. Our analysis on this dataset reveals a surprising finding that very simple code transformations in the underlying pair of programs can result in a significant drop in performance of SOTA LLMs for the task of code-equivalence checking. To remedy this, we present a simple fine-tuning-based approach to boost LLM performance on the transformed pairs of programs. Our approach for dataset generation is generic, and can be used with repositories with varying program difficulty levels and allows for applying varying numbers as well as kinds of transformations. In our experiments, we perform ablations over the difficulty level of original programs, as well as the kind of transformations used in generating pairs for equivalence checking. Our analysis presents deep insights into the working of LLMs for the task of code-equivalence, and points to the fact that they may still be far from what could be termed as a semantic understanding of the underlying code.
GraPE: A Generate-Plan-Edit Framework for Compositional T2I Synthesis
Dec 08, 2024
Text-to-image (T2I) generation has seen significant progress with diffusion models, enabling generation of photo-realistic images from text prompts. Despite this progress, existing methods still face challenges in following complex text prompts, especially those requiring compositional and multi-step reasoning. Given such complex instructions, SOTA models often make mistakes in faithfully modeling object attributes, and relationships among them. In this work, we present an alternate paradigm for T2I synthesis, decomposing the task of complex multi-step generation into three steps, (a) Generate: we first generate an image using existing diffusion models (b) Plan: we make use of Multi-Modal LLMs (MLLMs) to identify the mistakes in the generated image expressed in terms of individual objects and their properties, and produce a sequence of corrective steps required in the form of an edit-plan. (c) Edit: we make use of an existing text-guided image editing models to sequentially execute our edit-plan over the generated image to get the desired image which is faithful to the original instruction. Our approach derives its strength from the fact that it is modular in nature, is training free, and can be applied over any combination of image generation and editing models. As an added contribution, we also develop a model capable of compositional editing, which further helps improve the overall accuracy of our proposed approach. Our method flexibly trades inference time compute with performance on compositional text prompts. We perform extensive experimental evaluation across 3 benchmarks and 10 T2I models including DALLE-3 and the latest -- SD-3.5-Large. Our approach not only improves the performance of the SOTA models, by upto 3 points, it also reduces the performance gap between weaker and stronger models. $\href{https://dair-iitd.github.io/GraPE/}{https://dair-iitd.github.io/GraPE/}$
Towards Unbiased and Robust Spatio-Temporal Scene Graph Generation and Anticipation
Nov 20, 2024
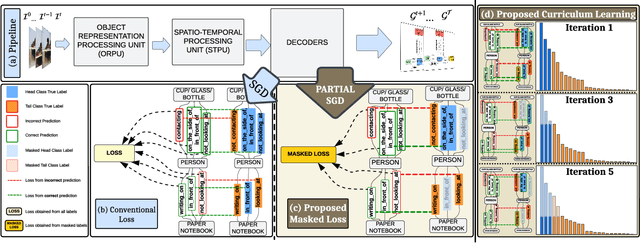
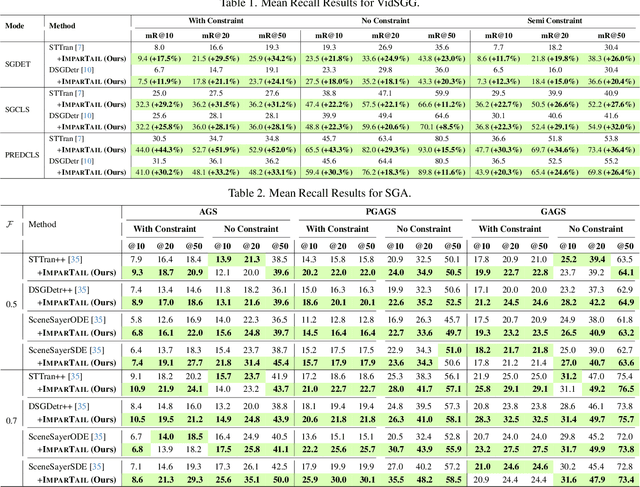

Spatio-Temporal Scene Graphs (STSGs) provide a concise and expressive representation of dynamic scenes by modelling objects and their evolving relationships over time. However, real-world visual relationships often exhibit a long-tailed distribution, causing existing methods for tasks like Video Scene Graph Generation (VidSGG) and Scene Graph Anticipation (SGA) to produce biased scene graphs. To this end, we propose ImparTail, a novel training framework that leverages curriculum learning and loss masking to mitigate bias in the generation and anticipation of spatio-temporal scene graphs. Our approach gradually decreases the dominance of the head relationship classes during training and focuses more on tail classes, leading to more balanced training. Furthermore, we introduce two new tasks, Robust Spatio-Temporal Scene Graph Generation and Robust Scene Graph Anticipation, designed to evaluate the robustness of STSG models against distribution shifts. Extensive experiments on the Action Genome dataset demonstrate that our framework significantly enhances the unbiased performance and robustness of STSG models compared to existing methods.
