 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Nonlinear Hash-based Optimization Method for SpMV on GPUs
Apr 11, 2025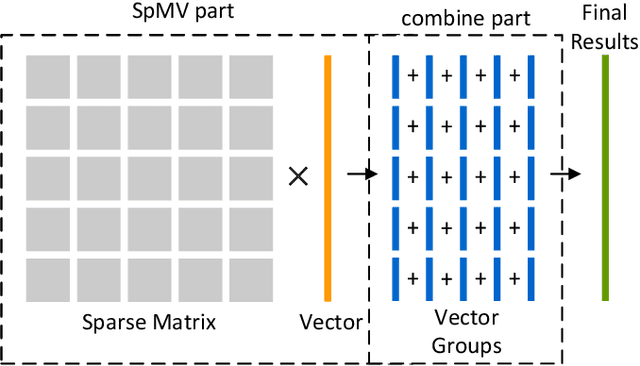
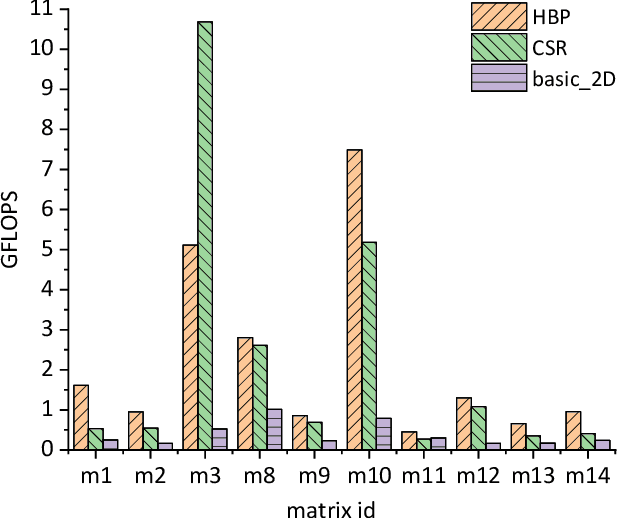
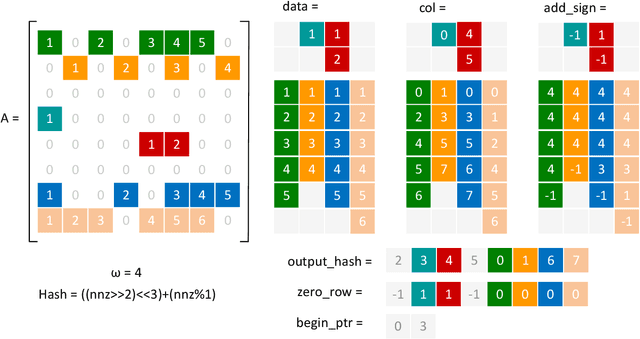

Sparse matrix-vector multiplication (SpMV) is a fundamental operation with a wide range of applications in scientific computing and artificial intelligence. However, the large scale and sparsity of sparse matrix often make it a performance bottleneck. In this paper, we highlight the effectiveness of hash-based techniques in optimizing sparse matrix reordering, introducing the Hash-based Partition (HBP) format, a lightweight SpMV approach. HBP retains the performance benefits of the 2D-partitioning method while leveraging the hash transformation's ability to group similar elements, thereby accelerating the pre-processing phase of sparse matrix reordering. Additionally, we achieve parallel load balancing across matrix blocks through a competitive method. Our experiments, conducted on both Nvidia Jetson AGX Orin and Nvidia RTX 4090, show that in the pre-processing step, our method offers an average speedup of 3.53 times compared to the sorting approach and 3.67 times compared to the dynamic programming method employed in Regu2D. Furthermore, in SpMV, our method achieves a maximum speedup of 3.32 times on Orin and 3.01 times on RTX4090 against the CSR format in sparse matrices from the University of Florida Sparse Matrix Collection.
