 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlow Policy Gradients for Robot Control
Feb 02, 2026Likelihood-based policy gradient methods are the dominant approach for training robot control policies from rewards. These methods rely on differentiable action likelihoods, which constrain policy outputs to simple distributions like Gaussians. In this work, we show how flow matching policy gradients -- a recent framework that bypasses likelihood computation -- can be made effective for training and fine-tuning more expressive policies in challenging robot control settings. We introduce an improved objective that enables success in legged locomotion, humanoid motion tracking, and manipulation tasks, as well as robust sim-to-real transfer on two humanoid robots. We then present ablations and analysis on training dynamics. Results show how policies can exploit the flow representation for exploration when training from scratch, as well as improved fine-tuning robustness over baselines.
Tracking by Predicting 3-D Gaussians Over Time
Dec 30, 2025We propose Video Gaussian Masked Autoencoders (Video-GMAE), a self-supervised approach for representation learning that encodes a sequence of images into a set of Gaussian splats moving over time. Representing a video as a set of Gaussians enforces a reasonable inductive bias: that 2-D videos are often consistent projections of a dynamic 3-D scene. We find that tracking emerges when pretraining a network with this architecture. Mapping the trajectory of the learnt Gaussians onto the image plane gives zero-shot tracking performance comparable to state-of-the-art. With small-scale finetuning, our models achieve 34.6% improvement on Kinetics, and 13.1% on Kubric datasets, surpassing existing self-supervised video approaches. The project page and code are publicly available at https://videogmae.org/ and https://github.com/tekotan/video-gmae.
Deep Sensorimotor Control by Imitating Predictive Models of Human Motion
Aug 26, 2025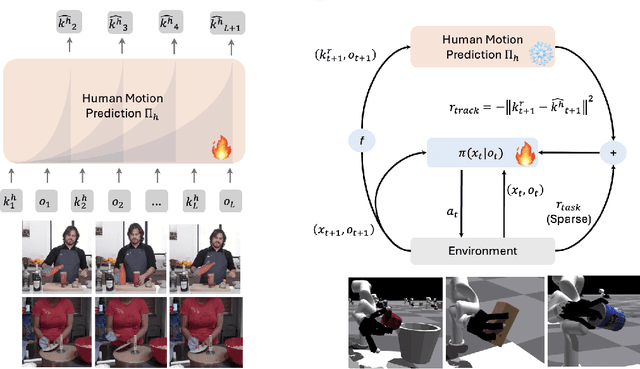
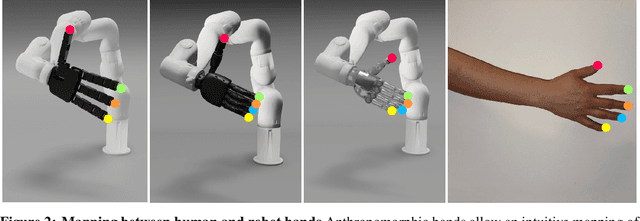
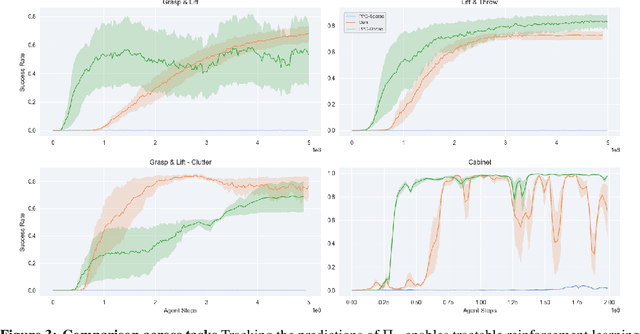
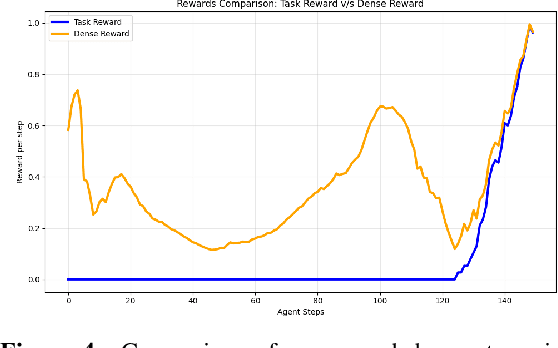
As the embodiment gap between a robot and a human narrows, new opportunities arise to leverage datasets of humans interacting with their surroundings for robot learning. We propose a novel technique for training sensorimotor policies with reinforcement learning by imitating predictive models of human motions. Our key insight is that the motion of keypoints on human-inspired robot end-effectors closely mirrors the motion of corresponding human body keypoints. This enables us to use a model trained to predict future motion on human data \emph{zero-shot} on robot data. We train sensorimotor policies to track the predictions of such a model, conditioned on a history of past robot states, while optimizing a relatively sparse task reward. This approach entirely bypasses gradient-based kinematic retargeting and adversarial losses, which limit existing methods from fully leveraging the scale and diversity of modern human-scene interaction datasets. Empirically, we find that our approach can work across robots and tasks, outperforming existing baselines by a large margin. In addition, we find that tracking a human motion model can substitute for carefully designed dense rewards and curricula in manipulation tasks. Code, data and qualitative results available at https://jirl-upenn.github.io/track_reward/.
End-to-End Navigation with Vision Language Models: Transforming Spatial Reasoning into Question-Answering
Nov 08, 2024
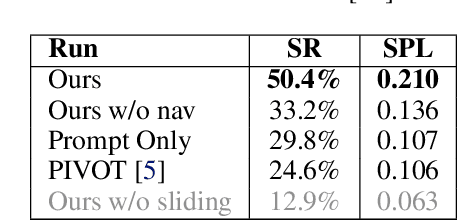

