 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentially Private and Communication Efficient Large Language Model Split Inference via Stochastic Quantization and Soft Prompt
Feb 12, 2026Large Language Models (LLMs) have achieved remarkable performance and received significant research interest. The enormous computational demands, however, hinder the local deployment on devices with limited resources. The current prevalent LLM inference paradigms require users to send queries to the service providers for processing, which raises critical privacy concerns. Existing approaches propose to allow the users to obfuscate the token embeddings before transmission and utilize local models for denoising. Nonetheless, transmitting the token embeddings and deploying local models may result in excessive communication and computation overhead, preventing practical implementation. In this work, we propose \textbf{DEL}, a framework for \textbf{D}ifferentially private and communication \textbf{E}fficient \textbf{L}LM split inference. More specifically, an embedding projection module and a differentially private stochastic quantization mechanism are proposed to reduce the communication overhead in a privacy-preserving manner. To eliminate the need for local models, we adapt soft prompt at the server side to compensate for the utility degradation caused by privacy. To the best of our knowledge, this is the first work that utilizes soft prompt to improve the trade-off between privacy and utility in LLM inference, and extensive experiments on text generation and natural language understanding benchmarks demonstrate the effectiveness of the proposed method.
Learning Human-Like Badminton Skills for Humanoid Robots
Feb 09, 2026Realizing versatile and human-like performance in high-demand sports like badminton remains a formidable challenge for humanoid robotics. Unlike standard locomotion or static manipulation, this task demands a seamless integration of explosive whole-body coordination and precise, timing-critical interception. While recent advances have achieved lifelike motion mimicry, bridging the gap between kinematic imitation and functional, physics-aware striking without compromising stylistic naturalness is non-trivial. To address this, we propose Imitation-to-Interaction, a progressive reinforcement learning framework designed to evolve a robot from a "mimic" to a capable "striker." Our approach establishes a robust motor prior from human data, distills it into a compact, model-based state representation, and stabilizes dynamics via adversarial priors. Crucially, to overcome the sparsity of expert demonstrations, we introduce a manifold expansion strategy that generalizes discrete strike points into a dense interaction volume. We validate our framework through the mastery of diverse skills, including lifts and drop shots, in simulation. Furthermore, we demonstrate the first zero-shot sim-to-real transfer of anthropomorphic badminton skills to a humanoid robot, successfully replicating the kinetic elegance and functional precision of human athletes in the physical world.
Instance camera focus prediction for crystal agglomeration classification
Jan 13, 2026Agglomeration refers to the process of crystal clustering due to interparticle forces. Crystal agglomeration analysis from microscopic images is challenging due to the inherent limitations of two-dimensional imaging. Overlapping crystals may appear connected even when located at different depth layers. Because optical microscopes have a shallow depth of field, crystals that are in-focus and out-of-focus in the same image typically reside on different depth layers and do not constitute true agglomeration. To address this, we first quantified camera focus with an instance camera focus prediction network to predict 2 class focus level that aligns better with visual observations than traditional image processing focus measures. Then an instance segmentation model is combined with the predicted focus level for agglomeration classification. Our proposed method has a higher agglomeration classification and segmentation accuracy than the baseline models on ammonium perchlorate crystal and sugar crystal dataset.
