 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective Aggregation for Low-Rank Adaptation in Federated Learning
Paper and Code
Oct 02, 2024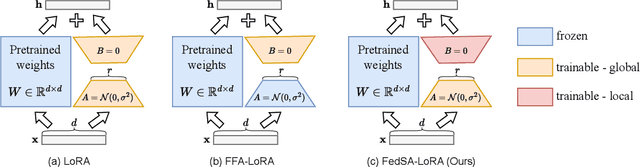
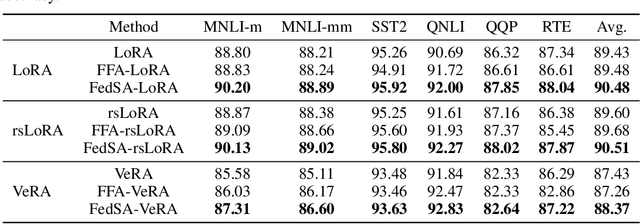
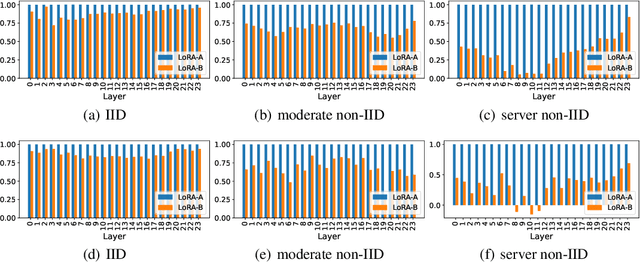
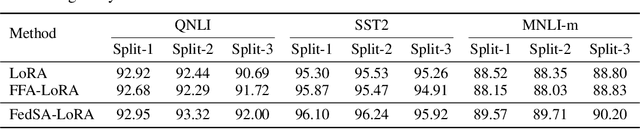
We investigate LoRA in federated learning through the lens of the asymmetry analysis of the learned $A$ and $B$ matrices. In doing so, we uncover that $A$ matrices are responsible for learning general knowledge, while $B$ matrices focus on capturing client-specific knowledge. Based on this finding, we introduce Federated Share-A Low-Rank Adaptation (FedSA-LoRA), which employs two low-rank trainable matrices $A$ and $B$ to model the weight update, but only $A$ matrices are shared with the server for aggregation. Moreover, we delve into the relationship between the learned $A$ and $B$ matrices in other LoRA variants, such as rsLoRA and VeRA, revealing a consistent pattern. Consequently, we extend our FedSA-LoRA method to these LoRA variants, resulting in FedSA-rsLoRA and FedSA-VeRA. In this way, we establish a general paradigm for integrating LoRA with FL, offering guidance for future work on subsequent LoRA variants combined with FL. Extensive experimental results on natural language understanding and generation tasks demonstrate the effectiveness of the proposed method.