 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Optimize Capacity Planning in Semiconductor Manufacturing
Sep 19, 2025In manufacturing, capacity planning is the process of allocating production resources in accordance with variable demand. The current industry practice in semiconductor manufacturing typically applies heuristic rules to prioritize actions, such as future change lists that account for incoming machine and recipe dedications. However, while offering interpretability, heuristics cannot easily account for the complex interactions along the process flow that can gradually lead to the formation of bottlenecks. Here, we present a neural network-based model for capacity planning on the level of individual machines, trained using deep reinforcement learning. By representing the policy using a heterogeneous graph neural network, the model directly captures the diverse relationships among machines and processing steps, allowing for proactive decision-making. We describe several measures taken to achieve sufficient scalability to tackle the vast space of possible machine-level actions. Our evaluation results cover Intel's small-scale Minifab model and preliminary experiments using the popular SMT2020 testbed. In the largest tested scenario, our trained policy increases throughput and decreases cycle time by about 1.8% each.
SubGCache: Accelerating Graph-based RAG with Subgraph-level KV Cache
May 19, 2025Graph-based retrieval-augmented generation (RAG) enables large language models (LLMs) to incorporate structured knowledge via graph retrieval as contextual input, enhancing more accurate and context-aware reasoning. We observe that for different queries, it could retrieve similar subgraphs as prompts, and thus we propose SubGCache, which aims to reduce inference latency by reusing computation across queries with similar structural prompts (i.e., subgraphs). Specifically, SubGCache clusters queries based on subgraph embeddings, constructs a representative subgraph for each cluster, and pre-computes the key-value (KV) cache of the representative subgraph. For each query with its retrieved subgraph within a cluster, it reuses the pre-computed KV cache of the representative subgraph of the cluster without computing the KV tensors again for saving computation. Experiments on two new datasets across multiple LLM backbones and graph-based RAG frameworks demonstrate that SubGCache consistently reduces inference latency with comparable and even improved generation quality, achieving up to 6.68$\times$ reduction in time-to-first-token (TTFT).
Image Clustering Algorithm Based on Self-Supervised Pretrained Models and Latent Feature Distribution Optimization
Aug 10, 2024In the face of complex natural images, existing deep clustering algorithms fall significantly short in terms of clustering accuracy when compared to supervised classification methods, making them less practical. This paper introduces an image clustering algorithm based on self-supervised pretrained models and latent feature distribution optimization, substantially enhancing clustering performance. It is found that: (1) For complex natural images, we effectively enhance the discriminative power of latent features by leveraging self-supervised pretrained models and their fine-tuning, resulting in improved clustering performance. (2) In the latent feature space, by searching for k-nearest neighbor images for each training sample and shortening the distance between the training sample and its nearest neighbor, the discriminative power of latent features can be further enhanced, and clustering performance can be improved. (3) In the latent feature space, reducing the distance between sample features and the nearest predefined cluster centroids can optimize the distribution of latent features, therefore further improving clustering performance. Through experiments on multiple datasets, our approach outperforms the latest clustering algorithms and achieves state-of-the-art clustering results. When the number of categories in the datasets is small, such as CIFAR-10 and STL-10, and there are significant differences between categories, our clustering algorithm has similar accuracy to supervised methods without using pretrained models, slightly lower than supervised methods using pre-trained models. The code linked algorithm is https://github.com/LihengHu/semi.
Self-Supervised Pretrained Models and Latent Feature Distribution Optimization
Aug 04, 2024In the face of complex natural images, existing deep clustering algorithms fall significantly short in terms of clustering accuracy when compared to supervised classification methods, making them less practical. This paper introduces an image clustering algorithm based on self-supervised pretrained models and latent feature distribution optimization, substantially enhancing clustering performance. It is found that: (1) For complex natural images, we effectively enhance the discriminative power of latent features by leveraging self-supervised pretrained models and their fine-tuning, resulting in improved clustering performance. (2) In the latent feature space, by searching for k-nearest neighbor images for each training sample and shortening the distance between the training sample and its nearest neighbor, the discriminative power of latent features can be further enhanced, and clustering performance can be improved. (3) In the latent feature space, reducing the distance between sample features and the nearest predefined cluster centroids can optimize the distribution of latent features, therefore further improving clustering performance. Through experiments on multiple datasets, our approach outperforms the latest clustering algorithms and achieves state-of-the-art clustering results. When the number of categories in the datasets is small, such as CIFAR-10 and STL-10, and there are significant differences between categories, our clustering algorithm has similar accuracy to supervised methods without using pretrained models, slightly lower than supervised methods using pre-trained models. The code linked algorithm is https://github.com/LihengHu/ICBPL.
