 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHearing Hands: Generating Sounds from Physical Interactions in 3D Scenes
Jun 11, 2025We study the problem of making 3D scene reconstructions interactive by asking the following question: can we predict the sounds of human hands physically interacting with a scene? First, we record a video of a human manipulating objects within a 3D scene using their hands. We then use these action-sound pairs to train a rectified flow model to map 3D hand trajectories to their corresponding audio. At test time, a user can query the model for other actions, parameterized as sequences of hand poses, to estimate their corresponding sounds. In our experiments, we find that our generated sounds accurately convey material properties and actions, and that they are often indistinguishable to human observers from real sounds. Project page: https://www.yimingdou.com/hearing_hands/
Contrastive Touch-to-Touch Pretraining
Oct 15, 2024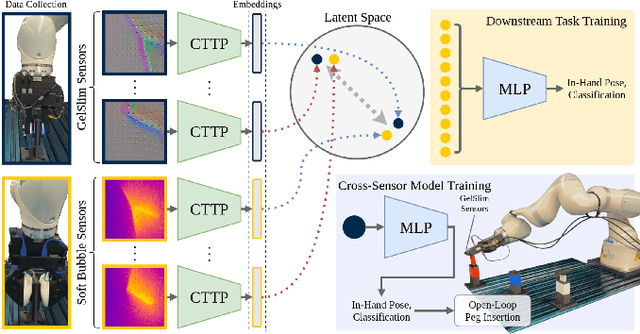
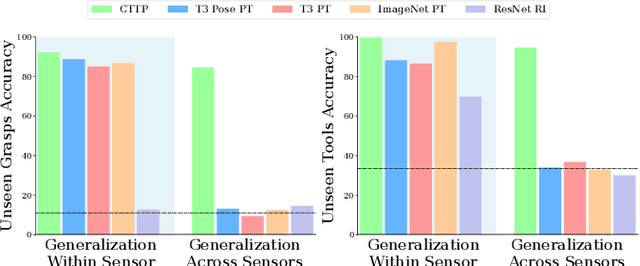
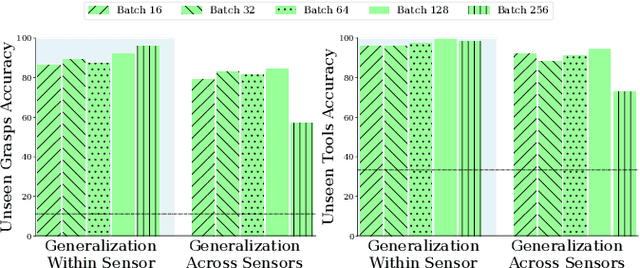

Today's tactile sensors have a variety of different designs, making it challenging to develop general-purpose methods for processing touch signals. In this paper, we learn a unified representation that captures the shared information between different tactile sensors. Unlike current approaches that focus on reconstruction or task-specific supervision, we leverage contrastive learning to integrate tactile signals from two different sensors into a shared embedding space, using a dataset in which the same objects are probed with multiple sensors. We apply this approach to paired touch signals from GelSlim and Soft Bubble sensors. We show that our learned features provide strong pretraining for downstream pose estimation and classification tasks. We also show that our embedding enables models trained using one touch sensor to be deployed using another without additional training. Project details can be found at https://www.mmintlab.com/research/cttp/.
Tactile Functasets: Neural Implicit Representations of Tactile Datasets
Sep 22, 2024
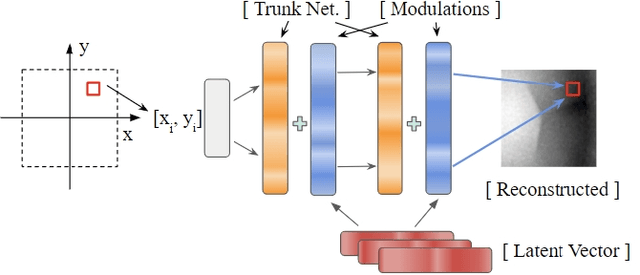


