 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactor-Assisted Federated Learning for Personalized Optimization with Heterogeneous Data
Paper and Code
Dec 07, 2023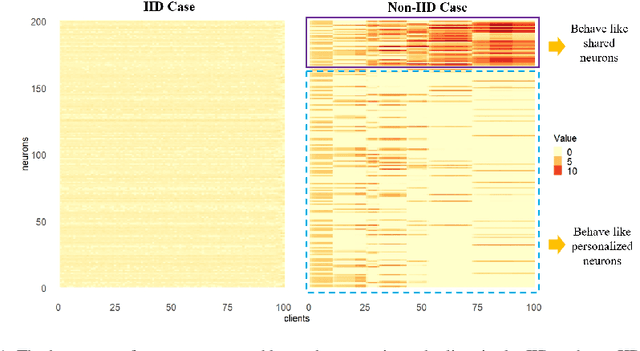
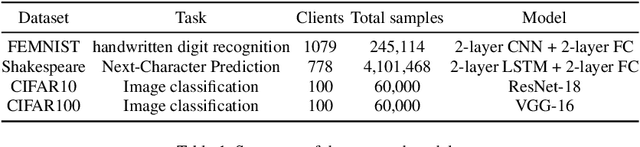
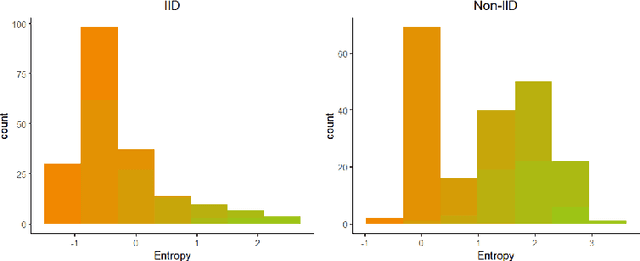
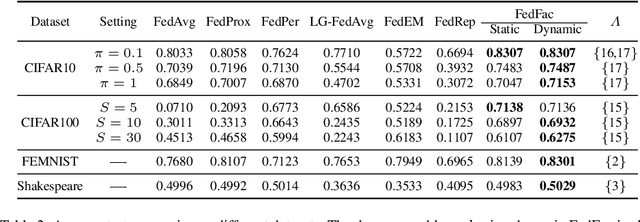
Federated learning is an emerging distributed machine learning framework aiming at protecting data privacy. Data heterogeneity is one of the core challenges in federated learning, which could severely degrade the convergence rate and prediction performance of deep neural networks. To address this issue, we develop a novel personalized federated learning framework for heterogeneous data, which we refer to as FedSplit. This modeling framework is motivated by the finding that, data in different clients contain both common knowledge and personalized knowledge. Then the hidden elements in each neural layer can be split into the shared and personalized groups. With this decomposition, a novel objective function is established and optimized. We demonstrate FedSplit enjoyers a faster convergence speed than the standard federated learning method both theoretically and empirically. The generalization bound of the FedSplit method is also studied. To practically implement the proposed method on real datasets, factor analysis is introduced to facilitate the decoupling of hidden elements. This leads to a practically implemented model for FedSplit and we further refer to as FedFac. We demonstrated by simulation studies that, using factor analysis can well recover the underlying shared/personalized decomposition. The superior prediction performance of FedFac is further verified empirically by comparison with various state-of-the-art federated learning methods on several real datasets.