 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes a Global Perspective Help Prune Sparse MoEs Elegantly?
Apr 08, 2026Empirical scaling laws for language models have encouraged the development of ever-larger LLMs, despite their growing computational and memory costs. Sparse Mixture-of-Experts (MoEs) offer a promising alternative by activating only a subset of experts per forward pass, improving efficiency without sacrificing performance. However, the large number of expert parameters still leads to substantial memory consumption. Existing pruning methods typically allocate budgets uniformly across layers, overlooking the heterogeneous redundancy that arises in sparse MoEs. We propose GRAPE (Global Redundancy-Aware Pruning of Experts, a global pruning strategy that dynamically allocates pruning budgets based on cross-layer redundancy. Experiments on Mixtral-8x7B, Mixtral-8x22B, DeepSeek-MoE, Qwen-MoE, and GPT-OSS show that, under the same pruning budget, GRAPE consistently achieves the best average performance. On the three main models reported in the paper, it improves average accuracy over the strongest local baseline by 1.40% on average across pruning settings, with gains of up to 2.45%.
Why Instruction-Based Unlearning Fails in Diffusion Models?
Apr 02, 2026Instruction-based unlearning has proven effective for modifying the behavior of large language models at inference time, but whether this paradigm extends to other generative models remains unclear. In this work, we investigate instruction-based unlearning in diffusion-based image generation models and show, through controlled experiments across multiple concepts and prompt variants, that diffusion models systematically fail to suppress targeted concepts when guided solely by natural-language unlearning instructions. By analyzing both the CLIP text encoder and cross-attention dynamics during the denoising process, we find that unlearning instructions do not induce sustained reductions in attention to the targeted concept tokens, causing the targeted concept representations to persist throughout generation. These results reveal a fundamental limitation of prompt-level instruction in diffusion models and suggest that effective unlearning requires interventions beyond inference-time language control.
Video-LMM Post-Training: A Deep Dive into Video Reasoning with Large Multimodal Models
Oct 06, 2025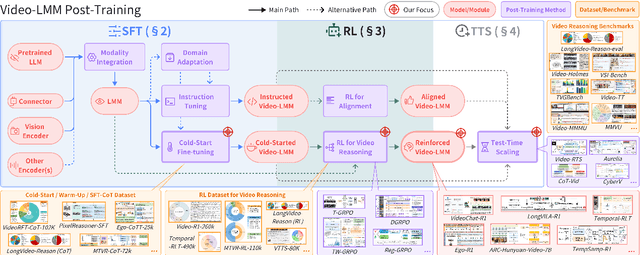
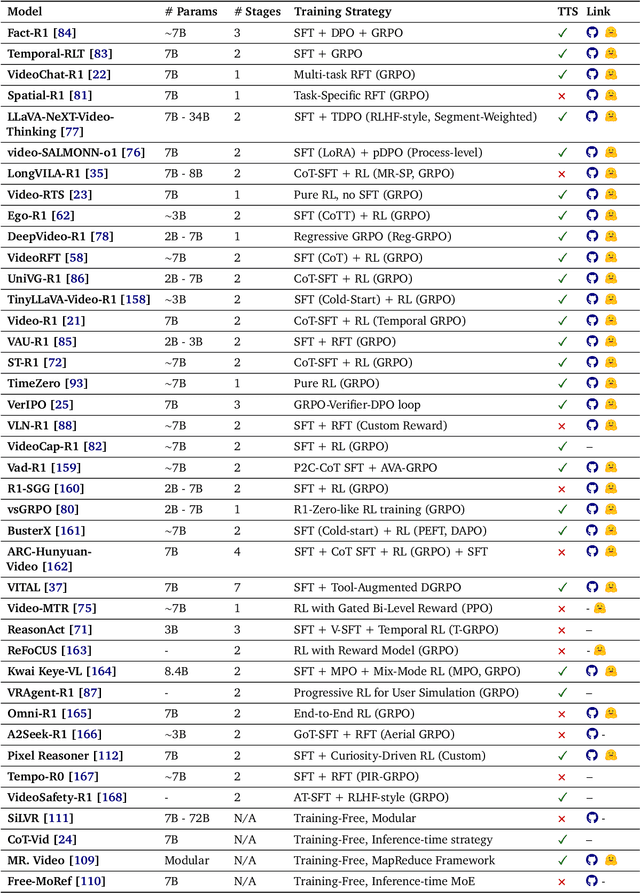
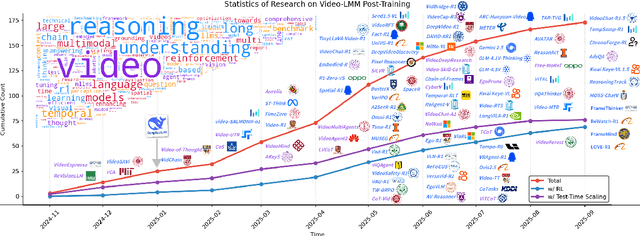
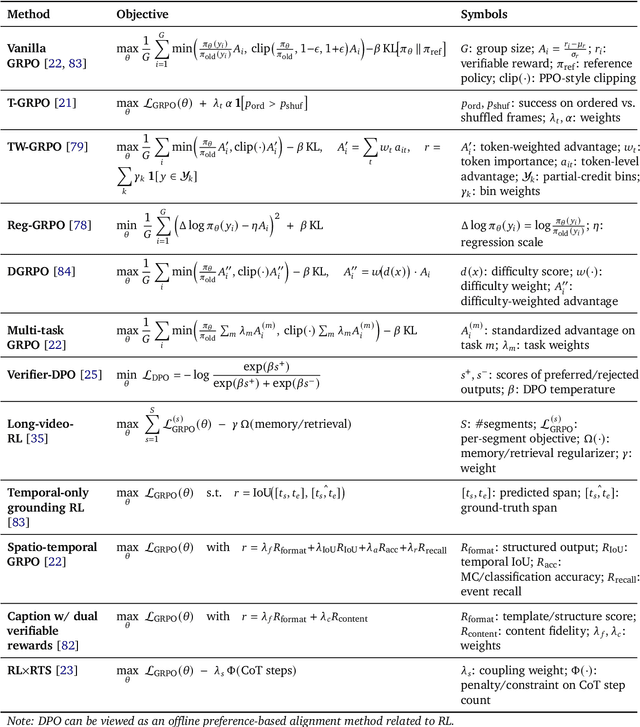
