 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRADA: Region-Aware Dual-encoder Auxiliary learning for Barely-supervised Medical Image Segmentation
Apr 13, 2026Deep learning has greatly advanced medical image segmentation, but its success relies heavily on fully supervised learning, which requires dense annotations that are costly and time-consuming for 3D volumetric scans. Barely-supervised learning reduces annotation burden by using only a few labeled slices per volume. Existing methods typically propagate sparse annotations to unlabeled slices through geometric continuity to generate pseudo-labels, but this strategy lacks semantic understanding, often resulting in low-quality pseudo-labels. Furthermore, medical image segmentation is inherently a pixel-level visual understanding task, where accuracy fundamentally depends on the quality of local, fine-grained visual features. Inspired by this, we propose RADA, a novel Region-Aware Dual-encoder Auxiliary learning pipeline which introduces a dual-encoder framework pre-trained on Alpha-CLIP to extract fine-grained, region-specific visual features from the original images and limited annotations. The framework combines image-level fine-grained visual features with text-level semantic guidance, providing region-aware semantic supervision that bridges image-level semantics and pixel-level segmentation. Integrated into a triple-view training framework, RADA achieves SOTA performance under extremely sparse annotation settings on LA2018, KiTS19 and LiTS, demonstrating robust generalization across diverse datasets.
ABot-PhysWorld: Interactive World Foundation Model for Robotic Manipulation with Physics Alignment
Mar 24, 2026Video-based world models offer a powerful paradigm for embodied simulation and planning, yet state-of-the-art models often generate physically implausible manipulations - such as object penetration and anti-gravity motion - due to training on generic visual data and likelihood-based objectives that ignore physical laws. We present ABot-PhysWorld, a 14B Diffusion Transformer model that generates visually realistic, physically plausible, and action-controllable videos. Built on a curated dataset of three million manipulation clips with physics-aware annotation, it uses a novel DPO-based post-training framework with decoupled discriminators to suppress unphysical behaviors while preserving visual quality. A parallel context block enables precise spatial action injection for cross-embodiment control. To better evaluate generalization, we introduce EZSbench, the first training-independent embodied zero-shot benchmark combining real and synthetic unseen robot-task-scene combinations. It employs a decoupled protocol to separately assess physical realism and action alignment. ABot-PhysWorld achieves new state-of-the-art performance on PBench and EZSbench, surpassing Veo 3.1 and Sora v2 Pro in physical plausibility and trajectory consistency. We will release EZSbench to promote standardized evaluation in embodied video generation.
MindDriver: Introducing Progressive Multimodal Reasoning for Autonomous Driving
Feb 25, 2026Vision-Language Models (VLM) exhibit strong reasoning capabilities, showing promise for end-to-end autonomous driving systems. Chain-of-Thought (CoT), as VLM's widely used reasoning strategy, is facing critical challenges. Existing textual CoT has a large gap between text semantic space and trajectory physical space. Although the recent approach utilizes future image to replace text as CoT process, it lacks clear planning-oriented objective guidance to generate images with accurate scene evolution. To address these, we innovatively propose MindDriver, a progressive multimodal reasoning framework that enables VLM to imitate human-like progressive thinking for autonomous driving. MindDriver presents semantic understanding, semantic-to-physical space imagination, and physical-space trajectory planning. To achieve aligned reasoning processes in MindDriver, we develop a feedback-guided automatic data annotation pipeline to generate aligned multimodal reasoning training data. Furthermore, we develop a progressive reinforcement fine-tuning method to optimize the alignment through progressive high- level reward-based learning. MindDriver demonstrates superior performance in both nuScences open-loop and Bench2Drive closed-loop evaluation. Codes are available at https://github.com/hotdogcheesewhite/MindDriver.
