 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExecutable Analytic Concepts as the Missing Link Between VLM Insight and Precise Manipulation
Oct 09, 2025Enabling robots to perform precise and generalized manipulation in unstructured environments remains a fundamental challenge in embodied AI. While Vision-Language Models (VLMs) have demonstrated remarkable capabilities in semantic reasoning and task planning, a significant gap persists between their high-level understanding and the precise physical execution required for real-world manipulation. To bridge this "semantic-to-physical" gap, we introduce GRACE, a novel framework that grounds VLM-based reasoning through executable analytic concepts (EAC)-mathematically defined blueprints that encode object affordances, geometric constraints, and semantics of manipulation. Our approach integrates a structured policy scaffolding pipeline that turn natural language instructions and visual information into an instantiated EAC, from which we derive grasp poses, force directions and plan physically feasible motion trajectory for robot execution. GRACE thus provides a unified and interpretable interface between high-level instruction understanding and low-level robot control, effectively enabling precise and generalizable manipulation through semantic-physical grounding. Extensive experiments demonstrate that GRACE achieves strong zero-shot generalization across a variety of articulated objects in both simulated and real-world environments, without requiring task-specific training.
Digital Gene: Learning about the Physical World through Analytic Concepts
Apr 09, 2025Reviewing the progress in artificial intelligence over the past decade, various significant advances (e.g. object detection, image generation, large language models) have enabled AI systems to produce more semantically meaningful outputs and achieve widespread adoption in internet scenarios. Nevertheless, AI systems still struggle when it comes to understanding and interacting with the physical world. This reveals an important issue: relying solely on semantic-level concepts learned from internet data (e.g. texts, images) to understand the physical world is far from sufficient -- machine intelligence currently lacks an effective way to learn about the physical world. This research introduces the idea of analytic concept -- representing the concepts related to the physical world through programs of mathematical procedures, providing machine intelligence a portal to perceive, reason about, and interact with the physical world. Except for detailing the design philosophy and providing guidelines for the application of analytic concepts, this research also introduce about the infrastructure that has been built around analytic concepts. I aim for my research to contribute to addressing these questions: What is a proper abstraction of general concepts in the physical world for machine intelligence? How to systematically integrate structured priors with neural networks to constrain AI systems to comply with physical laws?
Physically Ground Commonsense Knowledge for Articulated Object Manipulation with Analytic Concepts
Mar 30, 2025We human rely on a wide range of commonsense knowledge to interact with an extensive number and categories of objects in the physical world. Likewise, such commonsense knowledge is also crucial for robots to successfully develop generalized object manipulation skills. While recent advancements in Large Language Models (LLM) have showcased their impressive capabilities in acquiring commonsense knowledge and conducting commonsense reasoning, effectively grounding this semantic-level knowledge produced by LLMs to the physical world to thoroughly guide robots in generalized articulated object manipulation remains a challenge that has not been sufficiently addressed. To this end, we introduce analytic concepts, procedurally defined upon mathematical symbolism that can be directly computed and simulated by machines. By leveraging the analytic concepts as a bridge between the semantic-level knowledge inferred by LLMs and the physical world where real robots operate, we are able to figure out the knowledge of object structure and functionality with physics-informed representations, and then use the physically grounded knowledge to instruct robot control policies for generalized, interpretable and accurate articulated object manipulation. Extensive experiments in both simulation and real-world environments demonstrate the superiority of our approach.
Arti-PG: A Toolbox for Procedurally Synthesizing Large-Scale and Diverse Articulated Objects with Rich Annotations
Dec 19, 2024



The acquisition of substantial volumes of 3D articulated object data is expensive and time-consuming, and consequently the scarcity of 3D articulated object data becomes an obstacle for deep learning methods to achieve remarkable performance in various articulated object understanding tasks. Meanwhile, pairing these object data with detailed annotations to enable training for various tasks is also difficult and labor-intensive to achieve. In order to expeditiously gather a significant number of 3D articulated objects with comprehensive and detailed annotations for training, we propose Articulated Object Procedural Generation toolbox, a.k.a. Arti-PG toolbox. Arti-PG toolbox consists of i) descriptions of articulated objects by means of a generalized structure program along with their analytic correspondence to the objects' point cloud, ii) procedural rules about manipulations on the structure program to synthesize large-scale and diverse new articulated objects, and iii) mathematical descriptions of knowledge (e.g. affordance, semantics, etc.) to provide annotations to the synthesized object. Arti-PG has two appealing properties for providing training data for articulated object understanding tasks: i) objects are created with unlimited variations in shape through program-oriented structure manipulation, ii) Arti-PG is widely applicable to diverse tasks by easily providing comprehensive and detailed annotations. Arti-PG now supports the procedural generation of 26 categories of articulate objects and provides annotations across a wide range of both vision and manipulation tasks, and we provide exhaustive experiments which fully demonstrate its advantages. We will make Arti-PG toolbox publicly available for the community to use.