Achieving O(1/N) Optimality Gap in Restless Bandits through Diffusion Approximation
Oct 19, 2024
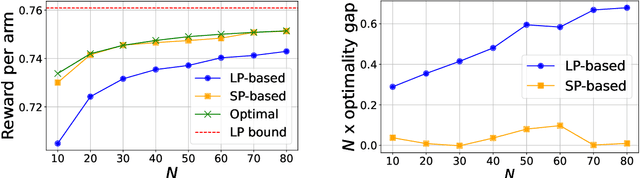
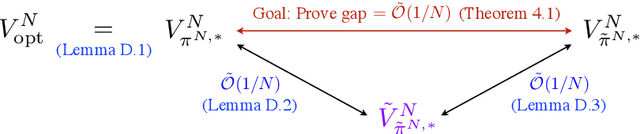
We study the finite horizon Restless Multi-Armed Bandit (RMAB) problem with $N$ homogeneous arms, focusing on the challenges posed by degenerate RMABs, which are prevalent in practical applications. While previous work has shown that Linear Programming (LP)-based policies achieve exponentially fast convergence relative to the LP upper bound in non-degenerate models, applying these LP-based policies to degenerate RMABs results in slower convergence rates of $O(1/\sqrt{N})$. We construct a diffusion system that incorporates both the mean and variance of the stochastic processes, in contrast to the fluid system from the LP, which only accounts for the mean, thereby providing a more accurate representation of RMAB dynamics. Consequently, our novel diffusion-resolving policy achieves an optimality gap of $O(1/N)$ relative to the true optimal value, rather than the LP upper bound, revealing that the fluid approximation and the LP upper bound are too loose in degenerate settings. These insights pave the way for constructing policies that surpass the $O(1/\sqrt{N})$ optimality gap for any RMAB, whether degenerate or not.
PhantomLiDAR: Cross-modality Signal Injection Attacks against LiDAR
Sep 26, 2024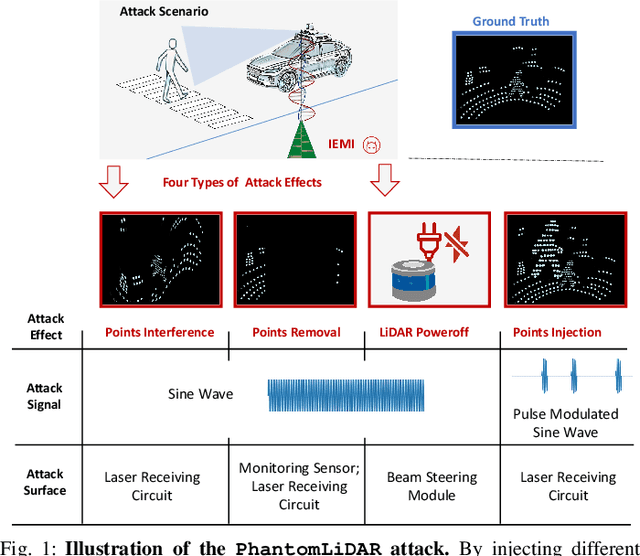
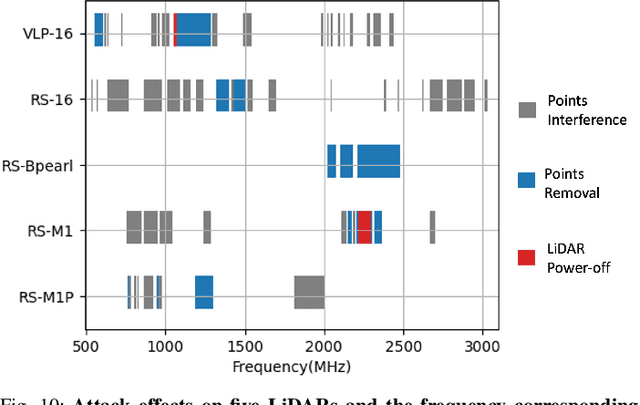
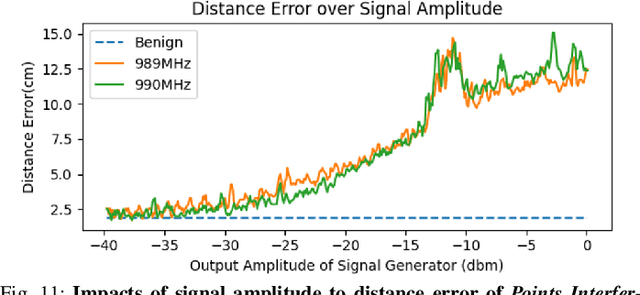
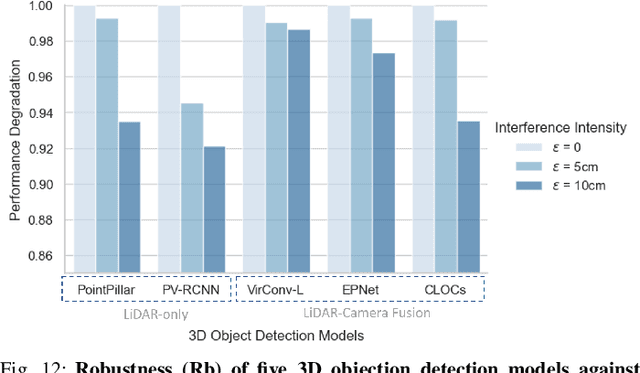
LiDAR (Light Detection and Ranging) is a pivotal sensor for autonomous driving, offering precise 3D spatial information. Previous signal attacks against LiDAR systems mainly exploit laser signals. In this paper, we investigate the possibility of cross-modality signal injection attacks, i.e., injecting intentional electromagnetic interference (IEMI) to manipulate LiDAR output. Our insight is that the internal modules of a LiDAR, i.e., the laser receiving circuit, the monitoring sensors, and the beam-steering modules, even with strict electromagnetic compatibility (EMC) testing, can still couple with the IEMI attack signals and result in the malfunction of LiDAR systems. Based on the above attack surfaces, we propose the PhantomLiDAR attack, which manipulates LiDAR output in terms of Points Interference, Points Injection, Points Removal, and even LiDAR Power-Off. We evaluate and demonstrate the effectiveness of PhantomLiDAR with both simulated and real-world experiments on five COTS LiDAR systems. We also conduct feasibility experiments in real-world moving scenarios. We provide potential defense measures that can be implemented at both the sensor level and the vehicle system level to mitigate the risks associated with IEMI attacks. Video demonstrations can be viewed at https://sites.google.com/view/phantomlidar.
SafeEar: Content Privacy-Preserving Audio Deepfake Detection
Sep 14, 2024