Phantom Menace: Exploring and Enhancing the Robustness of VLA Models against Physical Sensor Attacks
Nov 13, 2025Vision-Language-Action (VLA) models revolutionize robotic systems by enabling end-to-end perception-to-action pipelines that integrate multiple sensory modalities, such as visual signals processed by cameras and auditory signals captured by microphones. This multi-modality integration allows VLA models to interpret complex, real-world environments using diverse sensor data streams. Given the fact that VLA-based systems heavily rely on the sensory input, the security of VLA models against physical-world sensor attacks remains critically underexplored. To address this gap, we present the first systematic study of physical sensor attacks against VLAs, quantifying the influence of sensor attacks and investigating the defenses for VLA models. We introduce a novel ``Real-Sim-Real'' framework that automatically simulates physics-based sensor attack vectors, including six attacks targeting cameras and two targeting microphones, and validates them on real robotic systems. Through large-scale evaluations across various VLA architectures and tasks under varying attack parameters, we demonstrate significant vulnerabilities, with susceptibility patterns that reveal critical dependencies on task types and model designs. We further develop an adversarial-training-based defense that enhances VLA robustness against out-of-distribution physical perturbations caused by sensor attacks while preserving model performance. Our findings expose an urgent need for standardized robustness benchmarks and mitigation strategies to secure VLA deployments in safety-critical environments.
Empowering Manufacturers with Privacy-Preserving AI Tools: A Case Study in Privacy-Preserving Machine Learning to Solve Real-World Problems
Jul 02, 2025Small- and medium-sized manufacturers need innovative data tools but, because of competition and privacy concerns, often do not want to share their proprietary data with researchers who might be interested in helping. This paper introduces a privacy-preserving platform by which manufacturers may safely share their data with researchers through secure methods, so that those researchers then create innovative tools to solve the manufacturers' real-world problems, and then provide tools that execute solutions back onto the platform for others to use with privacy and confidentiality guarantees. We illustrate this problem through a particular use case which addresses an important problem in the large-scale manufacturing of food crystals, which is that quality control relies on image analysis tools. Previous to our research, food crystals in the images were manually counted, which required substantial and time-consuming human efforts, but we have developed and deployed a crystal analysis tool which makes this process both more rapid and accurate. The tool enables automatic characterization of the crystal size distribution and numbers from microscope images while the natural imperfections from the sample preparation are automatically removed; a machine learning model to count high resolution translucent crystals and agglomeration of crystals was also developed to aid in these efforts. The resulting algorithm was then packaged for real-world use on the factory floor via a web-based app secured through the originating privacy-preserving platform, allowing manufacturers to use it while keeping their proprietary data secure. After demonstrating this full process, future directions are also explored.
PowerRadio: Manipulate Sensor Measurementvia Power GND Radiation
Dec 24, 2024Sensors are key components enabling various applications, e.g., home intrusion detection and environmental monitoring. While various software defenses and physical protections are used to prevent sensor manipulation, this paper introduces a new threat vector, PowerRadio, that bypasses existing protections and changes sensor readings from a distance. PowerRadio leverages interconnected ground (GND) wires, a standard practice for electrical safety at home, to inject malicious signals. The injected signal is coupled by the sensor's analog measurement wire and eventually survives the noise filters, inducing incorrect measurement. We present three methods to manipulate sensors by inducing static bias, periodical signals, or pulses. For instance, we show adding stripes into the captured images of a surveillance camera or injecting inaudible voice commands into conference microphones. We study the underlying principles of PowerRadio and identify its root causes: (1) the lack of shielding between ground and data signal wires and (2) the asymmetry of circuit impedance that enables interference to bypass filtering. We validate PowerRadio against a surveillance system, broadcast systems, and various sensors. We believe that PowerRadio represents an emerging threat, exhibiting the advantages of both radiated and conducted EMI, e.g., expanding the effective attack distance of radiated EMI yet eliminating the requirement of line-of-sight or approaching physically. Our insights shall provide guidance for enhancing the sensors' security and power wiring during the design phases.
Efficient Microscopic Image Instance Segmentation for Food Crystal Quality Control
Sep 26, 2024This paper is directed towards the food crystal quality control area for manufacturing, focusing on efficiently predicting food crystal counts and size distributions. Previously, manufacturers used the manual counting method on microscopic images of food liquid products, which requires substantial human effort and suffers from inconsistency issues. Food crystal segmentation is a challenging problem due to the diverse shapes of crystals and their surrounding hard mimics. To address this challenge, we propose an efficient instance segmentation method based on object detection. Experimental results show that the predicted crystal counting accuracy of our method is comparable with existing segmentation methods, while being five times faster. Based on our experiments, we also define objective criteria for separating hard mimics and food crystals, which could benefit manual annotation tasks on similar dataset.