ConceptFactory: Facilitate 3D Object Knowledge Annotation with Object Conceptualization
Nov 01, 2024We present ConceptFactory, a novel scope to facilitate more efficient annotation of 3D object knowledge by recognizing 3D objects through generalized concepts (i.e. object conceptualization), aiming at promoting machine intelligence to learn comprehensive object knowledge from both vision and robotics aspects. This idea originates from the findings in human cognition research that the perceptual recognition of objects can be explained as a process of arranging generalized geometric components (e.g. cuboids and cylinders). ConceptFactory consists of two critical parts: i) ConceptFactory Suite, a unified toolbox that adopts Standard Concept Template Library (STL-C) to drive a web-based platform for object conceptualization, and ii) ConceptFactory Asset, a large collection of conceptualized objects acquired using ConceptFactory suite. Our approach enables researchers to effortlessly acquire or customize extensive varieties of object knowledge to comprehensively study different object understanding tasks. We validate our idea on a wide range of benchmark tasks from both vision and robotics aspects with state-of-the-art algorithms, demonstrating the high quality and versatility of annotations provided by our approach. Our website is available at https://apeirony.github.io/ConceptFactory.
Discovering Conceptual Knowledge with Analytic Ontology Templates for Articulated Objects
Sep 18, 2024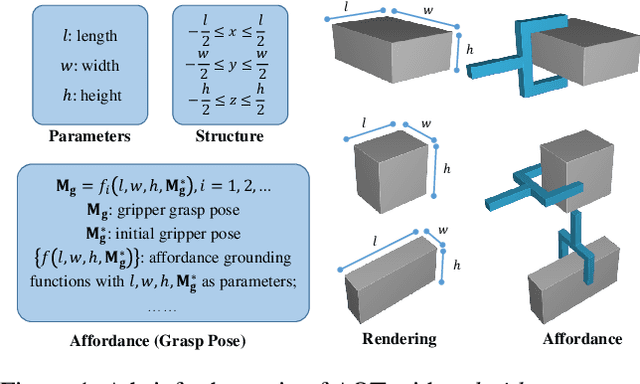
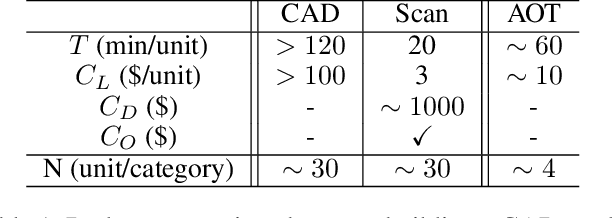


Human cognition can leverage fundamental conceptual knowledge, like geometric and kinematic ones, to appropriately perceive, comprehend and interact with novel objects. Motivated by this finding, we aim to endow machine intelligence with an analogous capability through performing at the conceptual level, in order to understand and then interact with articulated objects, especially for those in novel categories, which is challenging due to the intricate geometric structures and diverse joint types of articulated objects. To achieve this goal, we propose Analytic Ontology Template (AOT), a parameterized and differentiable program description of generalized conceptual ontologies. A baseline approach called AOTNet driven by AOTs is designed accordingly to equip intelligent agents with these generalized concepts, and then empower the agents to effectively discover the conceptual knowledge on the structure and affordance of articulated objects. The AOT-driven approach yields benefits in three key perspectives: i) enabling concept-level understanding of articulated objects without relying on any real training data, ii) providing analytic structure information, and iii) introducing rich affordance information indicating proper ways of interaction. We conduct exhaustive experiments and the results demonstrate the superiority of our approach in understanding and then interacting with articulated objects.
