 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrAda-GAN: A Private Adaptive Generative Adversarial Network with Bayes Network Structure
Nov 11, 2025We revisit the problem of generating synthetic data under differential privacy. To address the core limitations of marginal-based methods, we propose the Private Adaptive Generative Adversarial Network with Bayes Network Structure (PrAda-GAN), which integrates the strengths of both GAN-based and marginal-based approaches. Our method adopts a sequential generator architecture to capture complex dependencies among variables, while adaptively regularizing the learned structure to promote sparsity in the underlying Bayes network. Theoretically, we establish diminishing bounds on the parameter distance, variable selection error, and Wasserstein distance. Our analysis shows that leveraging dependency sparsity leads to significant improvements in convergence rates. Empirically, experiments on both synthetic and real-world datasets demonstrate that PrAda-GAN outperforms existing tabular data synthesis methods in terms of the privacy-utility trade-off.
FedVLMBench: Benchmarking Federated Fine-Tuning of Vision-Language Models
Jun 11, 2025Vision-Language Models (VLMs) have demonstrated remarkable capabilities in cross-modal understanding and generation by integrating visual and textual information. While instruction tuning and parameter-efficient fine-tuning methods have substantially improved the generalization of VLMs, most existing approaches rely on centralized training, posing challenges for deployment in domains with strict privacy requirements like healthcare. Recent efforts have introduced Federated Learning (FL) into VLM fine-tuning to address these privacy concerns, yet comprehensive benchmarks for evaluating federated fine-tuning strategies, model architectures, and task generalization remain lacking. In this work, we present \textbf{FedVLMBench}, the first systematic benchmark for federated fine-tuning of VLMs. FedVLMBench integrates two mainstream VLM architectures (encoder-based and encoder-free), four fine-tuning strategies, five FL algorithms, six multimodal datasets spanning four cross-domain single-task scenarios and two cross-domain multitask settings, covering four distinct downstream task categories. Through extensive experiments, we uncover key insights into the interplay between VLM architectures, fine-tuning strategies, data heterogeneity, and multi-task federated optimization. Notably, we find that a 2-layer multilayer perceptron (MLP) connector with concurrent connector and LLM tuning emerges as the optimal configuration for encoder-based VLMs in FL. Furthermore, current FL methods exhibit significantly higher sensitivity to data heterogeneity in vision-centric tasks than text-centric ones, across both encoder-free and encoder-based VLM architectures. Our benchmark provides essential tools, datasets, and empirical guidance for the research community, offering a standardized platform to advance privacy-preserving, federated training of multimodal foundation models.
Exploring the Vulnerabilities of Federated Learning: A Deep Dive into Gradient Inversion Attacks