Learning Disentangled Representation in Object-Centric Models for Visual Dynamics Prediction via Transformers
Jul 03, 2024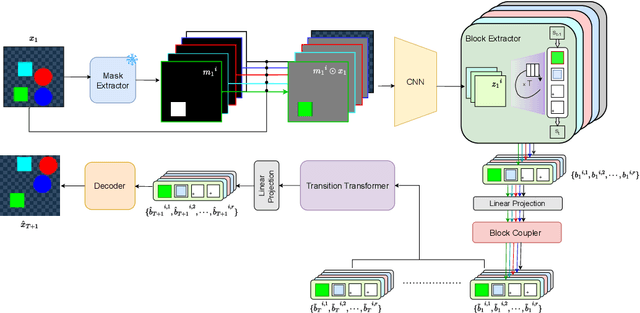
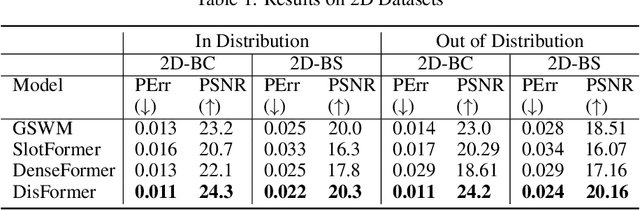
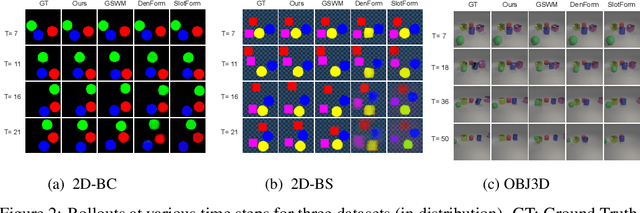
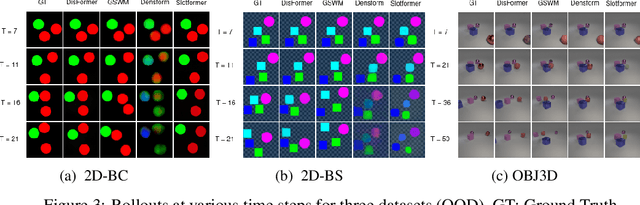
Recent work has shown that object-centric representations can greatly help improve the accuracy of learning dynamics while also bringing interpretability. In this work, we take this idea one step further, ask the following question: "can learning disentangled representation further improve the accuracy of visual dynamics prediction in object-centric models?" While there has been some attempt to learn such disentangled representations for the case of static images \citep{nsb}, to the best of our knowledge, ours is the first work which tries to do this in a general setting for video, without making any specific assumptions about the kind of attributes that an object might have. The key building block of our architecture is the notion of a {\em block}, where several blocks together constitute an object. Each block is represented as a linear combination of a given number of learnable concept vectors, which is iteratively refined during the learning process. The blocks in our model are discovered in an unsupervised manner, by attending over object masks, in a style similar to discovery of slots \citep{slot_attention}, for learning a dense object-centric representation. We employ self-attention via transformers over the discovered blocks to predict the next state resulting in discovery of visual dynamics. We perform a series of experiments on several benchmark 2-D, and 3-D datasets demonstrating that our architecture (1) can discover semantically meaningful blocks (2) help improve accuracy of dynamics prediction compared to SOTA object-centric models (3) perform significantly better in OOD setting where the specific attribute combinations are not seen earlier during training. Our experiments highlight the importance discovery of disentangled representation for visual dynamics prediction.