Symbol-LLM: Leverage Language Models for Symbolic System in Visual Human Activity Reasoning
Nov 29, 2023



Human reasoning can be understood as a cooperation between the intuitive, associative "System-1" and the deliberative, logical "System-2". For existing System-1-like methods in visual activity understanding, it is crucial to integrate System-2 processing to improve explainability, generalization, and data efficiency. One possible path of activity reasoning is building a symbolic system composed of symbols and rules, where one rule connects multiple symbols, implying human knowledge and reasoning abilities. Previous methods have made progress, but are defective with limited symbols from handcraft and limited rules from visual-based annotations, failing to cover the complex patterns of activities and lacking compositional generalization. To overcome the defects, we propose a new symbolic system with two ideal important properties: broad-coverage symbols and rational rules. Collecting massive human knowledge via manual annotations is expensive to instantiate this symbolic system. Instead, we leverage the recent advancement of LLMs (Large Language Models) as an approximation of the two ideal properties, i.e., Symbols from Large Language Models (Symbol-LLM). Then, given an image, visual contents from the images are extracted and checked as symbols and activity semantics are reasoned out based on rules via fuzzy logic calculation. Our method shows superiority in extensive activity understanding tasks. Code and data are available at https://mvig-rhos.com/symbol_llm.
Three Steps to Multimodal Trajectory Prediction: Modality Clustering, Classification and Synthesis
Mar 22, 2021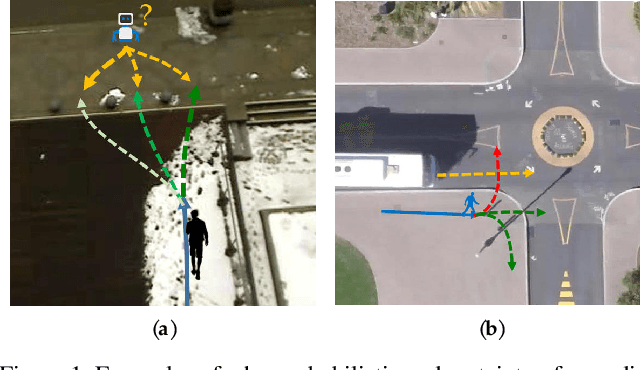
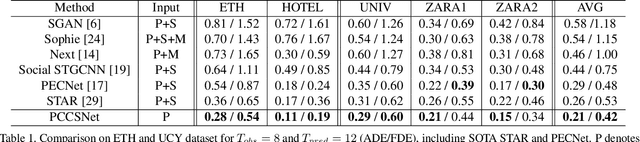
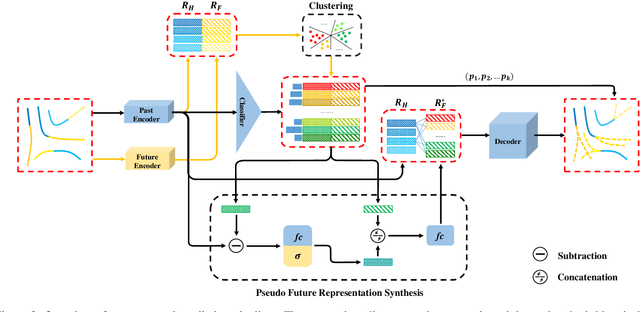
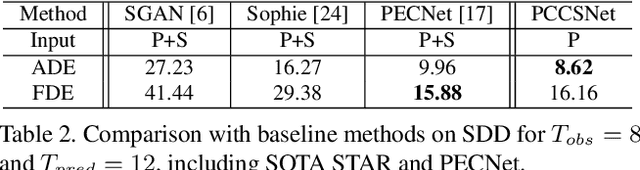
Multimodal prediction results are essential for trajectory prediction task as there is no single correct answer for the future. Previous frameworks can be divided into three categories: regression, generation and classification frameworks. However, these frameworks have weaknesses in different aspects so that they cannot model the multimodal prediction task comprehensively. In this paper, we present a novel insight along with a brand-new prediction framework by formulating multimodal prediction into three steps: modality clustering, classification and synthesis, and address the shortcomings of earlier frameworks. Exhaustive experiments on popular benchmarks have demonstrated that our proposed method surpasses state-of-the-art works even without introducing social and map information. Specifically, we achieve 19.2% and 20.8% improvement on ADE and FDE respectively on ETH/UCY dataset. Our code will be made publicly availabe.