HHGT: Hierarchical Heterogeneous Graph Transformer for Heterogeneous Graph Representation Learning
Jul 18, 2024


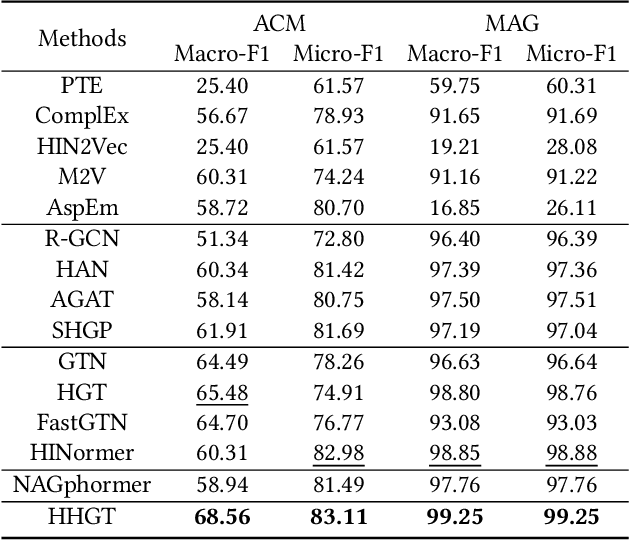
Despite the success of Heterogeneous Graph Neural Networks (HGNNs) in modeling real-world Heterogeneous Information Networks (HINs), challenges such as expressiveness limitations and over-smoothing have prompted researchers to explore Graph Transformers (GTs) for enhanced HIN representation learning. However, research on GT in HINs remains limited, with two key shortcomings in existing work: (1) A node's neighbors at different distances in HINs convey diverse semantics. Unfortunately, existing methods ignore such differences and uniformly treat neighbors within a given distance in a coarse manner, which results in semantic confusion. (2) Nodes in HINs have various types, each with unique semantics. Nevertheless, existing methods mix nodes of different types during neighbor aggregation, hindering the capture of proper correlations between nodes of diverse types. To bridge these gaps, we design an innovative structure named (k,t)-ring neighborhood, where nodes are initially organized by their distance, forming different non-overlapping k-ring neighborhoods for each distance. Within each k-ring structure, nodes are further categorized into different groups according to their types, thus emphasizing the heterogeneity of both distances and types in HINs naturally. Based on this structure, we propose a novel Hierarchical Heterogeneous Graph Transformer (HHGT) model, which seamlessly integrates a Type-level Transformer for aggregating nodes of different types within each k-ring neighborhood, followed by a Ring-level Transformer for aggregating different k-ring neighborhoods in a hierarchical manner. Extensive experiments are conducted on downstream tasks to verify HHGT's superiority over 14 baselines, with a notable improvement of up to 24.75% in NMI and 29.25% in ARI for node clustering task on the ACM dataset compared to the best baseline.
Out-of-distribution detection based on subspace projection of high-dimensional features output by the last convolutional layer
May 02, 2024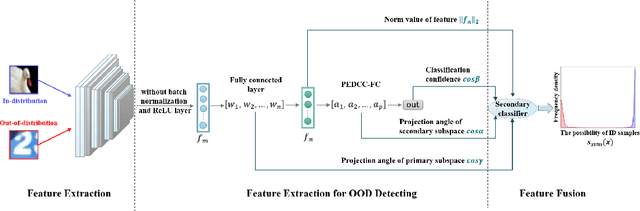
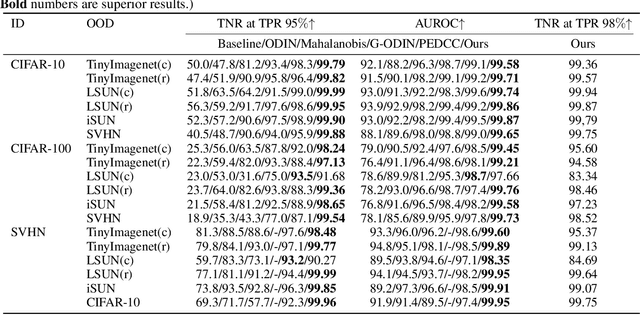
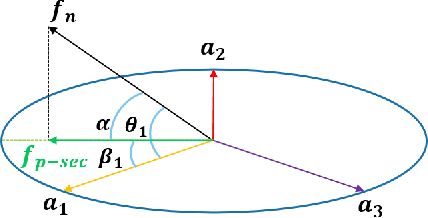
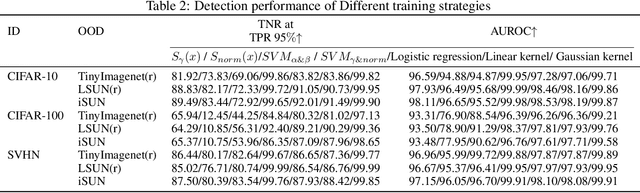
Out-of-distribution (OOD) detection, crucial for reliable pattern classification, discerns whether a sample originates outside the training distribution. This paper concentrates on the high-dimensional features output by the final convolutional layer, which contain rich image features. Our key idea is to project these high-dimensional features into two specific feature subspaces, leveraging the dimensionality reduction capacity of the network's linear layers, trained with Predefined Evenly-Distribution Class Centroids (PEDCC)-Loss. This involves calculating the cosines of three projection angles and the norm values of features, thereby identifying distinctive information for in-distribution (ID) and OOD data, which assists in OOD detection. Building upon this, we have modified the batch normalization (BN) and ReLU layer preceding the fully connected layer, diminishing their impact on the output feature distributions and thereby widening the distribution gap between ID and OOD data features. Our method requires only the training of the classification network model, eschewing any need for input pre-processing or specific OOD data pre-tuning. Extensive experiments on several benchmark datasets demonstrates that our approach delivers state-of-the-art performance. Our code is available at https://github.com/Hewell0/ProjOOD.