Geometry-as-context: Modulating Explicit 3D in Scene-consistent Video Generation to Geometry Context
Feb 25, 2026Scene-consistent video generation aims to create videos that explore 3D scenes based on a camera trajectory. Previous methods rely on video generation models with external memory for consistency, or iterative 3D reconstruction and inpainting, which accumulate errors during inference due to incorrect intermediary outputs, non-differentiable processes, and separate models. To overcome these limitations, we introduce ``geometry-as-context". It iteratively completes the following steps using an autoregressive camera-controlled video generation model: (1) estimates the geometry of the current view necessary for 3D reconstruction, and (2) simulates and restores novel view images rendered by the 3D scene. Under this multi-task framework, we develop the camera gated attention module to enhance the model's capability to effectively leverage camera poses. During the training phase, text contexts are utilized to ascertain whether geometric or RGB images should be generated. To ensure that the model can generate RGB-only outputs during inference, the geometry context is randomly dropped from the interleaved text-image-geometry training sequence. The method has been tested on scene video generation with one-direction and forth-and-back trajectories. The results show its superiority over previous approaches in maintaining scene consistency and camera control.
ABot-M0: VLA Foundation Model for Robotic Manipulation with Action Manifold Learning
Feb 11, 2026Building general-purpose embodied agents across diverse hardware remains a central challenge in robotics, often framed as the ''one-brain, many-forms'' paradigm. Progress is hindered by fragmented data, inconsistent representations, and misaligned training objectives. We present ABot-M0, a framework that builds a systematic data curation pipeline while jointly optimizing model architecture and training strategies, enabling end-to-end transformation of heterogeneous raw data into unified, efficient representations. From six public datasets, we clean, standardize, and balance samples to construct UniACT-dataset, a large-scale dataset with over 6 million trajectories and 9,500 hours of data, covering diverse robot morphologies and task scenarios. Unified pre-training improves knowledge transfer and generalization across platforms and tasks, supporting general-purpose embodied intelligence. To improve action prediction efficiency and stability, we propose the Action Manifold Hypothesis: effective robot actions lie not in the full high-dimensional space but on a low-dimensional, smooth manifold governed by physical laws and task constraints. Based on this, we introduce Action Manifold Learning (AML), which uses a DiT backbone to predict clean, continuous action sequences directly. This shifts learning from denoising to projection onto feasible manifolds, improving decoding speed and policy stability. ABot-M0 supports modular perception via a dual-stream mechanism that integrates VLM semantics with geometric priors and multi-view inputs from plug-and-play 3D modules such as VGGT and Qwen-Image-Edit, enhancing spatial understanding without modifying the backbone and mitigating standard VLM limitations in 3D reasoning. Experiments show components operate independently with additive benefits. We will release all code and pipelines for reproducibility and future research.
MerNav: A Highly Generalizable Memory-Execute-Review Framework for Zero-Shot Object Goal Navigation
Feb 05, 2026Visual Language Navigation (VLN) is one of the fundamental capabilities for embodied intelligence and a critical challenge that urgently needs to be addressed. However, existing methods are still unsatisfactory in terms of both success rate (SR) and generalization: Supervised Fine-Tuning (SFT) approaches typically achieve higher SR, while Training-Free (TF) approaches often generalize better, but it is difficult to obtain both simultaneously. To this end, we propose a Memory-Execute-Review framework. It consists of three parts: a hierarchical memory module for providing information support, an execute module for routine decision-making and actions, and a review module for handling abnormal situations and correcting behavior. We validated the effectiveness of this framework on the Object Goal Navigation task. Across 4 datasets, our average SR achieved absolute improvements of 7% and 5% compared to all baseline methods under TF and Zero-Shot (ZS) settings, respectively. On the most commonly used HM3D_v0.1 and the more challenging open vocabulary dataset HM3D_OVON, the SR improved by 8% and 6%, under ZS settings. Furthermore, on the MP3D and HM3D_OVON datasets, our method not only outperformed all TF methods but also surpassed all SFT methods, achieving comprehensive leadership in both SR (5% and 2%) and generalization.