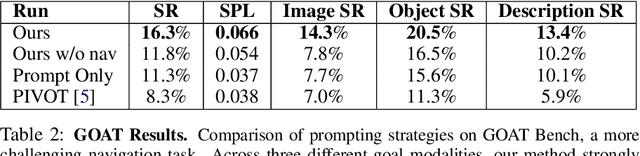
We present VLMnav, an embodied framework to transform a Vision-Language Model (VLM) into an end-to-end navigation policy. In contrast to prior work, we do not rely on a separation between perception, planning, and control; instead, we use a VLM to directly select actions in one step. Surprisingly, we find that a VLM can be used as an end-to-end policy zero-shot, i.e., without any fine-tuning or exposure to navigation data. This makes our approach open-ended and generalizable to any downstream navigation task. We run an extensive study to evaluate the performance of our approach in comparison to baseline prompting methods. In addition, we perform a design analysis to understand the most impactful design decisions. Visual examples and code for our project can be found at https://jirl-upenn.github.io/VLMnav/
Hand-Object Interaction Pretraining from Videos
Sep 12, 2024

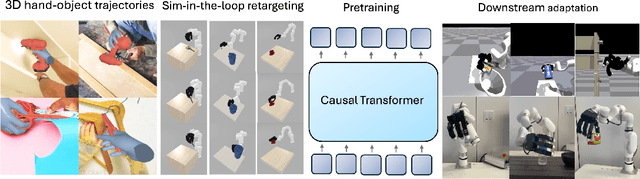

We present an approach to learn general robot manipulation priors from 3D hand-object interaction trajectories. We build a framework to use in-the-wild videos to generate sensorimotor robot trajectories. We do so by lifting both the human hand and the manipulated object in a shared 3D space and retargeting human motions to robot actions. Generative modeling on this data gives us a task-agnostic base policy. This policy captures a general yet flexible manipulation prior. We empirically demonstrate that finetuning this policy, with both reinforcement learning (RL) and behavior cloning (BC), enables sample-efficient adaptation to downstream tasks and simultaneously improves robustness and generalizability compared to prior approaches. Qualitative experiments are available at: \url{https://hgaurav2k.github.io/hop/}.
Learning to Recover from Plan Execution Errors during Robot Manipulation: A Neuro-symbolic Approach
May 29, 2024

