 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgile Flight Emerges from Multi-Agent Competitive Racing
Dec 12, 2025Through multi-agent competition and the sparse high-level objective of winning a race, we find that both agile flight (e.g., high-speed motion pushing the platform to its physical limits) and strategy (e.g., overtaking or blocking) emerge from agents trained with reinforcement learning. We provide evidence in both simulation and the real world that this approach outperforms the common paradigm of training agents in isolation with rewards that prescribe behavior, e.g., progress on the raceline, in particular when the complexity of the environment increases, e.g., in the presence of obstacles. Moreover, we find that multi-agent competition yields policies that transfer more reliably to the real world than policies trained with a single-agent progress-based reward, despite the two methods using the same simulation environment, randomization strategy, and hardware. In addition to improved sim-to-real transfer, the multi-agent policies also exhibit some degree of generalization to opponents unseen at training time. Overall, our work, following in the tradition of multi-agent competitive game-play in digital domains, shows that sparse task-level rewards are sufficient for training agents capable of advanced low-level control in the physical world. Code: https://github.com/Jirl-upenn/AgileFlight_MultiAgent
Deep Sensorimotor Control by Imitating Predictive Models of Human Motion
Aug 26, 2025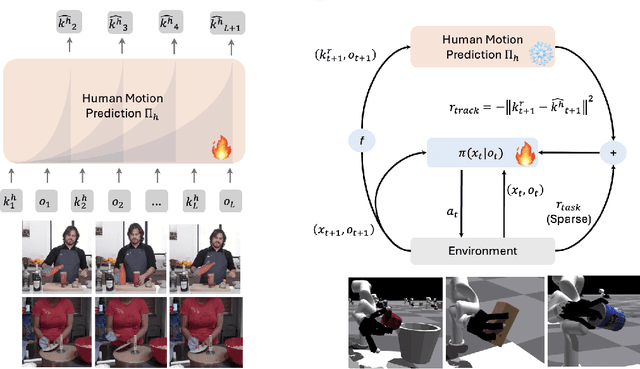
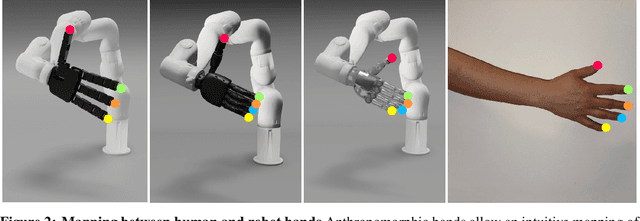
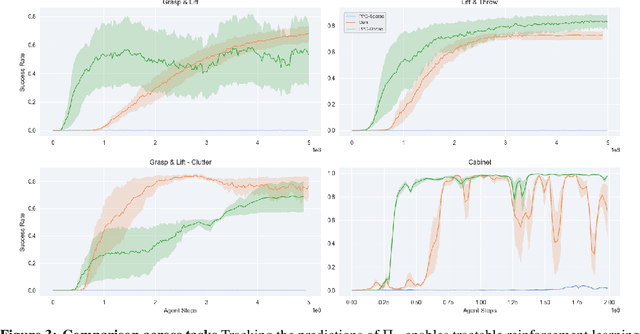
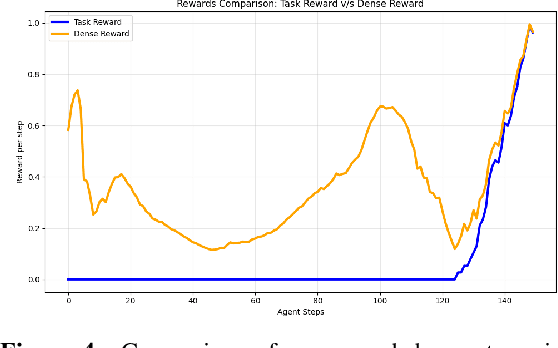
As the embodiment gap between a robot and a human narrows, new opportunities arise to leverage datasets of humans interacting with their surroundings for robot learning. We propose a novel technique for training sensorimotor policies with reinforcement learning by imitating predictive models of human motions. Our key insight is that the motion of keypoints on human-inspired robot end-effectors closely mirrors the motion of corresponding human body keypoints. This enables us to use a model trained to predict future motion on human data \emph{zero-shot} on robot data. We train sensorimotor policies to track the predictions of such a model, conditioned on a history of past robot states, while optimizing a relatively sparse task reward. This approach entirely bypasses gradient-based kinematic retargeting and adversarial losses, which limit existing methods from fully leveraging the scale and diversity of modern human-scene interaction datasets. Empirically, we find that our approach can work across robots and tasks, outperforming existing baselines by a large margin. In addition, we find that tracking a human motion model can substitute for carefully designed dense rewards and curricula in manipulation tasks. Code, data and qualitative results available at https://jirl-upenn.github.io/track_reward/.
Hearing Hands: Generating Sounds from Physical Interactions in 3D Scenes
Jun 11, 2025We study the problem of making 3D scene reconstructions interactive by asking the following question: can we predict the sounds of human hands physically interacting with a scene? First, we record a video of a human manipulating objects within a 3D scene using their hands. We then use these action-sound pairs to train a rectified flow model to map 3D hand trajectories to their corresponding audio. At test time, a user can query the model for other actions, parameterized as sequences of hand poses, to estimate their corresponding sounds. In our experiments, we find that our generated sounds accurately convey material properties and actions, and that they are often indistinguishable to human observers from real sounds. Project page: https://www.yimingdou.com/hearing_hands/
End-to-End Navigation with Vision Language Models: Transforming Spatial Reasoning into Question-Answering
Nov 08, 2024
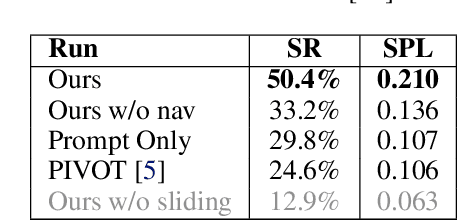