Bridging Information Asymmetry: A Hierarchical Framework for Deterministic Blind Face Restoration
Jan 27, 2026Blind face restoration remains a persistent challenge due to the inherent ill-posedness of reconstructing holistic structures from severely constrained observations. Current generative approaches, while capable of synthesizing realistic textures, often suffer from information asymmetry -- the intrinsic disparity between the information-sparse low quality inputs and the information-dense high quality outputs. This imbalance leads to a one-to-many mapping, where insufficient constraints result in stochastic uncertainty and hallucinatory artifacts. To bridge this gap, we present \textbf{Pref-Restore}, a hierarchical framework that integrates discrete semantic logic with continuous texture generation to achieve deterministic, preference-aligned restoration. Our methodology fundamentally addresses this information disparity through two complementary strategies: (1) Augmenting Input Density: We employ an auto-regressive integrator to reformulate textual instructions into dense latent queries, injecting high-level semantic stability to constrain the degraded signals; (2) Pruning Output Distribution: We pioneer the integration of on-policy reinforcement learning directly into the diffusion restoration loop. By transforming human preferences into differentiable constraints, we explicitly penalize stochastic deviations, thereby sharpening the posterior distribution toward the desired high-fidelity outcomes. Extensive experiments demonstrate that Pref-Restore achieves state-of-the-art performance across synthetic and real-world benchmarks. Furthermore, empirical analysis confirms that our preference-aligned strategy significantly reduces solution entropy, establishing a robust pathway toward reliable and deterministic blind restoration.
AdaTok: Adaptive Token Compression with Object-Aware Representations for Efficient Multimodal LLMs
Nov 18, 2025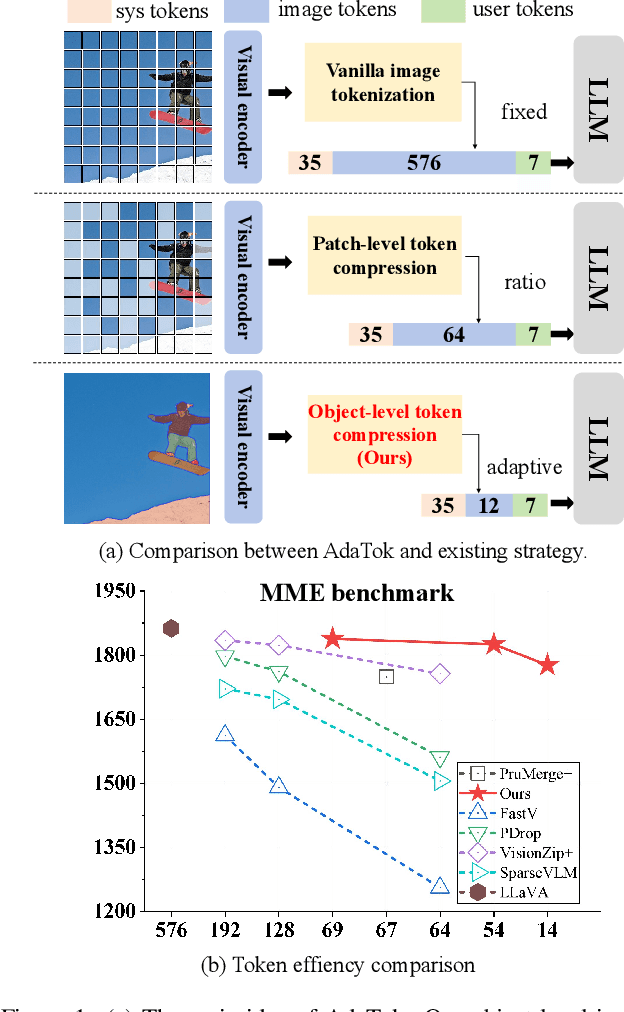
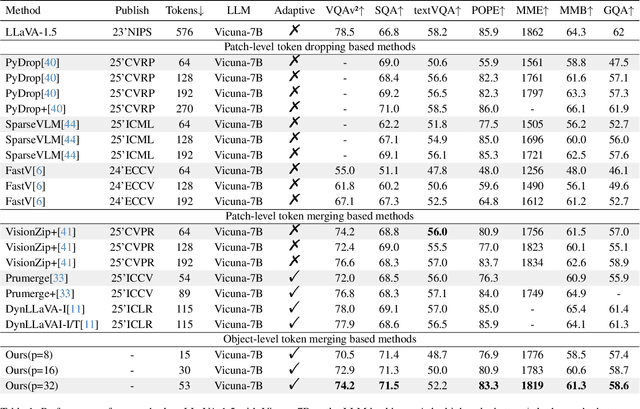
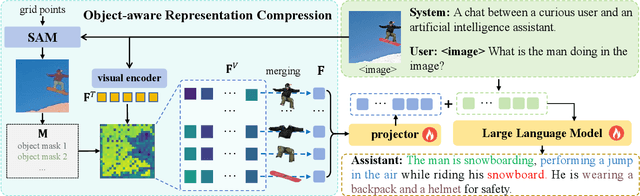
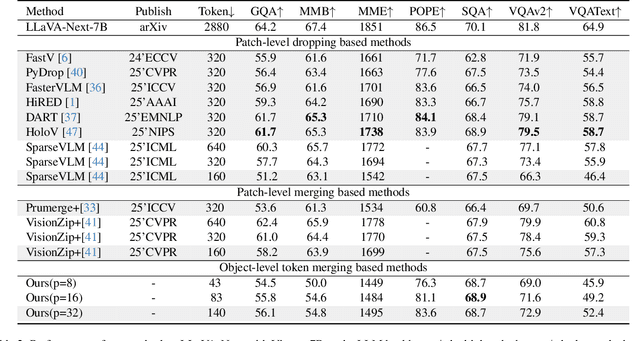