Text-to-Speech (TTS) and Voice Conversion (VC) models have exhibited remarkable performance in generating realistic and natural audio. However, their dark side, audio deepfake poses a significant threat to both society and individuals. Existing countermeasures largely focus on determining the genuineness of speech based on complete original audio recordings, which however often contain private content. This oversight may refrain deepfake detection from many applications, particularly in scenarios involving sensitive information like business secrets. In this paper, we propose SafeEar, a novel framework that aims to detect deepfake audios without relying on accessing the speech content within. Our key idea is to devise a neural audio codec into a novel decoupling model that well separates the semantic and acoustic information from audio samples, and only use the acoustic information (e.g., prosody and timbre) for deepfake detection. In this way, no semantic content will be exposed to the detector. To overcome the challenge of identifying diverse deepfake audio without semantic clues, we enhance our deepfake detector with real-world codec augmentation. Extensive experiments conducted on four benchmark datasets demonstrate SafeEar's effectiveness in detecting various deepfake techniques with an equal error rate (EER) down to 2.02%. Simultaneously, it shields five-language speech content from being deciphered by both machine and human auditory analysis, demonstrated by word error rates (WERs) all above 93.93% and our user study. Furthermore, our benchmark constructed for anti-deepfake and anti-content recovery evaluation helps provide a basis for future research in the realms of audio privacy preservation and deepfake detection.
Understanding Impacts of Electromagnetic Signal Injection Attacks on Object Detection
Jul 23, 2024



Object detection can localize and identify objects in images, and it is extensively employed in critical multimedia applications such as security surveillance and autonomous driving. Despite the success of existing object detection models, they are often evaluated in ideal scenarios where captured images guarantee the accurate and complete representation of the detecting scenes. However, images captured by image sensors may be affected by different factors in real applications, including cyber-physical attacks. In particular, attackers can exploit hardware properties within the systems to inject electromagnetic interference so as to manipulate the images. Such attacks can cause noisy or incomplete information about the captured scene, leading to incorrect detection results, potentially granting attackers malicious control over critical functions of the systems. This paper presents a research work that comprehensively quantifies and analyzes the impacts of such attacks on state-of-the-art object detection models in practice. It also sheds light on the underlying reasons for the incorrect detection outcomes.
