 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRainbow Artifacts from Electromagnetic Signal Injection Attacks on Image Sensors
Jul 10, 2025
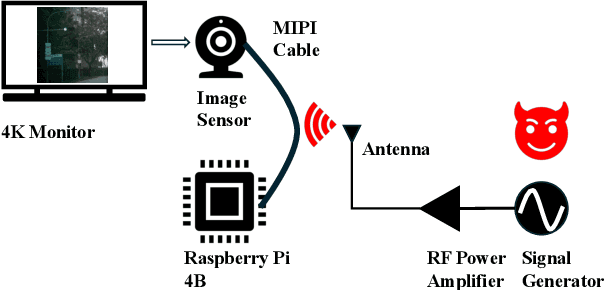


Image sensors are integral to a wide range of safety- and security-critical systems, including surveillance infrastructure, autonomous vehicles, and industrial automation. These systems rely on the integrity of visual data to make decisions. In this work, we investigate a novel class of electromagnetic signal injection attacks that target the analog domain of image sensors, allowing adversaries to manipulate raw visual inputs without triggering conventional digital integrity checks. We uncover a previously undocumented attack phenomenon on CMOS image sensors: rainbow-like color artifacts induced in images captured by image sensors through carefully tuned electromagnetic interference. We further evaluate the impact of these attacks on state-of-the-art object detection models, showing that the injected artifacts propagate through the image signal processing pipeline and lead to significant mispredictions. Our findings highlight a critical and underexplored vulnerability in the visual perception stack, highlighting the need for more robust defenses against physical-layer attacks in such systems.
PhantomLiDAR: Cross-modality Signal Injection Attacks against LiDAR
Sep 26, 2024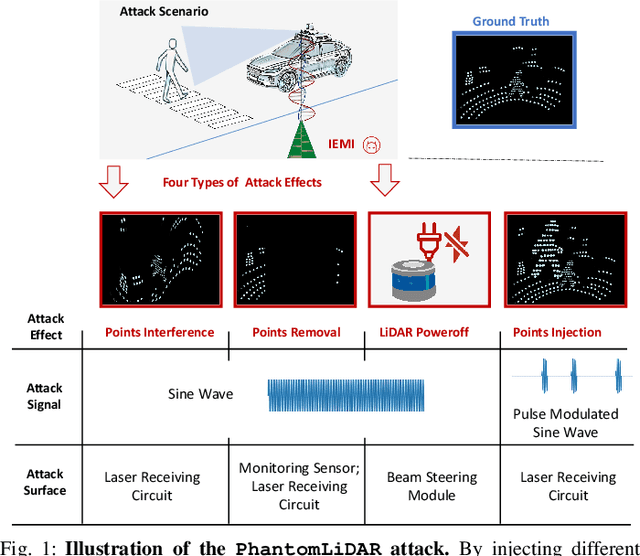
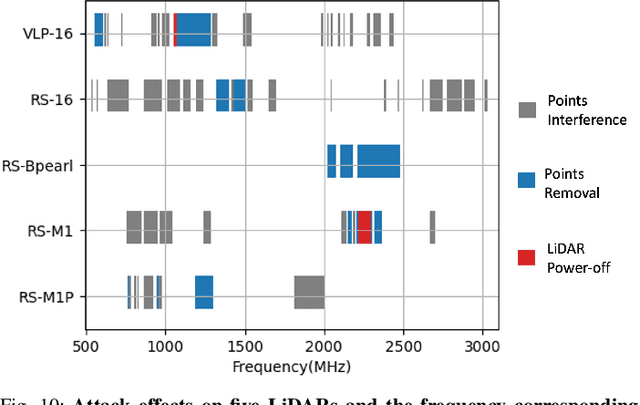
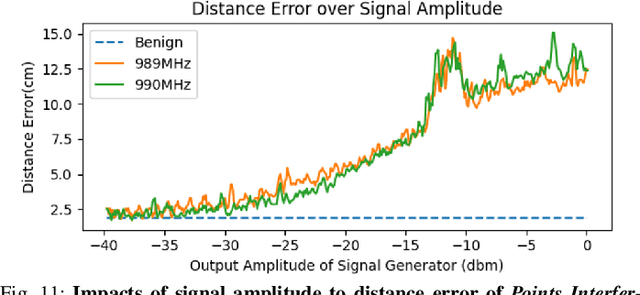
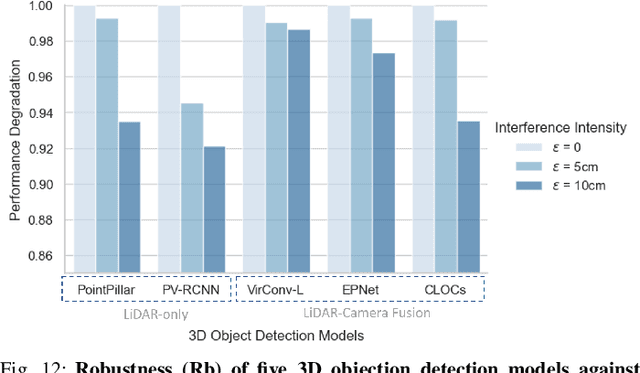
LiDAR (Light Detection and Ranging) is a pivotal sensor for autonomous driving, offering precise 3D spatial information. Previous signal attacks against LiDAR systems mainly exploit laser signals. In this paper, we investigate the possibility of cross-modality signal injection attacks, i.e., injecting intentional electromagnetic interference (IEMI) to manipulate LiDAR output. Our insight is that the internal modules of a LiDAR, i.e., the laser receiving circuit, the monitoring sensors, and the beam-steering modules, even with strict electromagnetic compatibility (EMC) testing, can still couple with the IEMI attack signals and result in the malfunction of LiDAR systems. Based on the above attack surfaces, we propose the PhantomLiDAR attack, which manipulates LiDAR output in terms of Points Interference, Points Injection, Points Removal, and even LiDAR Power-Off. We evaluate and demonstrate the effectiveness of PhantomLiDAR with both simulated and real-world experiments on five COTS LiDAR systems. We also conduct feasibility experiments in real-world moving scenarios. We provide potential defense measures that can be implemented at both the sensor level and the vehicle system level to mitigate the risks associated with IEMI attacks. Video demonstrations can be viewed at https://sites.google.com/view/phantomlidar.
Understanding Impacts of Electromagnetic Signal Injection Attacks on Object Detection
Jul 23, 2024