Video understanding represents the most challenging frontier in computer vision, requiring models to reason about complex spatiotemporal relationships, long-term dependencies, and multimodal evidence. The recent emergence of Video-Large Multimodal Models (Video-LMMs), which integrate visual encoders with powerful decoder-based language models, has demonstrated remarkable capabilities in video understanding tasks. However, the critical phase that transforms these models from basic perception systems into sophisticated reasoning engines, post-training, remains fragmented across the literature. This survey provides the first comprehensive examination of post-training methodologies for Video-LMMs, encompassing three fundamental pillars: supervised fine-tuning (SFT) with chain-of-thought, reinforcement learning (RL) from verifiable objectives, and test-time scaling (TTS) through enhanced inference computation. We present a structured taxonomy that clarifies the roles, interconnections, and video-specific adaptations of these techniques, addressing unique challenges such as temporal localization, spatiotemporal grounding, long video efficiency, and multimodal evidence integration. Through systematic analysis of representative methods, we synthesize key design principles, insights, and evaluation protocols while identifying critical open challenges in reward design, scalability, and cost-performance optimization. We further curate essential benchmarks, datasets, and metrics to facilitate rigorous assessment of post-training effectiveness. This survey aims to provide researchers and practitioners with a unified framework for advancing Video-LMM capabilities. Additional resources and updates are maintained at: https://github.com/yunlong10/Awesome-Video-LMM-Post-Training
The Sword of Damocles in ViTs: Computational Redundancy Amplifies Adversarial Transferability
Apr 15, 2025Vision Transformers (ViTs) have demonstrated impressive performance across a range of applications, including many safety-critical tasks. However, their unique architectural properties raise new challenges and opportunities in adversarial robustness. In particular, we observe that adversarial examples crafted on ViTs exhibit higher transferability compared to those crafted on CNNs, suggesting that ViTs contain structural characteristics favorable for transferable attacks. In this work, we investigate the role of computational redundancy in ViTs and its impact on adversarial transferability. Unlike prior studies that aim to reduce computation for efficiency, we propose to exploit this redundancy to improve the quality and transferability of adversarial examples. Through a detailed analysis, we identify two forms of redundancy, including the data-level and model-level, that can be harnessed to amplify attack effectiveness. Building on this insight, we design a suite of techniques, including attention sparsity manipulation, attention head permutation, clean token regularization, ghost MoE diversification, and test-time adversarial training. Extensive experiments on the ImageNet-1k dataset validate the effectiveness of our approach, showing that our methods significantly outperform existing baselines in both transferability and generality across diverse model architectures.