Multimodal Large Language Models (MLLMs) have demonstrated substantial value in unified text-image understanding and reasoning, primarily by converting images into sequences of patch-level tokens that align with their architectural paradigm. However, patch-level tokenization leads to a quadratic growth in image tokens, burdening MLLMs' understanding and reasoning with enormous computation and memory. Additionally, the traditional patch-wise scanning tokenization workflow misaligns with the human vision cognition system, further leading to hallucination and computational redundancy. To address this issue, we propose an object-level token merging strategy for Adaptive Token compression, revealing the consistency with human vision system. The experiments are conducted on multiple comprehensive benchmarks, which show that our approach averagely, utilizes only 10% tokens while achieving almost 96% of the vanilla model's performance. More extensive experimental results in comparison with relevant works demonstrate the superiority of our method in balancing compression ratio and performance. Our code will be available.
JanusVLN: Decoupling Semantics and Spatiality with Dual Implicit Memory for Vision-Language Navigation
Sep 26, 2025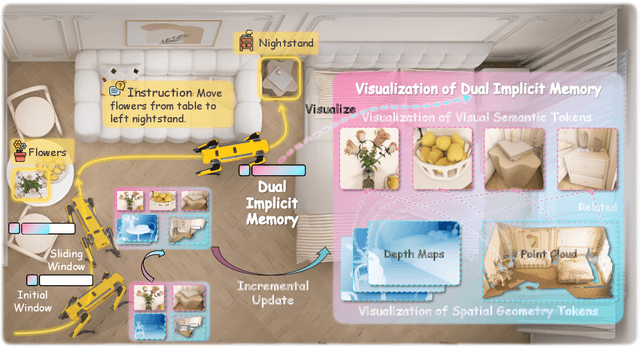
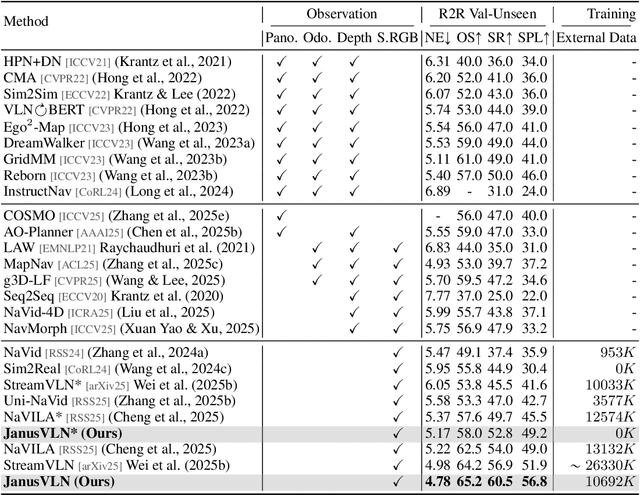
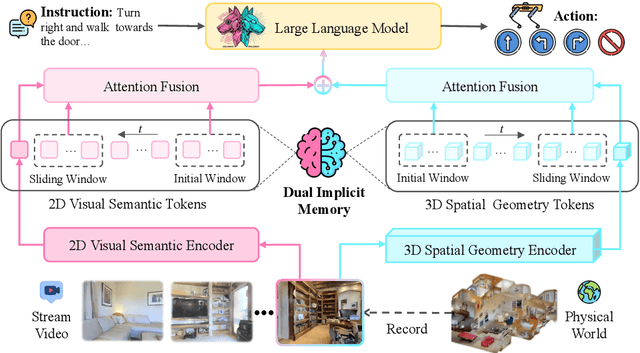
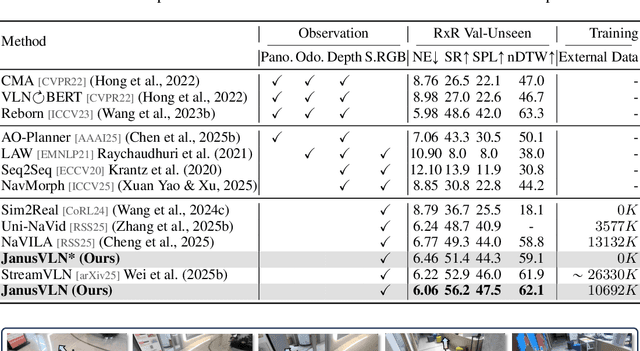
Vision-and-Language Navigation requires an embodied agent to navigate through unseen environments, guided by natural language instructions and a continuous video stream. Recent advances in VLN have been driven by the powerful semantic understanding of Multimodal Large Language Models. However, these methods typically rely on explicit semantic memory, such as building textual cognitive maps or storing historical visual frames. This type of method suffers from spatial information loss, computational redundancy, and memory bloat, which impede efficient navigation. Inspired by the implicit scene representation in human navigation, analogous to the left brain's semantic understanding and the right brain's spatial cognition, we propose JanusVLN, a novel VLN framework featuring a dual implicit neural memory that models spatial-geometric and visual-semantic memory as separate, compact, and fixed-size neural representations. This framework first extends the MLLM to incorporate 3D prior knowledge from the spatial-geometric encoder, thereby enhancing the spatial reasoning capabilities of models based solely on RGB input. Then, the historical key-value