PhantomLiDAR: Cross-modality Signal Injection Attacks against LiDAR
Sep 26, 2024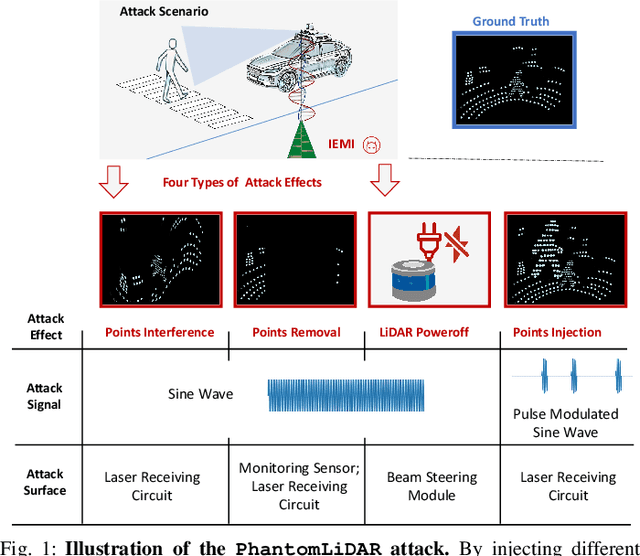
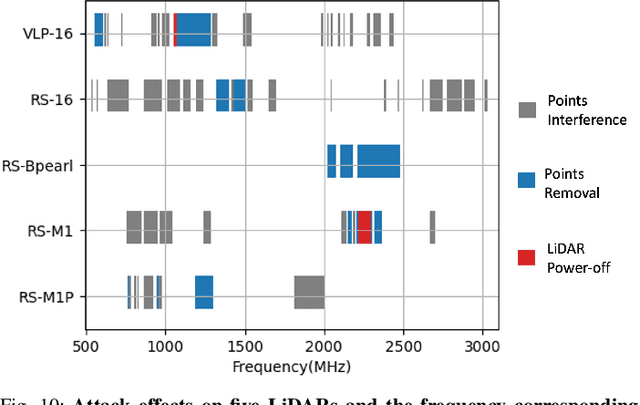
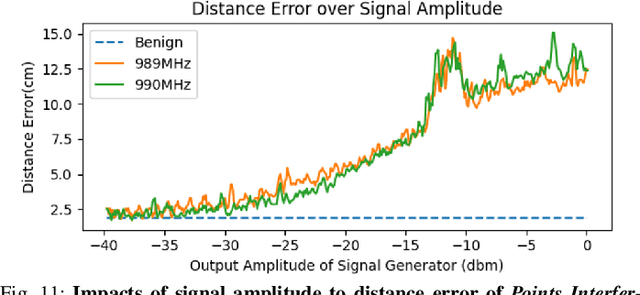
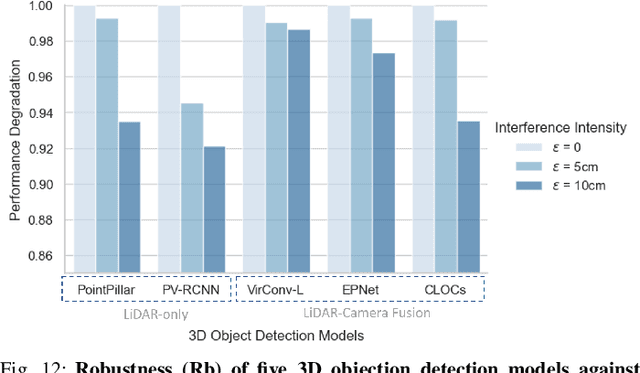
LiDAR (Light Detection and Ranging) is a pivotal sensor for autonomous driving, offering precise 3D spatial information. Previous signal attacks against LiDAR systems mainly exploit laser signals. In this paper, we investigate the possibility of cross-modality signal injection attacks, i.e., injecting intentional electromagnetic interference (IEMI) to manipulate LiDAR output. Our insight is that the internal modules of a LiDAR, i.e., the laser receiving circuit, the monitoring sensors, and the beam-steering modules, even with strict electromagnetic compatibility (EMC) testing, can still couple with the IEMI attack signals and result in the malfunction of LiDAR systems. Based on the above attack surfaces, we propose the PhantomLiDAR attack, which manipulates LiDAR output in terms of Points Interference, Points Injection, Points Removal, and even LiDAR Power-Off. We evaluate and demonstrate the effectiveness of PhantomLiDAR with both simulated and real-world experiments on five COTS LiDAR systems. We also conduct feasibility experiments in real-world moving scenarios. We provide potential defense measures that can be implemented at both the sensor level and the vehicle system level to mitigate the risks associated with IEMI attacks. Video demonstrations can be viewed at https://sites.google.com/view/phantomlidar.