Tensor Polynomial Additive Model
Jun 05, 2024



Additive models can be used for interpretable machine learning for their clarity and simplicity. However, In the classical models for high-order data, the vectorization operation disrupts the data structure, which may lead to degenerated accuracy and increased computational complexity. To deal with these problems, we propose the tensor polynomial addition model (TPAM). It retains the multidimensional structure information of high-order inputs with tensor representation. The model parameter compression is achieved using a hierarchical and low-order symmetric tensor approximation. In this way, complex high-order feature interactions can be captured with fewer parameters. Moreover, The TPAM preserves the inherent interpretability of additive models, facilitating transparent decision-making and the extraction of meaningful feature values. Additionally, leveraging TPAM's transparency and ability to handle higher-order features, it is used as a post-processing module for other interpretation models by introducing two variants for class activation maps. Experimental results on a series of datasets demonstrate that TPAM can enhance accuracy by up to 30\%, and compression rate by up to 5 times, while maintaining a good interpretability.
How to Leverage Diverse Demonstrations in Offline Imitation Learning
May 29, 2024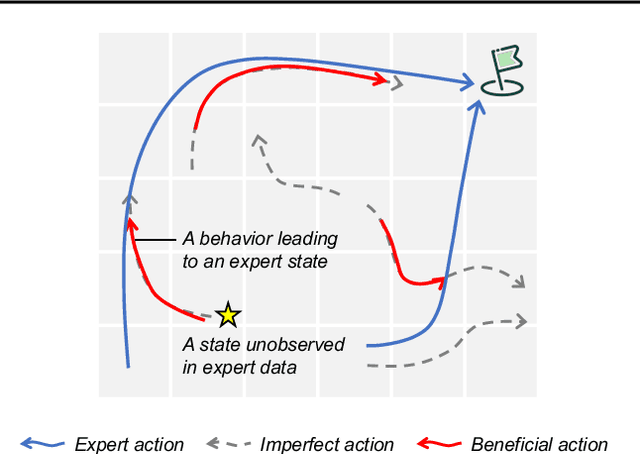
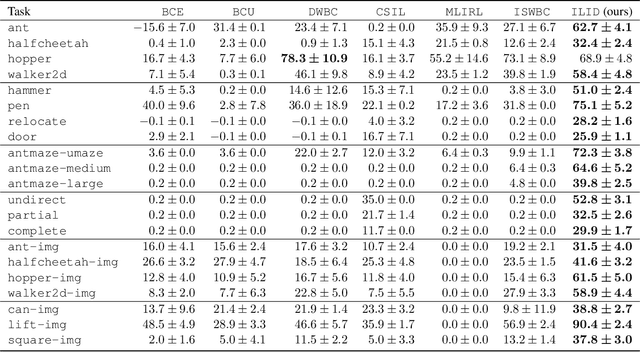
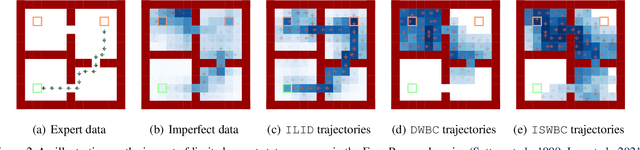
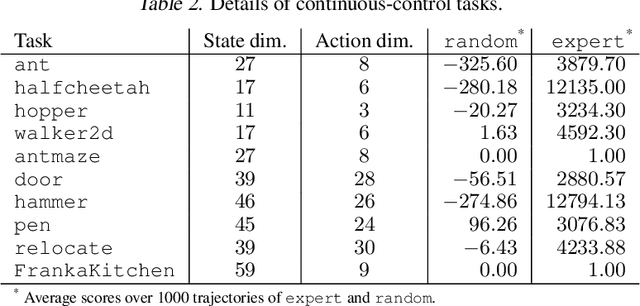
Offline Imitation Learning (IL) with imperfect demonstrations has garnered increasing attention owing to the scarcity of expert data in many real-world domains. A fundamental problem in this scenario is how to extract positive behaviors from noisy data. In general, current approaches to the problem select data building on state-action similarity to given expert demonstrations, neglecting precious information in (potentially abundant) $\textit{diverse}$ state-actions that deviate from expert ones. In this paper, we introduce a simple yet effective data selection method that identifies positive behaviors based on their resultant states -- a more informative criterion enabling explicit utilization of dynamics information and effective extraction of both expert and beneficial diverse behaviors. Further, we devise a lightweight behavior cloning algorithm capable of leveraging the expert and selected data correctly. In the experiments, we evaluate our method on a suite of complex and high-dimensional offline IL benchmarks, including continuous-control and vision-based tasks. The results demonstrate that our method achieves state-of-the-art performance, outperforming existing methods on $\textbf{20/21}$ benchmarks, typically by $\textbf{2-5x}$, while maintaining a comparable runtime to Behavior Cloning ($\texttt{BC}$).
