 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVerb Mirage: Unveiling and Assessing Verb Concept Hallucinations in Multimodal Large Language Models
Dec 06, 2024



Multimodal Large Language Models (MLLMs) have garnered significant attention recently and demonstrate outstanding capabilities in various tasks such as OCR, VQA, captioning, $\textit{etc}$. However, hallucination remains a persistent issue. While numerous methods have been proposed to mitigate hallucinations, achieving notable improvements, these methods primarily focus on mitigating hallucinations about $\textbf{object/noun-related}$ concepts. Verb concepts, crucial for understanding human actions, have been largely overlooked. In this paper, to the best of our knowledge, we are the $\textbf{first}$ to investigate the $\textbf{verb hallucination}$ phenomenon of MLLMs from various perspectives. Our findings reveal that most state-of-the-art MLLMs suffer from severe verb hallucination. To assess the effectiveness of existing mitigation methods for object concept hallucination on verb hallucination, we evaluated these methods and found that they do not effectively address verb hallucination. To address this issue, we propose a novel rich verb knowledge-based tuning method to mitigate verb hallucination. The experiment results demonstrate that our method significantly reduces hallucinations related to verbs. $\textit{Our code and data will be made publicly available}$.
Symbol-LLM: Leverage Language Models for Symbolic System in Visual Human Activity Reasoning
Nov 29, 2023



Human reasoning can be understood as a cooperation between the intuitive, associative "System-1" and the deliberative, logical "System-2". For existing System-1-like methods in visual activity understanding, it is crucial to integrate System-2 processing to improve explainability, generalization, and data efficiency. One possible path of activity reasoning is building a symbolic system composed of symbols and rules, where one rule connects multiple symbols, implying human knowledge and reasoning abilities. Previous methods have made progress, but are defective with limited symbols from handcraft and limited rules from visual-based annotations, failing to cover the complex patterns of activities and lacking compositional generalization. To overcome the defects, we propose a new symbolic system with two ideal important properties: broad-coverage symbols and rational rules. Collecting massive human knowledge via manual annotations is expensive to instantiate this symbolic system. Instead, we leverage the recent advancement of LLMs (Large Language Models) as an approximation of the two ideal properties, i.e., Symbols from Large Language Models (Symbol-LLM). Then, given an image, visual contents from the images are extracted and checked as symbols and activity semantics are reasoned out based on rules via fuzzy logic calculation. Our method shows superiority in extensive activity understanding tasks. Code and data are available at https://mvig-rhos.com/symbol_llm.
From Isolated Islands to Pangea: Unifying Semantic Space for Human Action Understanding
Apr 04, 2023



Action understanding matters and attracts attention. It can be formed as the mapping from the action physical space to the semantic space. Typically, researchers built action datasets according to idiosyncratic choices to define classes and push the envelope of benchmarks respectively. Thus, datasets are incompatible with each other like "Isolated Islands" due to semantic gaps and various class granularities, e.g., do housework in dataset A and wash plate in dataset B. We argue that a more principled semantic space is an urgent need to concentrate the community efforts and enable us to use all datasets together to pursue generalizable action learning. To this end, we design a Poincare action semantic space given verb taxonomy hierarchy and covering massive actions. By aligning the classes of previous datasets to our semantic space, we gather (image/video/skeleton/MoCap) datasets into a unified database in a unified label system, i.e., bridging "isolated islands" into a "Pangea". Accordingly, we propose a bidirectional mapping model between physical and semantic space to fully use Pangea. In extensive experiments, our system shows significant superiority, especially in transfer learning. Code and data will be made publicly available.
Mining Cross-Person Cues for Body-Part Interactiveness Learning in HOI Detection
Jul 28, 2022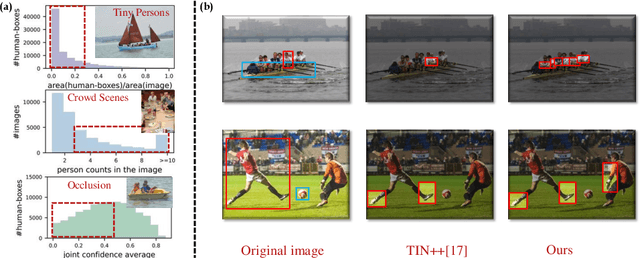