Object detection can localize and identify objects in images, and it is extensively employed in critical multimedia applications such as security surveillance and autonomous driving. Despite the success of existing object detection models, they are often evaluated in ideal scenarios where captured images guarantee the accurate and complete representation of the detecting scenes. However, images captured by image sensors may be affected by different factors in real applications, including cyber-physical attacks. In particular, attackers can exploit hardware properties within the systems to inject electromagnetic interference so as to manipulate the images. Such attacks can cause noisy or incomplete information about the captured scene, leading to incorrect detection results, potentially granting attackers malicious control over critical functions of the systems. This paper presents a research work that comprehensively quantifies and analyzes the impacts of such attacks on state-of-the-art object detection models in practice. It also sheds light on the underlying reasons for the incorrect detection outcomes.
BEVDistill: Cross-Modal BEV Distillation for Multi-View 3D Object Detection
Nov 17, 2022
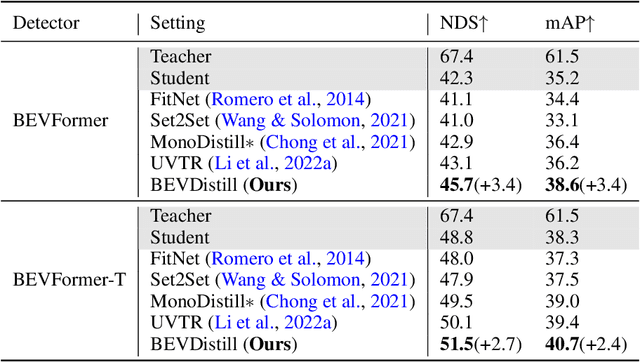