Modern incarnations of tactile sensors produce high-dimensional raw sensory feedback such as images, making it challenging to efficiently store, process, and generalize across sensors. To address these concerns, we introduce a novel implicit function representation for tactile sensor feedback. Rather than directly using raw tactile images, we propose neural implicit functions trained to reconstruct the tactile dataset, producing compact representations that capture the underlying structure of the sensory inputs. These representations offer several advantages over their raw counterparts: they are compact, enable probabilistically interpretable inference, and facilitate generalization across different sensors. We demonstrate the efficacy of this representation on the downstream task of in-hand object pose estimation, achieving improved performance over image-based methods while simplifying downstream models. We release code, demos and datasets at https://www.mmintlab.com/tactile-functasets.
Touch2Touch: Cross-Modal Tactile Generation for Object Manipulation
Sep 12, 2024



Today's touch sensors come in many shapes and sizes. This has made it challenging to develop general-purpose touch processing methods since models are generally tied to one specific sensor design. We address this problem by performing cross-modal prediction between touch sensors: given the tactile signal from one sensor, we use a generative model to estimate how the same physical contact would be perceived by another sensor. This allows us to apply sensor-specific methods to the generated signal. We implement this idea by training a diffusion model to translate between the popular GelSlim and Soft Bubble sensors. As a downstream task, we perform in-hand object pose estimation using GelSlim sensors while using an algorithm that operates only on Soft Bubble signals. The dataset, the code, and additional details can be found at https://www.mmintlab.com/research/touch2touch/.
Tactile-Augmented Radiance Fields
May 07, 2024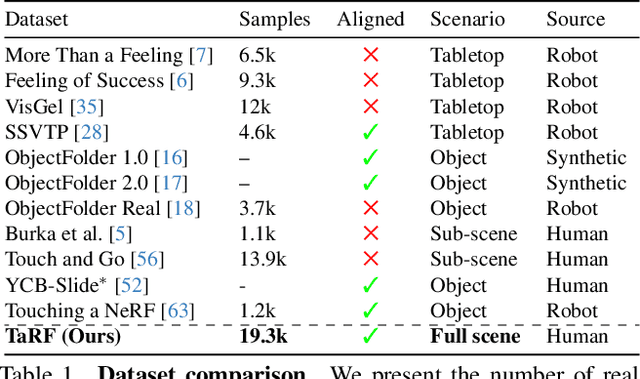

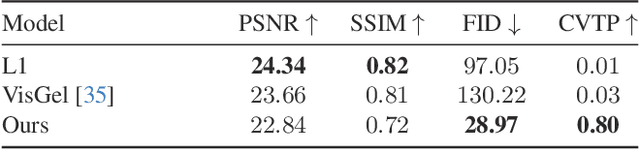

We present a scene representation, which we call a tactile-augmented radiance field (TaRF), that brings vision and touch into a shared 3D space. This representation can be used to estimate the visual and tactile signals for a given 3D position within a scene. We capture a scene's TaRF from a collection of photos and sparsely sampled touch probes. Our approach makes use of two insights: (i) common vision-based touch sensors are built on ordinary cameras and thus can be registered to images using methods from multi-view geometry, and (ii) visually and structurally similar regions of a scene share the same tactile features. We use these insights to register touch signals to a captured visual scene, and to train a conditional diffusion model that, provided with an RGB-D image rendered from a neural radiance field, generates its corresponding tactile signal. To evaluate our approach, we collect a dataset of TaRFs. This dataset contains more touch samples than previous real-world datasets, and it provides spatially aligned visual signals for each captured touch signal. We demonstrate the accuracy of our cross-modal generative model and the utility of the captured visual-tactile data on several downstream tasks. Project page: https://dou-yiming.github.io/TaRF
Binding Touch to Everything: Learning Unified Multimodal Tactile Representations
Jan 31, 2024



The ability to associate touch with other modalities has huge implications for humans and computational systems. However, multimodal learning with touch remains challenging due to the expensive data collection process and non-standardized sensor outputs. We introduce UniTouch, a unified tactile model for vision-based touch sensors connected to multiple modalities, including vision, language, and sound. We achieve this by aligning our UniTouch embeddings to pretrained image embeddings already associated with a variety of other modalities. We further propose learnable sensor-specific tokens, allowing the model to learn from a set of heterogeneous tactile sensors, all at the same time. UniTouch is capable of conducting various touch sensing tasks in the zero-shot setting, from robot grasping prediction to touch image question answering. To the best of our knowledge, UniTouch is the first to demonstrate such capabilities. Project page: https://cfeng16.github.io/UniTouch/
The ObjectFolder Benchmark: Multisensory Learning with Neural and Real Objects
Jun 01, 2023