Human-Object Interaction (HOI) detection plays a crucial role in activity understanding. Though significant progress has been made, interactiveness learning remains a challenging problem in HOI detection: existing methods usually generate redundant negative H-O pair proposals and fail to effectively extract interactive pairs. Though interactiveness has been studied in both whole body- and part- level and facilitates the H-O pairing, previous works only focus on the target person once (i.e., in a local perspective) and overlook the information of the other persons. In this paper, we argue that comparing body-parts of multi-person simultaneously can afford us more useful and supplementary interactiveness cues. That said, to learn body-part interactiveness from a global perspective: when classifying a target person's body-part interactiveness, visual cues are explored not only from herself/himself but also from other persons in the image. We construct body-part saliency maps based on self-attention to mine cross-person informative cues and learn the holistic relationships between all the body-parts. We evaluate the proposed method on widely-used benchmarks HICO-DET and V-COCO. With our new perspective, the holistic global-local body-part interactiveness learning achieves significant improvements over state-of-the-art. Our code is available at https://github.com/enlighten0707/Body-Part-Map-for-Interactiveness.
Interactiveness Field in Human-Object Interactions
Apr 16, 2022

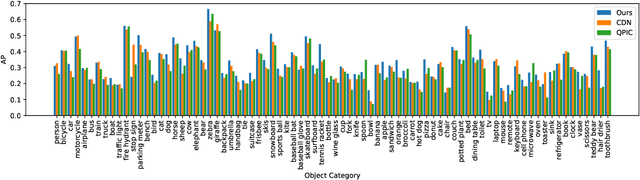

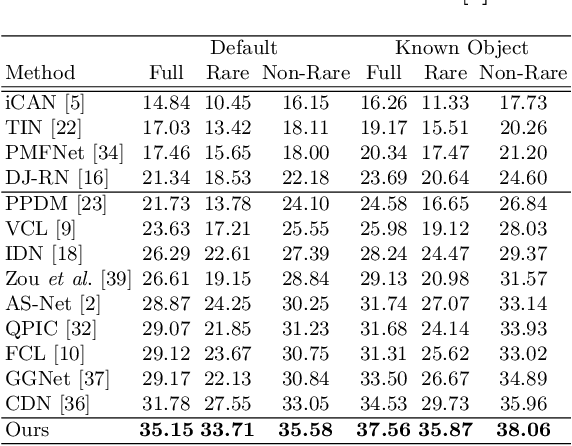
Human-Object Interaction (HOI) detection plays a core role in activity understanding. Though recent two/one-stage methods have achieved impressive results, as an essential step, discovering interactive human-object pairs remains challenging. Both one/two-stage methods fail to effectively extract interactive pairs instead of generating redundant negative pairs. In this work, we introduce a previously overlooked interactiveness bimodal prior: given an object in an image, after pairing it with the humans, the generated pairs are either mostly non-interactive, or mostly interactive, with the former more frequent than the latter. Based on this interactiveness bimodal prior we propose the "interactiveness field". To make the learned field compatible with real HOI image considerations, we propose new energy constraints based on the cardinality and difference in the inherent "interactiveness field" underlying interactive versus non-interactive pairs. Consequently, our method can detect more precise pairs and thus significantly boost HOI detection performance, which is validated on widely-used benchmarks where we achieve decent improvements over state-of-the-arts. Our code is available at https://github.com/Foruck/Interactiveness-Field.
HAKE: A Knowledge Engine Foundation for Human Activity Understanding
Feb 14, 2022