3D object detection from multiple image views is a fundamental and challenging task for visual scene understanding. Owing to its low cost and high efficiency, multi-view 3D object detection has demonstrated promising application prospects. However, accurately detecting objects through perspective views is extremely difficult due to the lack of depth information. Current approaches tend to adopt heavy backbones for image encoders, making them inapplicable for real-world deployment. Different from the images, LiDAR points are superior in providing spatial cues, resulting in highly precise localization. In this paper, we explore the incorporation of LiDAR-based detectors for multi-view 3D object detection. Instead of directly training a depth prediction network, we unify the image and LiDAR features in the Bird-Eye-View (BEV) space and adaptively transfer knowledge across non-homogenous representations in a teacher-student paradigm. To this end, we propose \textbf{BEVDistill}, a cross-modal BEV knowledge distillation (KD) framework for multi-view 3D object detection. Extensive experiments demonstrate that the proposed method outperforms current KD approaches on a highly-competitive baseline, BEVFormer, without introducing any extra cost in the inference phase. Notably, our best model achieves 59.4 NDS on the nuScenes test leaderboard, achieving new state-of-the-art in comparison with various image-based detectors. Code will be available at https://github.com/zehuichen123/BEVDistill.
AutoAlignV2: Deformable Feature Aggregation for Dynamic Multi-Modal 3D Object Detection
Jul 21, 2022



Point clouds and RGB images are two general perceptional sources in autonomous driving. The former can provide accurate localization of objects, and the latter is denser and richer in semantic information. Recently, AutoAlign presents a learnable paradigm in combining these two modalities for 3D object detection. However, it suffers from high computational cost introduced by the global-wise attention. To solve the problem, we propose Cross-Domain DeformCAFA module in this work. It attends to sparse learnable sampling points for cross-modal relational modeling, which enhances the tolerance to calibration error and greatly speeds up the feature aggregation across different modalities. To overcome the complex GT-AUG under multi-modal settings, we design a simple yet effective cross-modal augmentation strategy on convex combination of image patches given their depth information. Moreover, by carrying out a novel image-level dropout training scheme, our model is able to infer in a dynamic manner. To this end, we propose AutoAlignV2, a faster and stronger multi-modal 3D detection framework, built on top of AutoAlign. Extensive experiments on nuScenes benchmark demonstrate the effectiveness and efficiency of AutoAlignV2. Notably, our best model reaches 72.4 NDS on nuScenes test leaderboard, achieving new state-of-the-art results among all published multi-modal 3D object detectors. Code will be available at https://github.com/zehuichen123/AutoAlignV2.
Towards Model Generalization for Monocular 3D Object Detection
May 28, 2022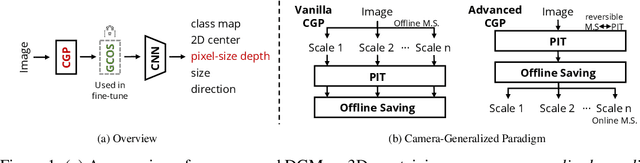

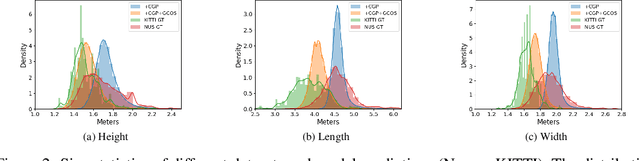

Monocular 3D object detection (Mono3D) has achieved tremendous improvements with emerging large-scale autonomous driving datasets and the rapid development of deep learning techniques. However, caused by severe domain gaps (e.g., the field of view (FOV), pixel size, and object size among datasets), Mono3D detectors have difficulty in generalization, leading to drastic performance degradation on unseen domains. To solve these issues, we combine the position-invariant transform and multi-scale training with the pixel-size depth strategy to construct an effective unified camera-generalized paradigm (CGP). It fully considers discrepancies in the FOV and pixel size of images captured by different cameras. Moreover, we further investigate the obstacle in quantitative metrics when cross-dataset inference through an exhaustive systematic study. We discern that the size bias of prediction leads to a colossal failure. Hence, we propose the 2D-3D geometry-consistent object scaling strategy (GCOS) to bridge the gap via an instance-level augment. Our method called DGMono3D achieves remarkable performance on all evaluated datasets and surpasses the SoTA unsupervised domain adaptation scheme even without utilizing data on the target domain.
Unsupervised Domain Adaptation for Monocular 3D Object Detection via Self-Training
Apr 27, 2022



