 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniMapGen: A Generative Framework for Large-Scale Map Construction from Multi-modal Data
Sep 26, 2025Large-scale map construction is foundational for critical applications such as autonomous driving and navigation systems. Traditional large-scale map construction approaches mainly rely on costly and inefficient special data collection vehicles and labor-intensive annotation processes. While existing satellite-based methods have demonstrated promising potential in enhancing the efficiency and coverage of map construction, they exhibit two major limitations: (1) inherent drawbacks of satellite data (e.g., occlusions, outdatedness) and (2) inefficient vectorization from perception-based methods, resulting in discontinuous and rough roads that require extensive post-processing. This paper presents a novel generative framework, UniMapGen, for large-scale map construction, offering three key innovations: (1) representing lane lines as \textbf{discrete sequence} and establishing an iterative strategy to generate more complete and smooth map vectors than traditional perception-based methods. (2) proposing a flexible architecture that supports \textbf{multi-modal} inputs, enabling dynamic selection among BEV, PV, and text prompt, to overcome the drawbacks of satellite data. (3) developing a \textbf{state update} strategy for global continuity and consistency of the constructed large-scale map. UniMapGen achieves state-of-the-art performance on the OpenSatMap dataset. Furthermore, UniMapGen can infer occluded roads and predict roads missing from dataset annotations. Our code will be released.
Image Clustering Algorithm Based on Self-Supervised Pretrained Models and Latent Feature Distribution Optimization
Aug 10, 2024In the face of complex natural images, existing deep clustering algorithms fall significantly short in terms of clustering accuracy when compared to supervised classification methods, making them less practical. This paper introduces an image clustering algorithm based on self-supervised pretrained models and latent feature distribution optimization, substantially enhancing clustering performance. It is found that: (1) For complex natural images, we effectively enhance the discriminative power of latent features by leveraging self-supervised pretrained models and their fine-tuning, resulting in improved clustering performance. (2) In the latent feature space, by searching for k-nearest neighbor images for each training sample and shortening the distance between the training sample and its nearest neighbor, the discriminative power of latent features can be further enhanced, and clustering performance can be improved. (3) In the latent feature space, reducing the distance between sample features and the nearest predefined cluster centroids can optimize the distribution of latent features, therefore further improving clustering performance. Through experiments on multiple datasets, our approach outperforms the latest clustering algorithms and achieves state-of-the-art clustering results. When the number of categories in the datasets is small, such as CIFAR-10 and STL-10, and there are significant differences between categories, our clustering algorithm has similar accuracy to supervised methods without using pretrained models, slightly lower than supervised methods using pre-trained models. The code linked algorithm is https://github.com/LihengHu/semi.
Self-Supervised Pretrained Models and Latent Feature Distribution Optimization
Aug 04, 2024In the face of complex natural images, existing deep clustering algorithms fall significantly short in terms of clustering accuracy when compared to supervised classification methods, making them less practical. This paper introduces an image clustering algorithm based on self-supervised pretrained models and latent feature distribution optimization, substantially enhancing clustering performance. It is found that: (1) For complex natural images, we effectively enhance the discriminative power of latent features by leveraging self-supervised pretrained models and their fine-tuning, resulting in improved clustering performance. (2) In the latent feature space, by searching for k-nearest neighbor images for each training sample and shortening the distance between the training sample and its nearest neighbor, the discriminative power of latent features can be further enhanced, and clustering performance can be improved. (3) In the latent feature space, reducing the distance between sample features and the nearest predefined cluster centroids can optimize the distribution of latent features, therefore further improving clustering performance. Through experiments on multiple datasets, our approach outperforms the latest clustering algorithms and achieves state-of-the-art clustering results. When the number of categories in the datasets is small, such as CIFAR-10 and STL-10, and there are significant differences between categories, our clustering algorithm has similar accuracy to supervised methods without using pretrained models, slightly lower than supervised methods using pre-trained models. The code linked algorithm is https://github.com/LihengHu/ICBPL.
Cross-modal Scene Graph Matching for Relationship-aware Image-Text Retrieval
Oct 11, 2019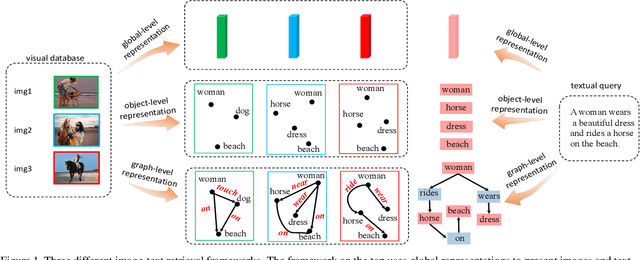
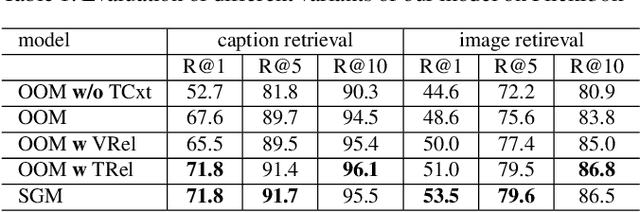

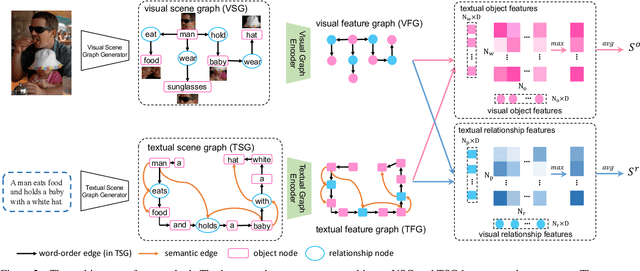
Image-text retrieval of natural scenes has been a popular research topic. Since image and text are heterogeneous cross-modal data, one of the key challenges is how to learn comprehensive yet unified representations to express the multi-modal data. A natural scene image mainly involves two kinds of visual concepts, objects and their relationships, which are equally essential to image-text retrieval. Therefore, a good representation should account for both of them. In the light of recent success of scene graph in many CV and NLP tasks for describing complex natural scenes, we propose to represent image and text with two kinds of scene graphs: visual scene graph (VSG) and textual scene graph (TSG), each of which is exploited to jointly characterize objects and relationships in the corresponding modality. The image-text retrieval task is then naturally formulated as cross-modal scene graph matching. Specifically, we design two particular scene graph encoders in our model for VSG and TSG, which can refine the representation of each node on the graph by aggregating neighborhood information. As a result, both object-level and relationship-level cross-modal features can be obtained, which favorably enables us to evaluate the similarity of image and text in the two levels in a more plausible way. We achieve state-of-the-art results on Flickr30k and MSCOCO, which verifies the advantages of our graph matching based approach for image-text retrieval.