Human activity understanding is of widespread interest in artificial intelligence and spans diverse applications like health care and behavior analysis. Although there have been advances with deep learning, it remains challenging. The object recognition-like solutions usually try to map pixels to semantics directly, but activity patterns are much different from object patterns, thus hindering another success. In this work, we propose a novel paradigm to reformulate this task in two-stage: first mapping pixels to an intermediate space spanned by atomic activity primitives, then programming detected primitives with interpretable logic rules to infer semantics. To afford a representative primitive space, we build a knowledge base including 26+ M primitive labels and logic rules from human priors or automatic discovering. Our framework, Human Activity Knowledge Engine (HAKE), exhibits superior generalization ability and performance upon canonical methods on challenging benchmarks. Code and data are available at http://hake-mvig.cn/.
Transferable Interactiveness Knowledge for Human-Object Interaction Detection
Jan 25, 2021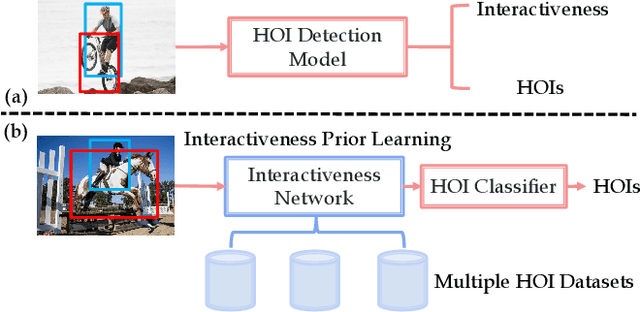
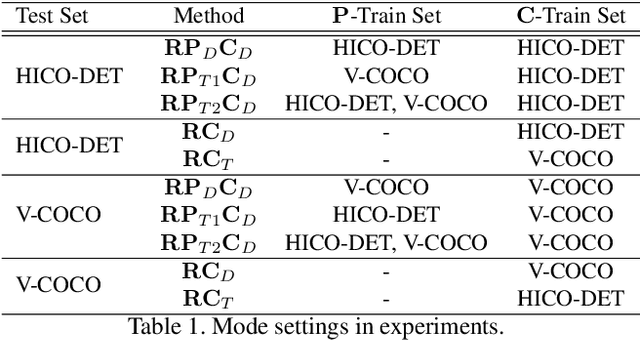
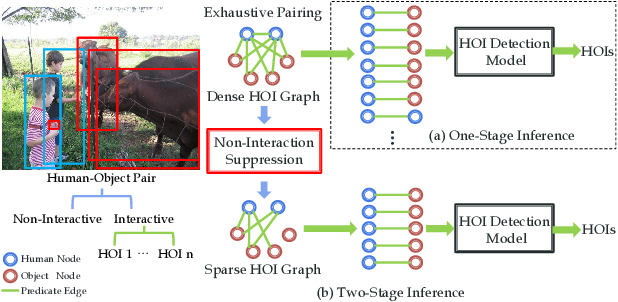
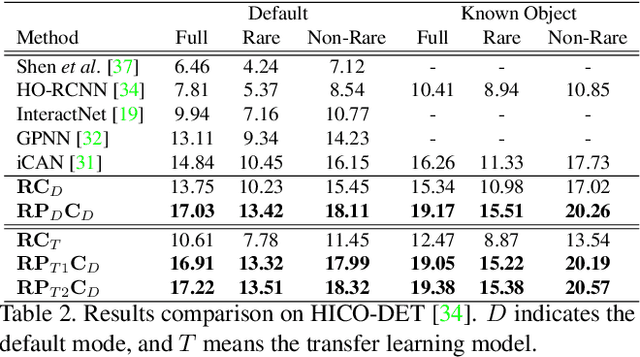
Human-Object Interaction (HOI) detection is an important problem to understand how humans interact with objects. In this paper, we explore interactiveness knowledge which indicates whether a human and an object interact with each other or not. We found that interactiveness knowledge can be learned across HOI datasets and bridge the gap between diverse HOI category settings. Our core idea is to exploit an interactiveness network to learn the general interactiveness knowledge from multiple HOI datasets and perform Non-Interaction Suppression (NIS) before HOI classification in inference. On account of the generalization ability of interactiveness, interactiveness network is a transferable knowledge learner and can be cooperated with any HOI detection models to achieve desirable results. We utilize the human instance and body part features together to learn the interactiveness in hierarchical paradigm, i.e., instance-level and body part-level interactivenesses. Thereafter, a consistency task is proposed to guide the learning and extract deeper interactive visual clues. We extensively evaluate the proposed method on HICO-DET, V-COCO, and a newly constructed PaStaNet-HOI dataset. With the learned interactiveness, our method outperforms state-of-the-art HOI detection methods, verifying its efficacy and flexibility. Code is available at https://github.com/DirtyHarryLYL/Transferable-Interactiveness-Network.
HOI Analysis: Integrating and Decomposing Human-Object Interaction
Nov 07, 2020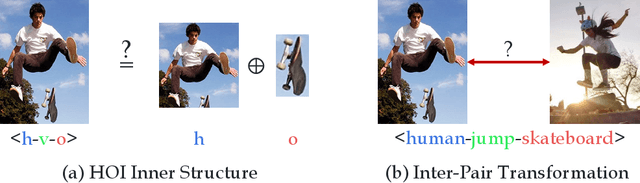



Human-Object Interaction (HOI) consists of human, object and implicit interaction/verb. Different from previous methods that directly map pixels to HOI semantics, we propose a novel perspective for HOI learning in an analytical manner. In analogy to Harmonic Analysis, whose goal is to study how to represent the signals with the superposition of basic waves, we propose the HOI Analysis. We argue that coherent HOI can be decomposed into isolated human and object. Meanwhile, isolated human and object can also be integrated into coherent HOI again. Moreover, transformations between human-object pairs with the same HOI can also be easier approached with integration and decomposition. As a result, the implicit verb will be represented in the transformation function space. In light of this, we propose an Integration-Decomposition Network (IDN) to implement the above transformations and achieve state-of-the-art performance on widely-used HOI detection benchmarks. Code is available at https://github.com/DirtyHarryLYL/HAKE-Action-Torch/tree/IDN-(Integrating-Decomposing-Network).