Monocular 3D object detection (Mono3D) has achieved unprecedented success with the advent of deep learning techniques and emerging large-scale autonomous driving datasets. However, drastic performance degradation remains an unwell-studied challenge for practical cross-domain deployment as the lack of labels on the target domain. In this paper, we first comprehensively investigate the significant underlying factor of the domain gap in Mono3D, where the critical observation is a depth-shift issue caused by the geometric misalignment of domains. Then, we propose STMono3D, a new self-teaching framework for unsupervised domain adaptation on Mono3D. To mitigate the depth-shift, we introduce the geometry-aligned multi-scale training strategy to disentangle the camera parameters and guarantee the geometry consistency of domains. Based on this, we develop a teacher-student paradigm to generate adaptive pseudo labels on the target domain. Benefiting from the end-to-end framework that provides richer information of the pseudo labels, we propose the quality-aware supervision strategy to take instance-level pseudo confidences into account and improve the effectiveness of the target-domain training process. Moreover, the positive focusing training strategy and dynamic threshold are proposed to handle tremendous FN and FP pseudo samples. STMono3D achieves remarkable performance on all evaluated datasets and even surpasses fully supervised results on the KITTI 3D object detection dataset. To the best of our knowledge, this is the first study to explore effective UDA methods for Mono3D.
Graph-DETR3D: Rethinking Overlapping Regions for Multi-View 3D Object Detection
Apr 26, 2022
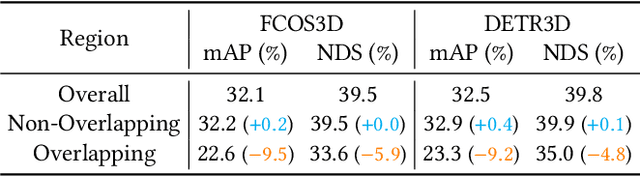


3D object detection from multiple image views is a fundamental and challenging task for visual scene understanding. Due to its low cost and high efficiency, multi-view 3D object detection has demonstrated promising application prospects. However, accurately detecting objects through perspective views in the 3D space is extremely difficult due to the lack of depth information. Recently, DETR3D introduces a novel 3D-2D query paradigm in aggregating multi-view images for 3D object detection and achieves state-of-the-art performance. In this paper, with intensive pilot experiments, we quantify the objects located at different regions and find that the "truncated instances" (i.e., at the border regions of each image) are the main bottleneck hindering the performance of DETR3D. Although it merges multiple features from two adjacent views in the overlapping regions, DETR3D still suffers from insufficient feature aggregation, thus missing the chance to fully boost the detection performance. In an effort to tackle the problem, we propose Graph-DETR3D to automatically aggregate multi-view imagery information through graph structure learning (GSL). It constructs a dynamic 3D graph between each object query and 2D feature maps to enhance the object representations, especially at the border regions. Besides, Graph-DETR3D benefits from a novel depth-invariant multi-scale training strategy, which maintains the visual depth consistency by simultaneously scaling the image size and the object depth. Extensive experiments on the nuScenes dataset demonstrate the effectiveness and efficiency of our Graph-DETR3D. Notably, our best model achieves 49.5 NDS on the nuScenes test leaderboard, achieving new state-of-the-art in comparison with various published image-view 3D object detectors.
SimIPU: Simple 2D Image and 3D Point Cloud Unsupervised Pre-Training for Spatial-Aware Visual Representations
Dec 09, 2021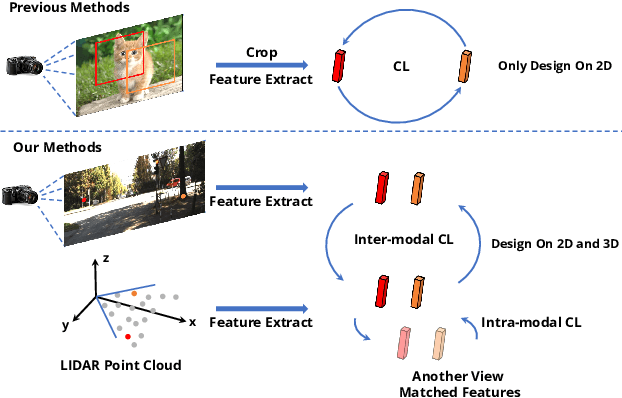