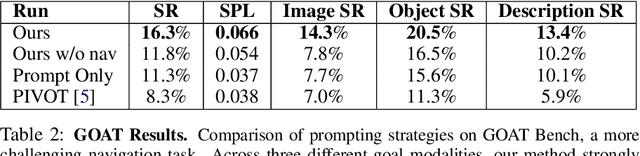
We present VLMnav, an embodied framework to transform a Vision-Language Model (VLM) into an end-to-end navigation policy. In contrast to prior work, we do not rely on a separation between perception, planning, and control; instead, we use a VLM to directly select actions in one step. Surprisingly, we find that a VLM can be used as an end-to-end policy zero-shot, i.e., without any fine-tuning or exposure to navigation data. This makes our approach open-ended and generalizable to any downstream navigation task. We run an extensive study to evaluate the performance of our approach in comparison to baseline prompting methods. In addition, we perform a design analysis to understand the most impactful design decisions. Visual examples and code for our project can be found at https://jirl-upenn.github.io/VLMnav/
Hand-Object Interaction Pretraining from Videos
Sep 12, 2024

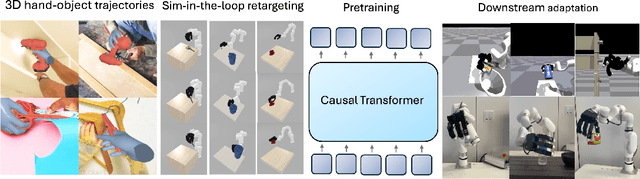

We present an approach to learn general robot manipulation priors from 3D hand-object interaction trajectories. We build a framework to use in-the-wild videos to generate sensorimotor robot trajectories. We do so by lifting both the human hand and the manipulated object in a shared 3D space and retargeting human motions to robot actions. Generative modeling on this data gives us a task-agnostic base policy. This policy captures a general yet flexible manipulation prior. We empirically demonstrate that finetuning this policy, with both reinforcement learning (RL) and behavior cloning (BC), enables sample-efficient adaptation to downstream tasks and simultaneously improves robustness and generalizability compared to prior approaches. Qualitative experiments are available at: \url{https://hgaurav2k.github.io/hop/}.
Tactile-Augmented Radiance Fields
May 07, 2024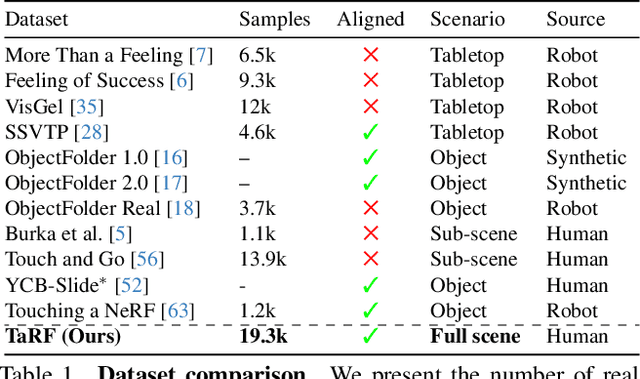