SafeEar: Content Privacy-Preserving Audio Deepfake Detection
Sep 14, 2024



Text-to-Speech (TTS) and Voice Conversion (VC) models have exhibited remarkable performance in generating realistic and natural audio. However, their dark side, audio deepfake poses a significant threat to both society and individuals. Existing countermeasures largely focus on determining the genuineness of speech based on complete original audio recordings, which however often contain private content. This oversight may refrain deepfake detection from many applications, particularly in scenarios involving sensitive information like business secrets. In this paper, we propose SafeEar, a novel framework that aims to detect deepfake audios without relying on accessing the speech content within. Our key idea is to devise a neural audio codec into a novel decoupling model that well separates the semantic and acoustic information from audio samples, and only use the acoustic information (e.g., prosody and timbre) for deepfake detection. In this way, no semantic content will be exposed to the detector. To overcome the challenge of identifying diverse deepfake audio without semantic clues, we enhance our deepfake detector with real-world codec augmentation. Extensive experiments conducted on four benchmark datasets demonstrate SafeEar's effectiveness in detecting various deepfake techniques with an equal error rate (EER) down to 2.02%. Simultaneously, it shields five-language speech content from being deciphered by both machine and human auditory analysis, demonstrated by word error rates (WERs) all above 93.93% and our user study. Furthermore, our benchmark constructed for anti-deepfake and anti-content recovery evaluation helps provide a basis for future research in the realms of audio privacy preservation and deepfake detection.
SafeGen: Mitigating Unsafe Content Generation in Text-to-Image Models
Apr 10, 2024



Text-to-image (T2I) models, such as Stable Diffusion, have exhibited remarkable performance in generating high-quality images from text descriptions in recent years. However, text-to-image models may be tricked into generating not-safe-for-work (NSFW) content, particularly in sexual scenarios. Existing countermeasures mostly focus on filtering inappropriate inputs and outputs, or suppressing improper text embeddings, which can block explicit NSFW-related content (e.g., naked or sexy) but may still be vulnerable to adversarial prompts inputs that appear innocent but are ill-intended. In this paper, we present SafeGen, a framework to mitigate unsafe content generation by text-to-image models in a text-agnostic manner. The key idea is to eliminate unsafe visual representations from the model regardless of the text input. In this way, the text-to-image model is resistant to adversarial prompts since unsafe visual representations are obstructed from within. Extensive experiments conducted on four datasets demonstrate SafeGen's effectiveness in mitigating unsafe content generation while preserving the high-fidelity of benign images. SafeGen outperforms eight state-of-the-art baseline methods and achieves 99.1% sexual content removal performance. Furthermore, our constructed benchmark of adversarial prompts provides a basis for future development and evaluation of anti-NSFW-generation methods.