Mar 13, 2025
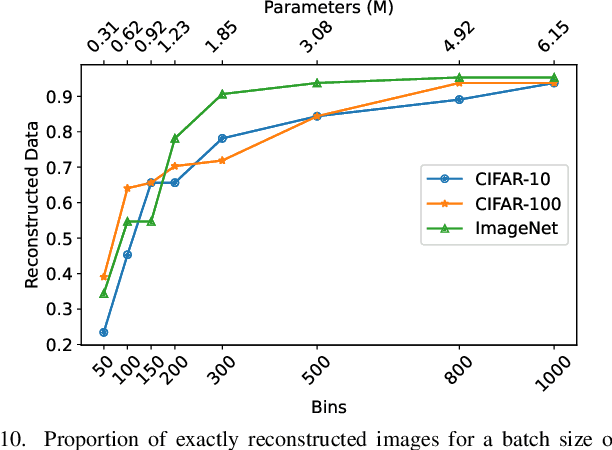
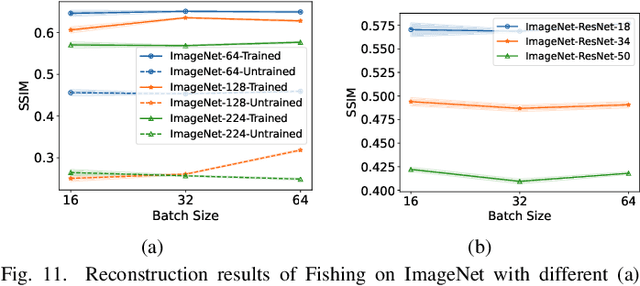
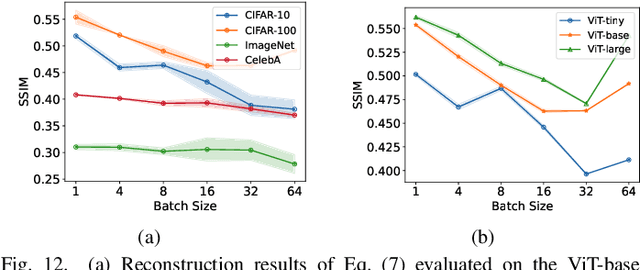
Federated Learning (FL) has emerged as a promising privacy-preserving collaborative model training paradigm without sharing raw data. However, recent studies have revealed that private information can still be leaked through shared gradient information and attacked by Gradient Inversion Attacks (GIA). While many GIA methods have been proposed, a detailed analysis, evaluation, and summary of these methods are still lacking. Although various survey papers summarize existing privacy attacks in FL, few studies have conducted extensive experiments to unveil the effectiveness of GIA and their associated limiting factors in this context. To fill this gap, we first undertake a systematic review of GIA and categorize existing methods into three types, i.e., \textit{optimization-based} GIA (OP-GIA), \textit{generation-based} GIA (GEN-GIA), and \textit{analytics-based} GIA (ANA-GIA). Then, we comprehensively analyze and evaluate the three types of GIA in FL, providing insights into the factors that influence their performance, practicality, and potential threats. Our findings indicate that OP-GIA is the most practical attack setting despite its unsatisfactory performance, while GEN-GIA has many dependencies and ANA-GIA is easily detectable, making them both impractical. Finally, we offer a three-stage defense pipeline to users when designing FL frameworks and protocols for better privacy protection and share some future research directions from the perspectives of attackers and defenders that we believe should be pursued. We hope that our study can help researchers design more robust FL frameworks to defend against these attacks.
Selective Aggregation for Low-Rank Adaptation in Federated Learning
Oct 02, 2024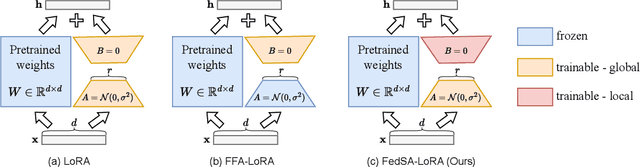
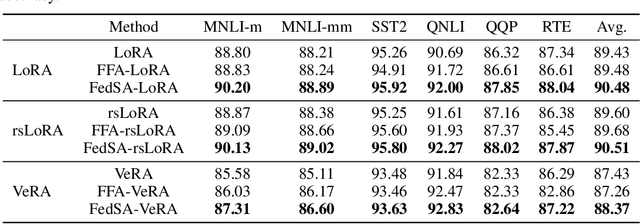
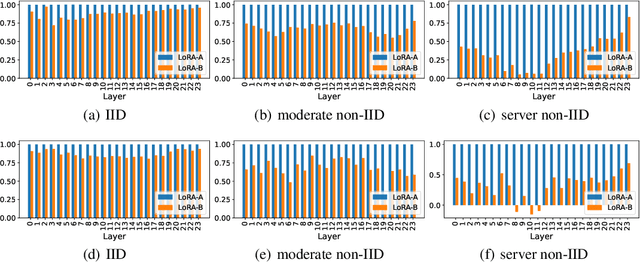
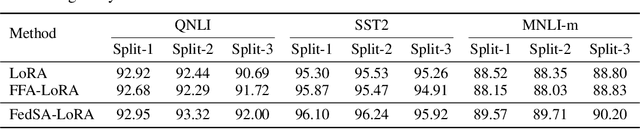
We investigate LoRA in federated learning through the lens of the asymmetry analysis of the learned $A$ and $B$ matrices. In doing so, we uncover that $A$ matrices are responsible for learning general knowledge, while $B$ matrices focus on capturing client-specific knowledge. Based on this finding, we introduce Federated Share-A Low-Rank Adaptation (FedSA-LoRA), which employs two low-rank trainable matrices $A$ and $B$ to model the weight update, but only $A$ matrices are shared with the server for aggregation. Moreover, we delve into the relationship between the learned $A$ and $B$ matrices in other LoRA variants, such as rsLoRA and VeRA, revealing a consistent pattern. Consequently, we extend our FedSA-LoRA method to these LoRA variants, resulting in FedSA-rsLoRA and FedSA-VeRA. In this way, we establish a general paradigm for integrating LoRA with FL, offering guidance for future work on subsequent LoRA variants combined with FL. Extensive experimental results on natural language understanding and generation tasks demonstrate the effectiveness of the proposed method.