CamPro: Camera-based Anti-Facial Recognition
Dec 30, 2023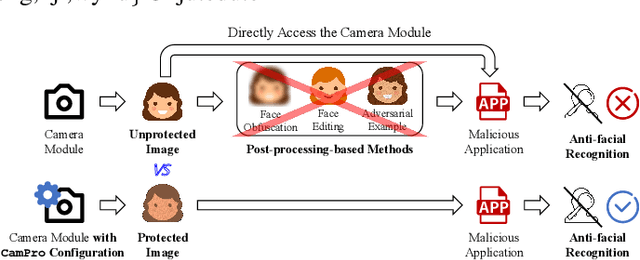

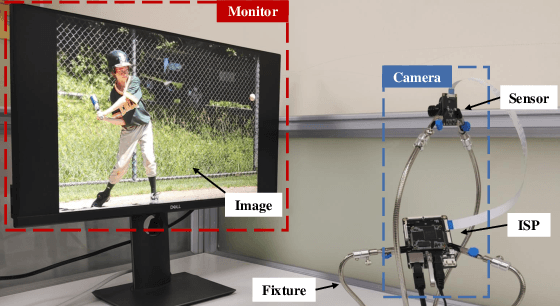

The proliferation of images captured from millions of cameras and the advancement of facial recognition (FR) technology have made the abuse of FR a severe privacy threat. Existing works typically rely on obfuscation, synthesis, or adversarial examples to modify faces in images to achieve anti-facial recognition (AFR). However, the unmodified images captured by camera modules that contain sensitive personally identifiable information (PII) could still be leaked. In this paper, we propose a novel approach, CamPro, to capture inborn AFR images. CamPro enables well-packed commodity camera modules to produce images that contain little PII and yet still contain enough information to support other non-sensitive vision applications, such as person detection. Specifically, CamPro tunes the configuration setup inside the camera image signal processor (ISP), i.e., color correction matrix and gamma correction, to achieve AFR, and designs an image enhancer to keep the image quality for possible human viewers. We implemented and validated CamPro on a proof-of-concept camera, and our experiments demonstrate its effectiveness on ten state-of-the-art black-box FR models. The results show that CamPro images can significantly reduce face identification accuracy to 0.3\% while having little impact on the targeted non-sensitive vision application. Furthermore, we find that CamPro is resilient to adaptive attackers who have re-trained their FR models using images generated by CamPro, even with full knowledge of privacy-preserving ISP parameters.
TERM Model: Tensor Ring Mixture Model for Density Estimation
Dec 13, 2023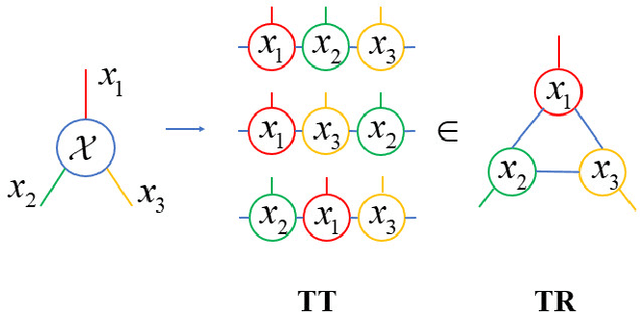
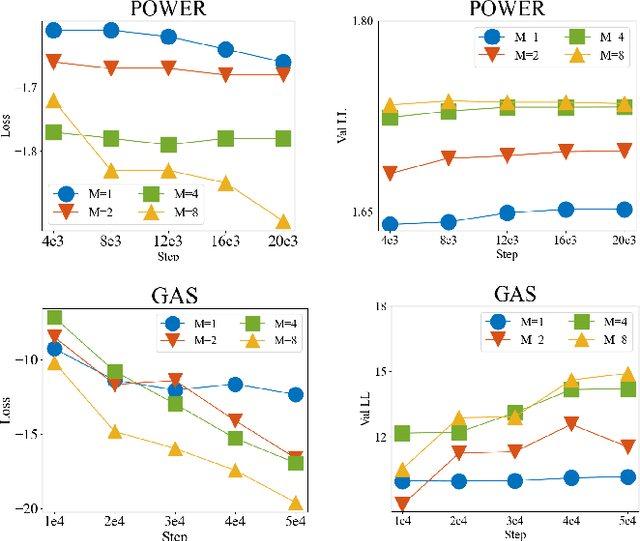
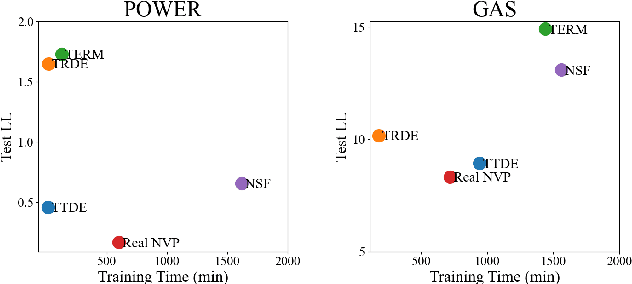
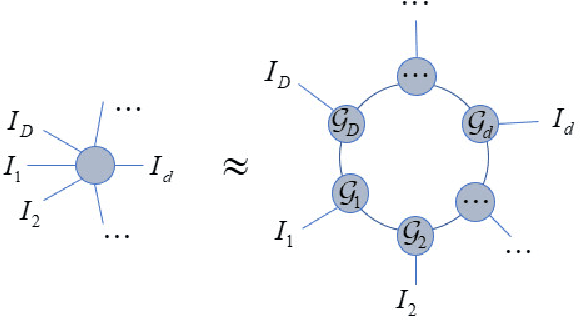
Efficient probability density estimation is a core challenge in statistical machine learning. Tensor-based probabilistic graph methods address interpretability and stability concerns encountered in neural network approaches. However, a substantial number of potential tensor permutations can lead to a tensor network with the same structure but varying expressive capabilities. In this paper, we take tensor ring decomposition for density estimator, which significantly reduces the number of permutation candidates while enhancing expressive capability compared with existing used decompositions. Additionally, a mixture model that incorporates multiple permutation candidates with adaptive weights is further designed, resulting in increased expressive flexibility and comprehensiveness. Different from the prevailing directions of tensor network structure/permutation search, our approach provides a new viewpoint inspired by ensemble learning. This approach acknowledges that suboptimal permutations can offer distinctive information besides that of optimal permutations. Experiments show the superiority of the proposed approach in estimating probability density for moderately dimensional datasets and sampling to capture intricate details.