We introduce the ObjectFolder Benchmark, a benchmark suite of 10 tasks for multisensory object-centric learning, centered around object recognition, reconstruction, and manipulation with sight, sound, and touch. We also introduce the ObjectFolder Real dataset, including the multisensory measurements for 100 real-world household objects, building upon a newly designed pipeline for collecting the 3D meshes, videos, impact sounds, and tactile readings of real-world objects. We conduct systematic benchmarking on both the 1,000 multisensory neural objects from ObjectFolder, and the real multisensory data from ObjectFolder Real. Our results demonstrate the importance of multisensory perception and reveal the respective roles of vision, audio, and touch for different object-centric learning tasks. By publicly releasing our dataset and benchmark suite, we hope to catalyze and enable new research in multisensory object-centric learning in computer vision, robotics, and beyond. Project page: https://objectfolder.stanford.edu
From Isolated Islands to Pangea: Unifying Semantic Space for Human Action Understanding
Apr 04, 2023



Action understanding matters and attracts attention. It can be formed as the mapping from the action physical space to the semantic space. Typically, researchers built action datasets according to idiosyncratic choices to define classes and push the envelope of benchmarks respectively. Thus, datasets are incompatible with each other like "Isolated Islands" due to semantic gaps and various class granularities, e.g., do housework in dataset A and wash plate in dataset B. We argue that a more principled semantic space is an urgent need to concentrate the community efforts and enable us to use all datasets together to pursue generalizable action learning. To this end, we design a Poincare action semantic space given verb taxonomy hierarchy and covering massive actions. By aligning the classes of previous datasets to our semantic space, we gather (image/video/skeleton/MoCap) datasets into a unified database in a unified label system, i.e., bridging "isolated islands" into a "Pangea". Accordingly, we propose a bidirectional mapping model between physical and semantic space to fully use Pangea. In extensive experiments, our system shows significant superiority, especially in transfer learning. Code and data will be made publicly available.
Discovering A Variety of Objects in Spatio-Temporal Human-Object Interactions
Nov 18, 2022


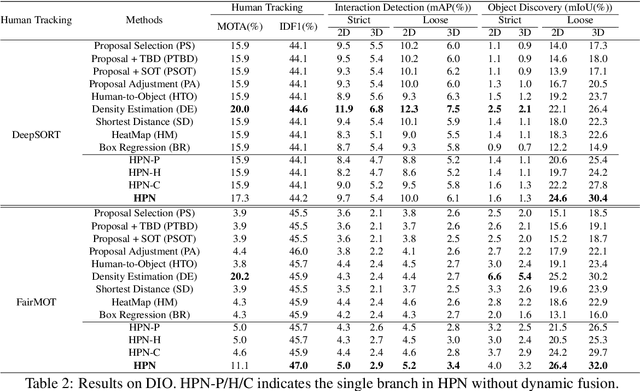
Spatio-temporal Human-Object Interaction (ST-HOI) detection aims at detecting HOIs from videos, which is crucial for activity understanding. In daily HOIs, humans often interact with a variety of objects, e.g., holding and touching dozens of household items in cleaning. However, existing whole body-object interaction video benchmarks usually provide limited object classes. Here, we introduce a new benchmark based on AVA: Discovering Interacted Objects (DIO) including 51 interactions and 1,000+ objects. Accordingly, an ST-HOI learning task is proposed expecting vision systems to track human actors, detect interactions and simultaneously discover interacted objects. Even though today's detectors/trackers excel in object detection/tracking tasks, they perform unsatisfied to localize diverse/unseen objects in DIO. This profoundly reveals the limitation of current vision systems and poses a great challenge. Thus, how to leverage spatio-temporal cues to address object discovery is explored, and a Hierarchical Probe Network (HPN) is devised to discover interacted objects utilizing hierarchical spatio-temporal human/context cues. In extensive experiments, HPN demonstrates impressive performance. Data and code are available at https://github.com/DirtyHarryLYL/HAKE-AVA.