A Selective Review on Statistical Methods for Massive Data Computation: Distributed Computing, Subsampling, and Minibatch Techniques
Mar 17, 2024This paper presents a selective review of statistical computation methods for massive data analysis. A huge amount of statistical methods for massive data computation have been rapidly developed in the past decades. In this work, we focus on three categories of statistical computation methods: (1) distributed computing, (2) subsampling methods, and (3) minibatch gradient techniques. The first class of literature is about distributed computing and focuses on the situation, where the dataset size is too huge to be comfortably handled by one single computer. In this case, a distributed computation system with multiple computers has to be utilized. The second class of literature is about subsampling methods and concerns about the situation, where the sample size of dataset is small enough to be placed on one single computer but too large to be easily processed by its memory as a whole. The last class of literature studies those minibatch gradient related optimization techniques, which have been extensively used for optimizing various deep learning models.
Face Swap via Diffusion Model
Mar 02, 2024This technical report presents a diffusion model based framework for face swapping between two portrait images. The basic framework consists of three components, i.e., IP-Adapter, ControlNet, and Stable Diffusion's inpainting pipeline, for face feature encoding, multi-conditional generation, and face inpainting respectively. Besides, I introduce facial guidance optimization and CodeFormer based blending to further improve the generation quality. Specifically, we engage a recent light-weighted customization method (i.e., DreamBooth-LoRA), to guarantee the identity consistency by 1) using a rare identifier "sks" to represent the source identity, and 2) injecting the image features of source portrait into each cross-attention layer like the text features. Then I resort to the strong inpainting ability of Stable Diffusion, and utilize canny image and face detection annotation of the target portrait as the conditions, to guide ContorlNet's generation and align source portrait with the target portrait. To further correct face alignment, we add the facial guidance loss to optimize the text embedding during the sample generation.