Low-Rank Multitask Learning based on Tensorized SVMs and LSSVMs
Aug 30, 2023



Multitask learning (MTL) leverages task-relatedness to enhance performance. With the emergence of multimodal data, tasks can now be referenced by multiple indices. In this paper, we employ high-order tensors, with each mode corresponding to a task index, to naturally represent tasks referenced by multiple indices and preserve their structural relations. Based on this representation, we propose a general framework of low-rank MTL methods with tensorized support vector machines (SVMs) and least square support vector machines (LSSVMs), where the CP factorization is deployed over the coefficient tensor. Our approach allows to model the task relation through a linear combination of shared factors weighted by task-specific factors and is generalized to both classification and regression problems. Through the alternating optimization scheme and the Lagrangian function, each subproblem is transformed into a convex problem, formulated as a quadratic programming or linear system in the dual form. In contrast to previous MTL frameworks, our decision function in the dual induces a weighted kernel function with a task-coupling term characterized by the similarities of the task-specific factors, better revealing the explicit relations across tasks in MTL. Experimental results validate the effectiveness and superiority of our proposed methods compared to existing state-of-the-art approaches in MTL. The code of implementation will be available at https://github.com/liujiani0216/TSVM-MTL.
Tensor Regression
Aug 22, 2023Regression analysis is a key area of interest in the field of data analysis and machine learning which is devoted to exploring the dependencies between variables, often using vectors. The emergence of high dimensional data in technologies such as neuroimaging, computer vision, climatology and social networks, has brought challenges to traditional data representation methods. Tensors, as high dimensional extensions of vectors, are considered as natural representations of high dimensional data. In this book, the authors provide a systematic study and analysis of tensor-based regression models and their applications in recent years. It groups and illustrates the existing tensor-based regression methods and covers the basics, core ideas, and theoretical characteristics of most tensor-based regression methods. In addition, readers can learn how to use existing tensor-based regression methods to solve specific regression tasks with multiway data, what datasets can be selected, and what software packages are available to start related work as soon as possible. Tensor Regression is the first thorough overview of the fundamentals, motivations, popular algorithms, strategies for efficient implementation, related applications, available datasets, and software resources for tensor-based regression analysis. It is essential reading for all students, researchers and practitioners of working on high dimensional data.
* 187 pages, 32 figures, 10 tables