SafeGen: Mitigating Unsafe Content Generation in Text-to-Image Models
Apr 10, 2024



Text-to-image (T2I) models, such as Stable Diffusion, have exhibited remarkable performance in generating high-quality images from text descriptions in recent years. However, text-to-image models may be tricked into generating not-safe-for-work (NSFW) content, particularly in sexual scenarios. Existing countermeasures mostly focus on filtering inappropriate inputs and outputs, or suppressing improper text embeddings, which can block explicit NSFW-related content (e.g., naked or sexy) but may still be vulnerable to adversarial prompts inputs that appear innocent but are ill-intended. In this paper, we present SafeGen, a framework to mitigate unsafe content generation by text-to-image models in a text-agnostic manner. The key idea is to eliminate unsafe visual representations from the model regardless of the text input. In this way, the text-to-image model is resistant to adversarial prompts since unsafe visual representations are obstructed from within. Extensive experiments conducted on four datasets demonstrate SafeGen's effectiveness in mitigating unsafe content generation while preserving the high-fidelity of benign images. SafeGen outperforms eight state-of-the-art baseline methods and achieves 99.1% sexual content removal performance. Furthermore, our constructed benchmark of adversarial prompts provides a basis for future development and evaluation of anti-NSFW-generation methods.
Inaudible Adversarial Perturbation: Manipulating the Recognition of User Speech in Real Time
Aug 03, 2023



Automatic speech recognition (ASR) systems have been shown to be vulnerable to adversarial examples (AEs). Recent success all assumes that users will not notice or disrupt the attack process despite the existence of music/noise-like sounds and spontaneous responses from voice assistants. Nonetheless, in practical user-present scenarios, user awareness may nullify existing attack attempts that launch unexpected sounds or ASR usage. In this paper, we seek to bridge the gap in existing research and extend the attack to user-present scenarios. We propose VRIFLE, an inaudible adversarial perturbation (IAP) attack via ultrasound delivery that can manipulate ASRs as a user speaks. The inherent differences between audible sounds and ultrasounds make IAP delivery face unprecedented challenges such as distortion, noise, and instability. In this regard, we design a novel ultrasonic transformation model to enhance the crafted perturbation to be physically effective and even survive long-distance delivery. We further enable VRIFLE's robustness by adopting a series of augmentation on user and real-world variations during the generation process. In this way, VRIFLE features an effective real-time manipulation of the ASR output from different distances and under any speech of users, with an alter-and-mute strategy that suppresses the impact of user disruption. Our extensive experiments in both digital and physical worlds verify VRIFLE's effectiveness under various configurations, robustness against six kinds of defenses, and universality in a targeted manner. We also show that VRIFLE can be delivered with a portable attack device and even everyday-life loudspeakers.
Enrollment-stage Backdoor Attacks on Speaker Recognition Systems via Adversarial Ultrasound
Jun 28, 2023

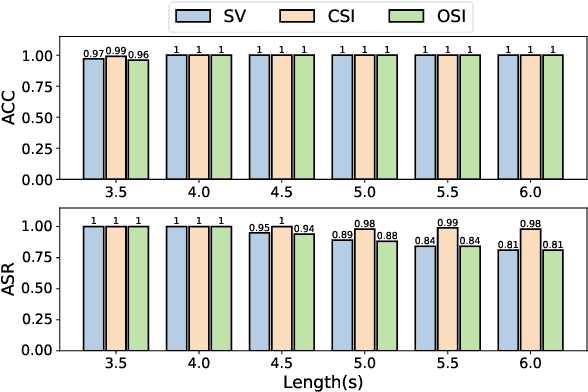

