 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTactile-Augmented Radiance Fields
Paper and Code
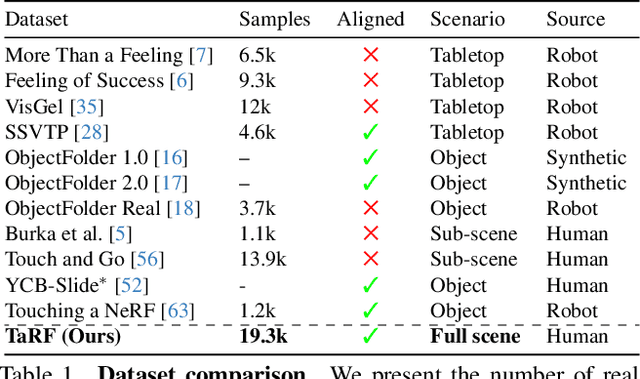

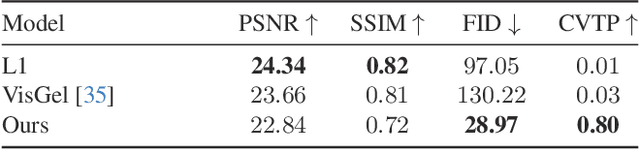

We present a scene representation, which we call a tactile-augmented radiance field (TaRF), that brings vision and touch into a shared 3D space. This representation can be used to estimate the visual and tactile signals for a given 3D position within a scene. We capture a scene's TaRF from a collection of photos and sparsely sampled touch probes. Our approach makes use of two insights: (i) common vision-based touch sensors are built on ordinary cameras and thus can be registered to images using methods from multi-view geometry, and (ii) visually and structurally similar regions of a scene share the same tactile features. We use these insights to register touch signals to a captured visual scene, and to train a conditional diffusion model that, provided with an RGB-D image rendered from a neural radiance field, generates its corresponding tactile signal. To evaluate our approach, we collect a dataset of TaRFs. This dataset contains more touch samples than previous real-world datasets, and it provides spatially aligned visual signals for each captured touch signal. We demonstrate the accuracy of our cross-modal generative model and the utility of the captured visual-tactile data on several downstream tasks. Project page: https://dou-yiming.github.io/TaRF