caches from the spatial-geometric and visual-semantic encoders are constructed into a dual implicit memory. By retaining only the KVs of tokens in the initial and sliding window, redundant computation is avoided, enabling efficient incremental updates. Extensive experiments demonstrate that JanusVLN outperforms over 20 recent methods to achieve SOTA performance. For example, the success rate improves by 10.5-35.5 compared to methods using multiple data types as input and by 3.6-10.8 compared to methods using more RGB training data. This indicates that the proposed dual implicit neural memory, as a novel paradigm, explores promising new directions for future VLN research. Ours project page: https://miv-xjtu.github.io/JanusVLN.github.io/.
UniMapGen: A Generative Framework for Large-Scale Map Construction from Multi-modal Data
Sep 26, 2025Large-scale map construction is foundational for critical applications such as autonomous driving and navigation systems. Traditional large-scale map construction approaches mainly rely on costly and inefficient special data collection vehicles and labor-intensive annotation processes. While existing satellite-based methods have demonstrated promising potential in enhancing the efficiency and coverage of map construction, they exhibit two major limitations: (1) inherent drawbacks of satellite data (e.g., occlusions, outdatedness) and (2) inefficient vectorization from perception-based methods, resulting in discontinuous and rough roads that require extensive post-processing. This paper presents a novel generative framework, UniMapGen, for large-scale map construction, offering three key innovations: (1) representing lane lines as \textbf{discrete sequence} and establishing an iterative strategy to generate more complete and smooth map vectors than traditional perception-based methods. (2) proposing a flexible architecture that supports \textbf{multi-modal} inputs, enabling dynamic selection among BEV, PV, and text prompt, to overcome the drawbacks of satellite data. (3) developing a \textbf{state update} strategy for global continuity and consistency of the constructed large-scale map. UniMapGen achieves state-of-the-art performance on the OpenSatMap dataset. Furthermore, UniMapGen can infer occluded roads and predict roads missing from dataset annotations. Our code will be released.