SimAC: A Simple Anti-Customization Method against Text-to-Image Synthesis of Diffusion Models
Dec 13, 2023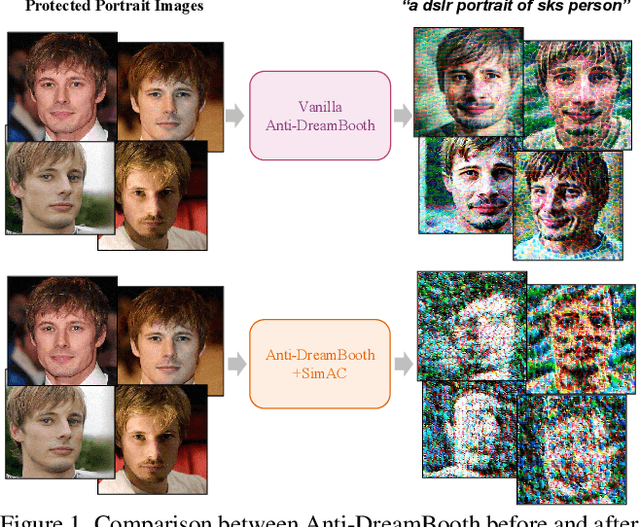
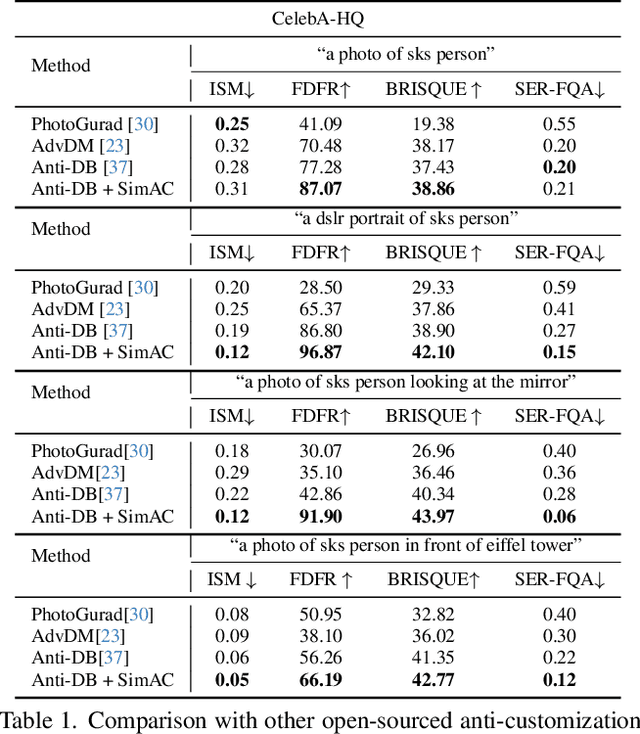
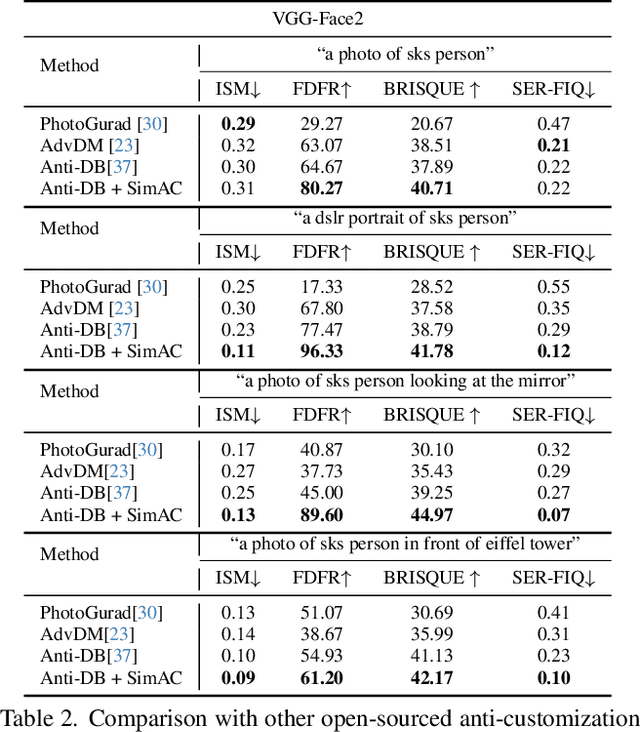
Despite the success of diffusion-based customization methods on visual content creation, increasing concerns have been raised about such techniques from both privacy and political perspectives. To tackle this issue, several anti-customization methods have been proposed in very recent months, predominantly grounded in adversarial attacks. Unfortunately, most of these methods adopt straightforward designs, such as end-to-end optimization with a focus on adversarially maximizing the original training loss, thereby neglecting nuanced internal properties intrinsic to the diffusion model, and even leading to ineffective optimization in some diffusion time steps. In this paper, we strive to bridge this gap by undertaking a comprehensive exploration of these inherent properties, to boost the performance of current anti-customization approaches. Two aspects of properties are investigated: 1) We examine the relationship between time step selection and the model's perception in the frequency domain of images and find that lower time steps can give much more contributions to adversarial noises. This inspires us to propose an adaptive greedy search for optimal time steps that seamlessly integrates with existing anti-customization methods. 2) We scrutinize the roles of features at different layers during denoising and devise a sophisticated feature-based optimization framework for anti-customization. Experiments on facial benchmarks demonstrate that our approach significantly increases identity disruption, thereby enhancing user privacy and security.