Recursive Social Behavior Graph for Trajectory Prediction
Apr 22, 2020
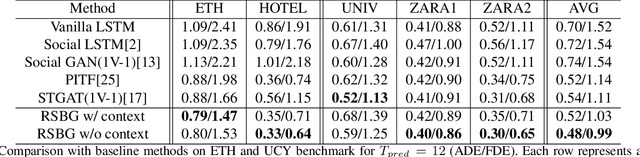


Social interaction is an important topic in human trajectory prediction to generate plausible paths. In this paper, we present a novel insight of group-based social interaction model to explore relationships among pedestrians. We recursively extract social representations supervised by group-based annotations and formulate them into a social behavior graph, called Recursive Social Behavior Graph. Our recursive mechanism explores the representation power largely. Graph Convolutional Neural Network then is used to propagate social interaction information in such a graph. With the guidance of Recursive Social Behavior Graph, we surpass state-of-the-art method on ETH and UCY dataset for 11.1% in ADE and 10.8% in FDE in average, and successfully predict complex social behaviors.
InstaBoost: Boosting Instance Segmentation via Probability Map Guided Copy-Pasting
Aug 21, 2019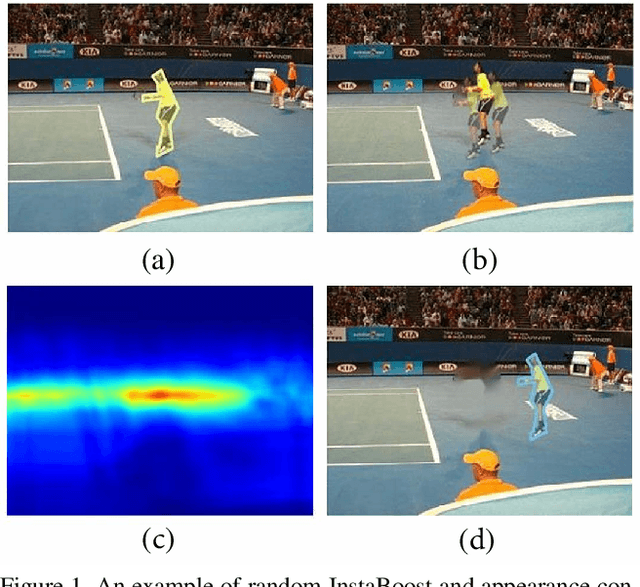
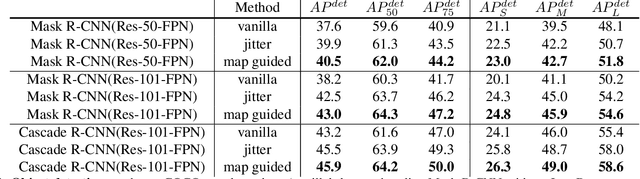

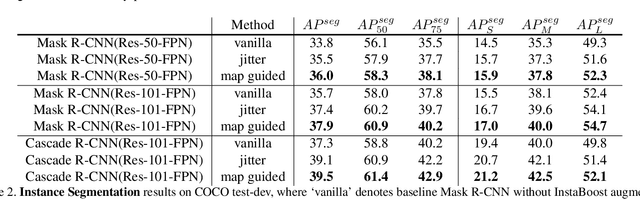
Instance segmentation requires a large number of training samples to achieve satisfactory performance and benefits from proper data augmentation. To enlarge the training set and increase the diversity, previous methods have investigated using data annotation from other domain (e.g. bbox, point) in a weakly supervised mechanism. In this paper, we present a simple, efficient and effective method to augment the training set using the existing instance mask annotations. Exploiting the pixel redundancy of the background, we are able to improve the performance of Mask R-CNN for 1.7 mAP on COCO dataset and 3.3 mAP on Pascal VOC dataset by simply introducing random jittering to objects. Furthermore, we propose a location probability map based approach to explore the feasible locations that objects can be placed based on local appearance similarity. With the guidance of such map, we boost the performance of R101-Mask R-CNN on instance segmentation from 35.7 mAP to 37.9 mAP without modifying the backbone or network structure. Our method is simple to implement and does not increase the computational complexity. It can be integrated into the training pipeline of any instance segmentation model without affecting the training and inference efficiency. Our code and models have been released at https://github.com/GothicAi/InstaBoost