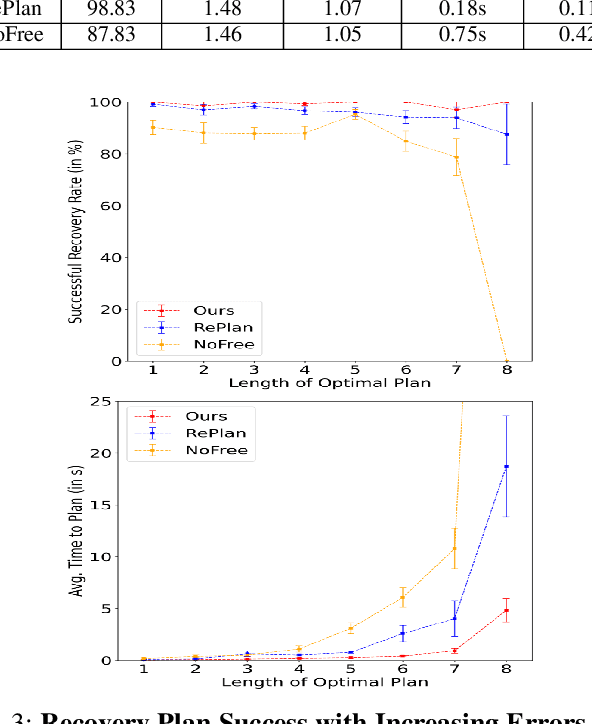

Automatically detecting and recovering from failures is an important but challenging problem for autonomous robots. Most of the recent work on learning to plan from demonstrations lacks the ability to detect and recover from errors in the absence of an explicit state representation and/or a (sub-) goal check function. We propose an approach (blending learning with symbolic search) for automated error discovery and recovery, without needing annotated data of failures. Central to our approach is a neuro-symbolic state representation, in the form of dense scene graph, structured based on the objects present within the environment. This enables efficient learning of the transition function and a discriminator that not only identifies failures but also localizes them facilitating fast re-planning via computation of heuristic distance function. We also present an anytime version of our algorithm, where instead of recovering to the last correct state, we search for a sub-goal in the original plan minimizing the total distance to the goal given a re-planning budget. Experiments on a physics simulator with a variety of simulated failures show the effectiveness of our approach compared to existing baselines, both in terms of efficiency as well as accuracy of our recovery mechanism.
Sketch-Plan-Generalize: Continual Few-Shot Learning of Inductively Generalizable Spatial Concepts for Language-Guided Robot Manipulation
Apr 11, 2024



Our goal is to build embodied agents that can learn inductively generalizable spatial concepts in a continual manner, e.g, constructing a tower of a given height. Existing work suffers from certain limitations (a) (Liang et al., 2023) and their multi-modal extensions, rely heavily on prior knowledge and are not grounded in the demonstrations (b) (Liu et al., 2023) lack the ability to generalize due to their purely neural approach. A key challenge is to achieve a fine balance between symbolic representations which have the capability to generalize, and neural representations that are physically grounded. In response, we propose a neuro-symbolic approach by expressing inductive concepts as symbolic compositions over grounded neural concepts. Our key insight is to decompose the concept learning problem into the following steps 1) Sketch: Getting a programmatic representation for the given instruction 2) Plan: Perform Model-Based RL over the sequence of grounded neural action concepts to learn a grounded plan 3) Generalize: Abstract out a generic (lifted) Python program to facilitate generalizability. Continual learning is achieved by interspersing learning of grounded neural concepts with higher level symbolic constructs. Our experiments demonstrate that our approach significantly outperforms existing baselines in terms of its ability to learn novel concepts and generalize inductively.
Have LLMs Advanced Enough? A Challenging Problem Solving Benchmark For Large Language Models
May 24, 2023The performance on Large Language Models (LLMs) on existing reasoning benchmarks has shot up considerably over the past years. In response, we present JEEBench, a considerably more challenging benchmark dataset for evaluating the problem solving abilities of LLMs. We curate 450 challenging pre-engineering mathematics, physics and chemistry problems from the IIT JEE-Advanced exam. Long-horizon reasoning on top of deep in-domain knowledge is essential for solving problems in this benchmark. Our evaluation on the GPT series of models reveals that although performance improves with newer models, the best being GPT-4, the highest performance, even after using techniques like Self-Consistency and Chain-of-Thought prompting is less than 40 percent. Our analysis demonstrates that errors in algebraic manipulation and failure in retrieving relevant domain specific concepts are primary contributors to GPT4's low performance. Given the challenging nature of the benchmark, we hope that it can guide future research in problem solving using LLMs. Our code and dataset is available here.