Automatic Speaker Recognition Systems (SRSs) have been widely used in voice applications for personal identification and access control. A typical SRS consists of three stages, i.e., training, enrollment, and recognition. Previous work has revealed that SRSs can be bypassed by backdoor attacks at the training stage or by adversarial example attacks at the recognition stage. In this paper, we propose TUNER, a new type of backdoor attack against the enrollment stage of SRS via adversarial ultrasound modulation, which is inaudible, synchronization-free, content-independent, and black-box. Our key idea is to first inject the backdoor into the SRS with modulated ultrasound when a legitimate user initiates the enrollment, and afterward, the polluted SRS will grant access to both the legitimate user and the adversary with high confidence. Our attack faces a major challenge of unpredictable user articulation at the enrollment stage. To overcome this challenge, we generate the ultrasonic backdoor by augmenting the optimization process with random speech content, vocalizing time, and volume of the user. Furthermore, to achieve real-world robustness, we improve the ultrasonic signal over traditional methods using sparse frequency points, pre-compensation, and single-sideband (SSB) modulation. We extensively evaluate TUNER on two common datasets and seven representative SRS models. Results show that our attack can successfully bypass speaker recognition systems while remaining robust to various speakers, speech content, et
Improving Multimodal Interactive Agents with Reinforcement Learning from Human Feedback
Nov 21, 2022An important goal in artificial intelligence is to create agents that can both interact naturally with humans and learn from their feedback. Here we demonstrate how to use reinforcement learning from human feedback (RLHF) to improve upon simulated, embodied agents trained to a base level of competency with imitation learning. First, we collected data of humans interacting with agents in a simulated 3D world. We then asked annotators to record moments where they believed that agents either progressed toward or regressed from their human-instructed goal. Using this annotation data we leveraged a novel method - which we call "Inter-temporal Bradley-Terry" (IBT) modelling - to build a reward model that captures human judgments. Agents trained to optimise rewards delivered from IBT reward models improved with respect to all of our metrics, including subsequent human judgment during live interactions with agents. Altogether our results demonstrate how one can successfully leverage human judgments to improve agent behaviour, allowing us to use reinforcement learning in complex, embodied domains without programmatic reward functions. Videos of agent behaviour may be found at https://youtu.be/v_Z9F2_eKk4.
Intra-agent speech permits zero-shot task acquisition
Jun 07, 2022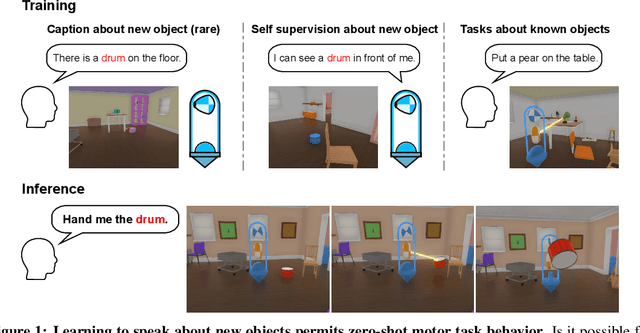
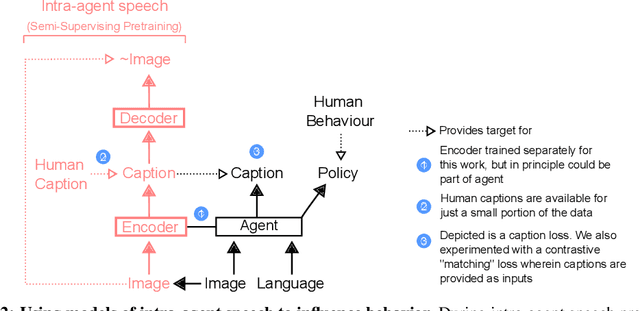

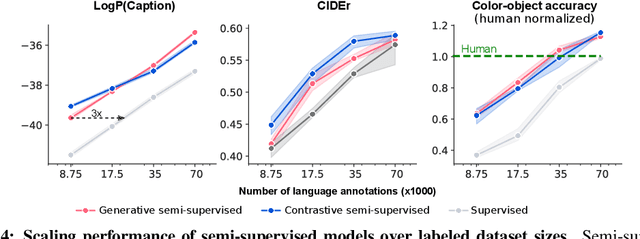
Human language learners are exposed to a trickle of informative, context-sensitive language, but a flood of raw sensory data. Through both social language use and internal processes of rehearsal and practice, language learners are able to build high-level, semantic representations that explain their perceptions. Here, we take inspiration from such processes of "inner speech" in humans (Vygotsky, 1934) to better understand the role of intra-agent speech in embodied behavior. First, we formally pose intra-agent speech as a semi-supervised problem and develop two algorithms that enable visually grounded captioning with little labeled language data. We then experimentally compute scaling curves over different amounts of labeled data and compare the data efficiency against a supervised learning baseline. Finally, we incorporate intra-agent speech into an embodied, mobile manipulator agent operating in a 3D virtual world, and show that with as few as 150 additional image captions, intra-agent speech endows the agent with the ability to manipulate and answer questions about a new object without any related task-directed experience (zero-shot). Taken together, our experiments suggest that modelling intra-agent speech is effective in enabling embodied agents to learn new tasks efficiently and without direct interaction experience.