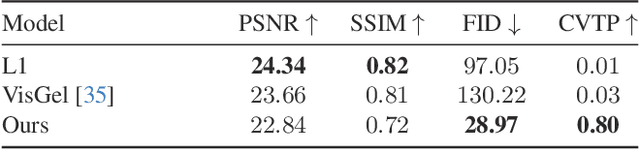

We present a scene representation, which we call a tactile-augmented radiance field (TaRF), that brings vision and touch into a shared 3D space. This representation can be used to estimate the visual and tactile signals for a given 3D position within a scene. We capture a scene's TaRF from a collection of photos and sparsely sampled touch probes. Our approach makes use of two insights: (i) common vision-based touch sensors are built on ordinary cameras and thus can be registered to images using methods from multi-view geometry, and (ii) visually and structurally similar regions of a scene share the same tactile features. We use these insights to register touch signals to a captured visual scene, and to train a conditional diffusion model that, provided with an RGB-D image rendered from a neural radiance field, generates its corresponding tactile signal. To evaluate our approach, we collect a dataset of TaRFs. This dataset contains more touch samples than previous real-world datasets, and it provides spatially aligned visual signals for each captured touch signal. We demonstrate the accuracy of our cross-modal generative model and the utility of the captured visual-tactile data on several downstream tasks. Project page: https://dou-yiming.github.io/TaRF
EgoPet: Egomotion and Interaction Data from an Animal's Perspective
Apr 15, 2024

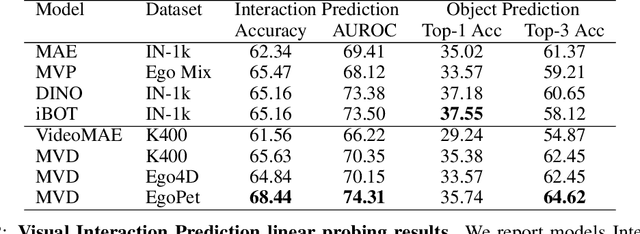

Animals perceive the world to plan their actions and interact with other agents to accomplish complex tasks, demonstrating capabilities that are still unmatched by AI systems. To advance our understanding and reduce the gap between the capabilities of animals and AI systems, we introduce a dataset of pet egomotion imagery with diverse examples of simultaneous egomotion and multi-agent interaction. Current video datasets separately contain egomotion and interaction examples, but rarely both at the same time. In addition, EgoPet offers a radically distinct perspective from existing egocentric datasets of humans or vehicles. We define two in-domain benchmark tasks that capture animal behavior, and a third benchmark to assess the utility of EgoPet as a pretraining resource to robotic quadruped locomotion, showing that models trained from EgoPet outperform those trained from prior datasets.
Conformal Policy Learning for Sensorimotor Control Under Distribution Shifts
Nov 02, 2023This paper focuses on the problem of detecting and reacting to changes in the distribution of a sensorimotor controller's observables. The key idea is the design of switching policies that can take conformal quantiles as input, which we define as conformal policy learning, that allows robots to detect distribution shifts with formal statistical guarantees. We show how to design such policies by using conformal quantiles to switch between base policies with different characteristics, e.g. safety or speed, or directly augmenting a policy observation with a quantile and training it with reinforcement learning. Theoretically, we show that such policies achieve the formal convergence guarantees in finite time. In addition, we thoroughly evaluate their advantages and limitations on two compelling use cases: simulated autonomous driving and active perception with a physical quadruped. Empirical results demonstrate that our approach outperforms five baselines. It is also the simplest of the baseline strategies besides one ablation. Being easy to use, flexible, and with formal guarantees, our work demonstrates how conformal prediction can be an effective tool for sensorimotor learning under uncertainty.
A Remote Sim2real Aerial Competition: Fostering Reproducibility and Solutions' Diversity in Robotics Challenges
Aug 31, 2023

Shared benchmark problems have historically been a fundamental driver of progress for scientific communities. In the context of academic conferences, competitions offer the opportunity to researchers with different origins, backgrounds, and levels of seniority to quantitatively compare their ideas. In robotics, a hot and challenging topic is sim2real-porting approaches that work well in simulation to real robot hardware. In our case, creating a hybrid competition with both simulation and real robot components was also dictated by the uncertainties around travel and logistics in the post-COVID-19 world. Hence, this article motivates and describes an aerial sim2real robot competition that ran during the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems, from the specification of the competition task, to the details of the software infrastructure supporting simulation and real-life experiments, to the approaches of the top-placed teams and the lessons learned by participants and organizers.
Learning Vision-based Pursuit-Evasion Robot Policies
Aug 30, 2023Learning strategic robot behavior -- like that required in pursuit-evasion interactions -- under real-world constraints is extremely challenging. It requires exploiting the dynamics of the interaction, and planning through both physical state and latent intent uncertainty. In this paper, we transform this intractable problem into a supervised learning problem, where a fully-observable robot policy generates supervision for a partially-observable one. We find that the quality of the supervision signal for the partially-observable pursuer policy depends on two key factors: the balance of diversity and optimality of the evader's behavior and the strength of the modeling assumptions in the fully-observable policy. We deploy our policy on a physical quadruped robot with an RGB-D camera on pursuit-evasion interactions in the wild. Despite all the challenges, the sensing constraints bring about creativity: the robot is pushed to gather information when uncertain, predict intent from noisy measurements, and anticipate in order to intercept. Project webpage: https://abajcsy.github.io/vision-based-pursuit/