Pre-training has become a standard paradigm in many computer vision tasks. However, most of the methods are generally designed on the RGB image domain. Due to the discrepancy between the two-dimensional image plane and the three-dimensional space, such pre-trained models fail to perceive spatial information and serve as sub-optimal solutions for 3D-related tasks. To bridge this gap, we aim to learn a spatial-aware visual representation that can describe the three-dimensional space and is more suitable and effective for these tasks. To leverage point clouds, which are much more superior in providing spatial information compared to images, we propose a simple yet effective 2D Image and 3D Point cloud Unsupervised pre-training strategy, called SimIPU. Specifically, we develop a multi-modal contrastive learning framework that consists of an intra-modal spatial perception module to learn a spatial-aware representation from point clouds and an inter-modal feature interaction module to transfer the capability of perceiving spatial information from the point cloud encoder to the image encoder, respectively. Positive pairs for contrastive losses are established by the matching algorithm and the projection matrix. The whole framework is trained in an unsupervised end-to-end fashion. To the best of our knowledge, this is the first study to explore contrastive learning pre-training strategies for outdoor multi-modal datasets, containing paired camera images and LIDAR point clouds. Codes and models are available at https://github.com/zhyever/SimIPU.
Monocular 3D Object Detection: An Extrinsic Parameter Free Approach
Jun 30, 2021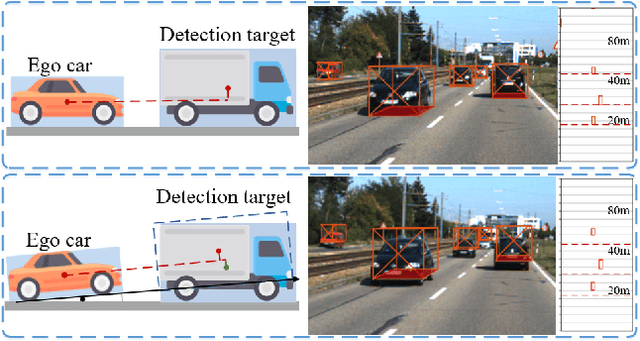


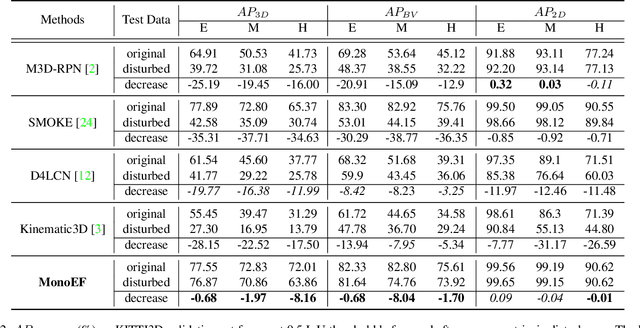
Monocular 3D object detection is an important task in autonomous driving. It can be easily intractable where there exists ego-car pose change w.r.t. ground plane. This is common due to the slight fluctuation of road smoothness and slope. Due to the lack of insight in industrial application, existing methods on open datasets neglect the camera pose information, which inevitably results in the detector being susceptible to camera extrinsic parameters. The perturbation of objects is very popular in most autonomous driving cases for industrial products. To this end, we propose a novel method to capture camera pose to formulate the detector free from extrinsic perturbation. Specifically, the proposed framework predicts camera extrinsic parameters by detecting vanishing point and horizon change. A converter is designed to rectify perturbative features in the latent space. By doing so, our 3D detector works independent of the extrinsic parameter variations and produces accurate results in realistic cases, e.g., potholed and uneven roads, where almost all existing monocular detectors fail to handle. Experiments demonstrate our method yields the best performance compared with the other state-of-the-arts by a large margin on both KITTI 3D and nuScenes datasets.