Factor-Assisted Federated Learning for Personalized Optimization with Heterogeneous Data
Dec 07, 2023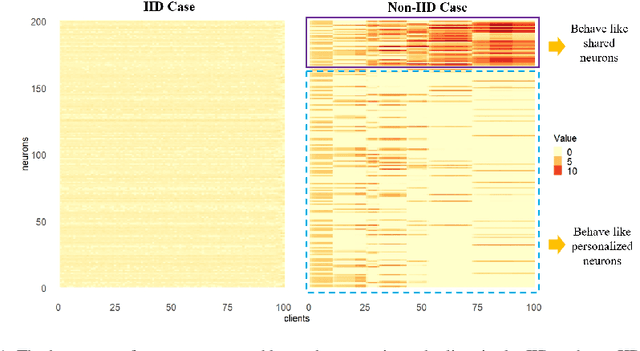
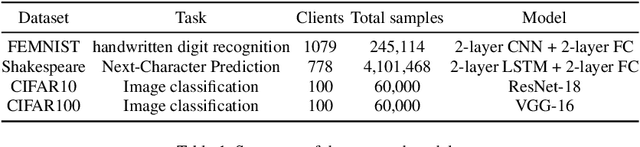
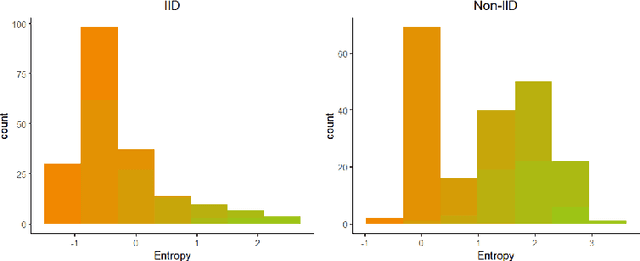
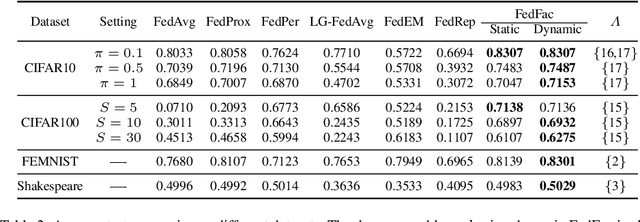
Federated learning is an emerging distributed machine learning framework aiming at protecting data privacy. Data heterogeneity is one of the core challenges in federated learning, which could severely degrade the convergence rate and prediction performance of deep neural networks. To address this issue, we develop a novel personalized federated learning framework for heterogeneous data, which we refer to as FedSplit. This modeling framework is motivated by the finding that, data in different clients contain both common knowledge and personalized knowledge. Then the hidden elements in each neural layer can be split into the shared and personalized groups. With this decomposition, a novel objective function is established and optimized. We demonstrate FedSplit enjoyers a faster convergence speed than the standard federated learning method both theoretically and empirically. The generalization bound of the FedSplit method is also studied. To practically implement the proposed method on real datasets, factor analysis is introduced to facilitate the decoupling of hidden elements. This leads to a practically implemented model for FedSplit and we further refer to as FedFac. We demonstrated by simulation studies that, using factor analysis can well recover the underlying shared/personalized decomposition. The superior prediction performance of FedFac is further verified empirically by comparison with various state-of-the-art federated learning methods on several real datasets.