Simple Augmentations of Logical Rules for Neuro-Symbolic Knowledge Graph Completion
Jul 02, 2024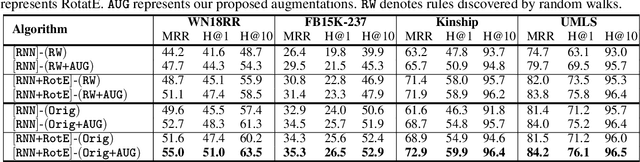
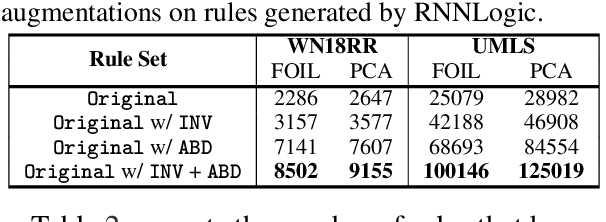
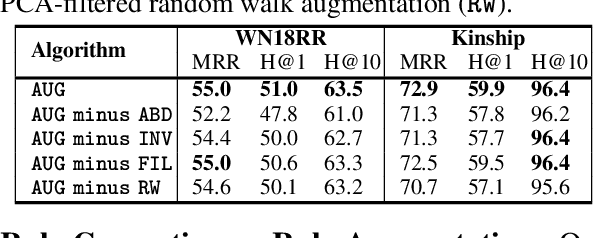
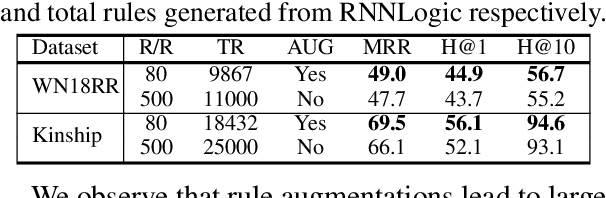
High-quality and high-coverage rule sets are imperative to the success of Neuro-Symbolic Knowledge Graph Completion (NS-KGC) models, because they form the basis of all symbolic inferences. Recent literature builds neural models for generating rule sets, however, preliminary experiments show that they struggle with maintaining high coverage. In this work, we suggest three simple augmentations to existing rule sets: (1) transforming rules to their abductive forms, (2) generating equivalent rules that use inverse forms of constituent relations and (3) random walks that propose new rules. Finally, we prune potentially low quality rules. Experiments over four datasets and five ruleset-baseline settings suggest that these simple augmentations consistently improve results, and obtain up to 7.1 pt MRR and 8.5 pt Hits@1 gains over using rules without augmentations.
SSP: Self-Supervised Prompting for Cross-Lingual Transfer to Low-Resource Languages using Large Language Models
Jun 27, 2024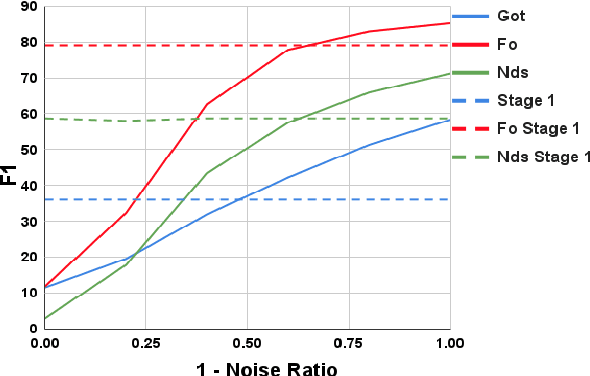
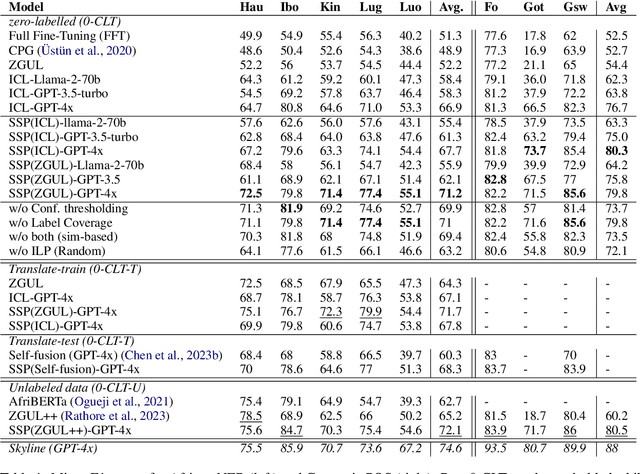
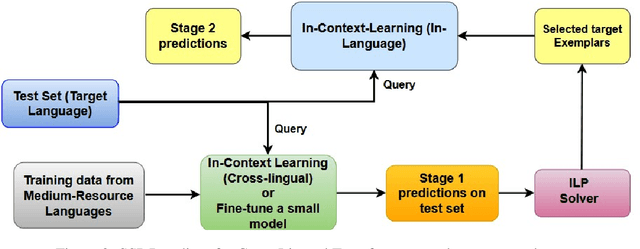
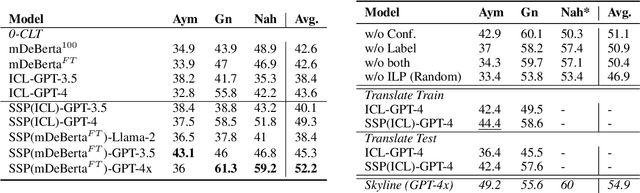
Recently, very large language models (LLMs) have shown exceptional performance on several English NLP tasks with just in-context learning (ICL), but their utility in other languages is still underexplored. We investigate their effectiveness for NLP tasks in low-resource languages (LRLs), especially in the setting of zero-labelled cross-lingual transfer (0-CLT), where no labelled training data for the target language is available -- however training data from one or more related medium-resource languages (MRLs) is utilized, alongside the available unlabeled test data for a target language. We introduce Self-Supervised Prompting (SSP), a novel ICL approach tailored for the 0-CLT setting. SSP is based on the key observation that LLMs output more accurate labels if in-context exemplars are from the target language (even if their labels are slightly noisy). To operationalize this, since target language training data is not available in 0-CLT, SSP operates in two stages. In Stage I, using source MRL training data, target language's test data is noisily labeled. In Stage II, these noisy test data points are used as exemplars in ICL for further improved labelling. Additionally, our implementation of SSP uses a novel Integer Linear Programming (ILP)-based exemplar selection that balances similarity, prediction confidence (when available) and label coverage. Experiments on three tasks and eleven LRLs (from three regions) demonstrate that SSP strongly outperforms existing SOTA fine-tuned and prompting-based baselines in 0-CLT setup.