Deep Learning Enables Large Depth-of-Field Images for Sub-Diffraction-Limit Scanning Superlens Microscopy
Oct 27, 2023



Scanning electron microscopy (SEM) is indispensable in diverse applications ranging from microelectronics to food processing because it provides large depth-of-field images with a resolution beyond the optical diffraction limit. However, the technology requires coating conductive films on insulator samples and a vacuum environment. We use deep learning to obtain the mapping relationship between optical super-resolution (OSR) images and SEM domain images, which enables the transformation of OSR images into SEM-like large depth-of-field images. Our custom-built scanning superlens microscopy (SSUM) system, which requires neither coating samples by conductive films nor a vacuum environment, is used to acquire the OSR images with features down to ~80 nm. The peak signal-to-noise ratio (PSNR) and structural similarity index measure values indicate that the deep learning method performs excellently in image-to-image translation, with a PSNR improvement of about 0.74 dB over the optical super-resolution images. The proposed method provides a high level of detail in the reconstructed results, indicating that it has broad applicability to chip-level defect detection, biological sample analysis, forensics, and various other fields.
Improved Naive Bayes with Mislabeled Data
Apr 13, 2023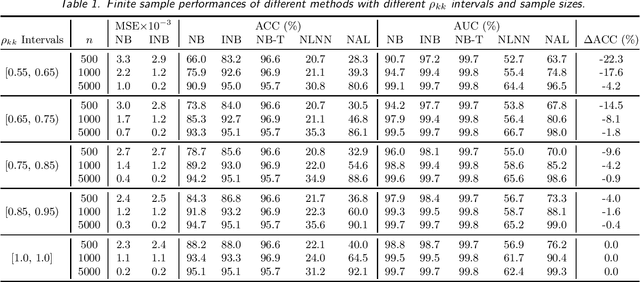
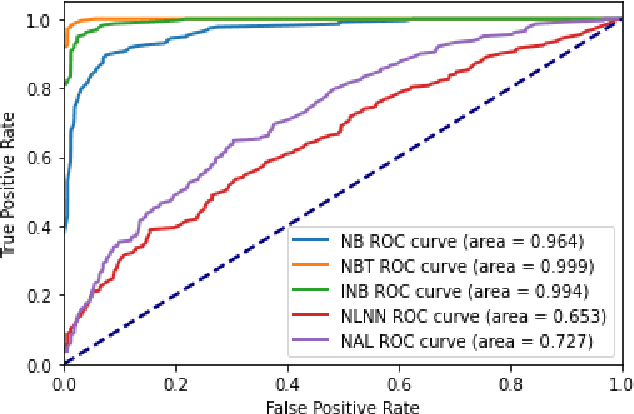

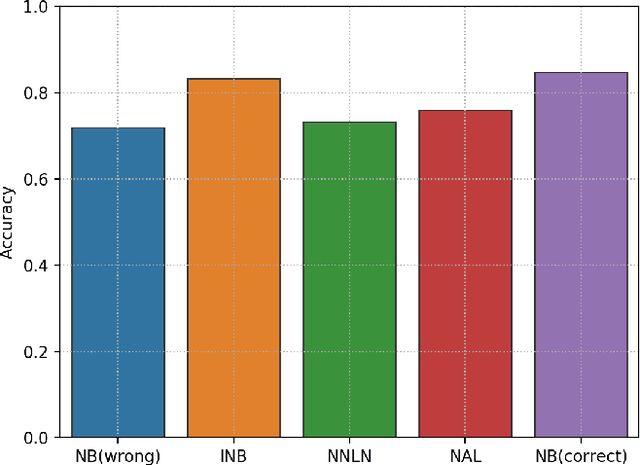
Labeling mistakes are frequently encountered in real-world applications. If not treated well, the labeling mistakes can deteriorate the classification performances of a model seriously. To address this issue, we propose an improved Naive Bayes method for text classification. It is analytically simple and free of subjective judgements on the correct and incorrect labels. By specifying the generating mechanism of incorrect labels, we optimize the corresponding log-likelihood function iteratively by using an EM algorithm. Our simulation and experiment results show that the improved Naive Bayes method greatly improves the performances of the Naive Bayes method with mislabeled data.