Learning to Recover from Plan Execution Errors during Robot Manipulation: A Neuro-symbolic Approach
May 29, 2024

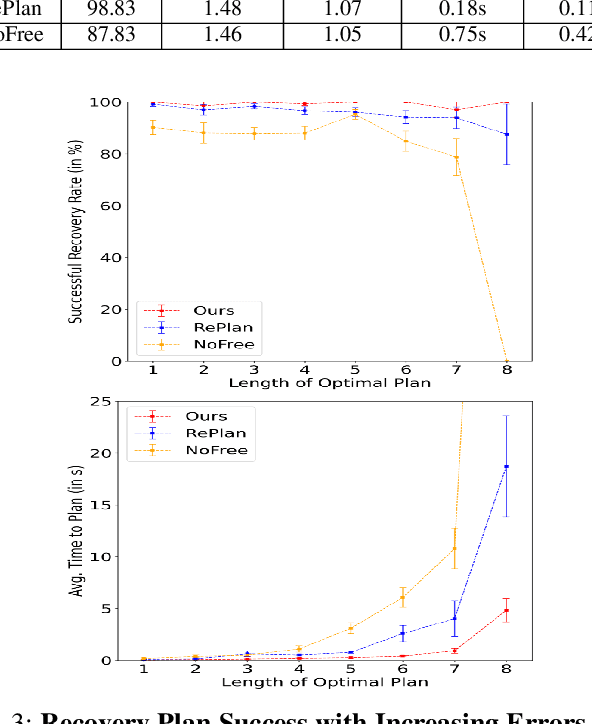

Automatically detecting and recovering from failures is an important but challenging problem for autonomous robots. Most of the recent work on learning to plan from demonstrations lacks the ability to detect and recover from errors in the absence of an explicit state representation and/or a (sub-) goal check function. We propose an approach (blending learning with symbolic search) for automated error discovery and recovery, without needing annotated data of failures. Central to our approach is a neuro-symbolic state representation, in the form of dense scene graph, structured based on the objects present within the environment. This enables efficient learning of the transition function and a discriminator that not only identifies failures but also localizes them facilitating fast re-planning via computation of heuristic distance function. We also present an anytime version of our algorithm, where instead of recovering to the last correct state, we search for a sub-goal in the original plan minimizing the total distance to the goal given a re-planning budget. Experiments on a physics simulator with a variety of simulated failures show the effectiveness of our approach compared to existing baselines, both in terms of efficiency as well as accuracy of our recovery mechanism.
Sketch-Plan-Generalize: Continual Few-Shot Learning of Inductively Generalizable Spatial Concepts for Language-Guided Robot Manipulation
Apr 11, 2024



Our goal is to build embodied agents that can learn inductively generalizable spatial concepts in a continual manner, e.g, constructing a tower of a given height. Existing work suffers from certain limitations (a) (Liang et al., 2023) and their multi-modal extensions, rely heavily on prior knowledge and are not grounded in the demonstrations (b) (Liu et al., 2023) lack the ability to generalize due to their purely neural approach. A key challenge is to achieve a fine balance between symbolic representations which have the capability to generalize, and neural representations that are physically grounded. In response, we propose a neuro-symbolic approach by expressing inductive concepts as symbolic compositions over grounded neural concepts. Our key insight is to decompose the concept learning problem into the following steps 1) Sketch: Getting a programmatic representation for the given instruction 2) Plan: Perform Model-Based RL over the sequence of grounded neural action concepts to learn a grounded plan 3) Generalize: Abstract out a generic (lifted) Python program to facilitate generalizability. Continual learning is achieved by interspersing learning of grounded neural concepts with higher level symbolic constructs. Our experiments demonstrate that our approach significantly outperforms existing baselines in terms of its ability to learn novel concepts and generalize inductively.