Multi-stage feature decorrelation constraints for improving CNN classification performance
Aug 24, 2023
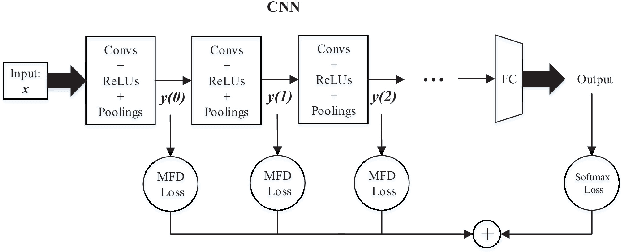
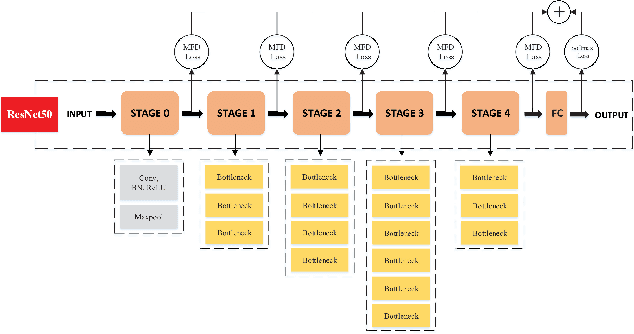

For the convolutional neural network (CNN) used for pattern classification, the training loss function is usually applied to the final output of the network, except for some regularization constraints on the network parameters. However, with the increasing of the number of network layers, the influence of the loss function on the network front layers gradually decreases, and the network parameters tend to fall into local optimization. At the same time, it is found that the trained network has significant information redundancy at all stages of features, which reduces the effectiveness of feature mapping at all stages and is not conducive to the change of the subsequent parameters of the network in the direction of optimality. Therefore, it is possible to obtain a more optimized solution of the network and further improve the classification accuracy of the network by designing a loss function for restraining the front stage features and eliminating the information redundancy of the front stage features .For CNN, this article proposes a multi-stage feature decorrelation loss (MFD Loss), which refines effective features and eliminates information redundancy by constraining the correlation of features at all stages. Considering that there are many layers in CNN, through experimental comparison and analysis, MFD Loss acts on multiple front layers of CNN, constrains the output features of each layer and each channel, and performs supervision training jointly with classification loss function during network training. Compared with the single Softmax Loss supervised learning, the experiments on several commonly used datasets on several typical CNNs prove that the classification performance of Softmax Loss+MFD Loss is significantly better. Meanwhile, the comparison experiments before and after the combination of MFD Loss and some other typical loss functions verify its good universality.
Effective Out-of-Distribution Detection in Classifier Based on PEDCC-Loss
Apr 10, 2022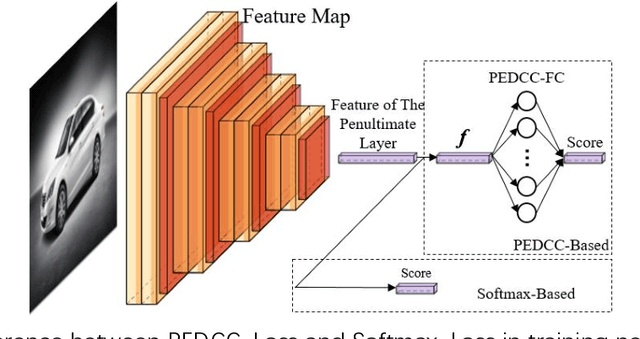



Deep neural networks suffer from the overconfidence issue in the open world, meaning that classifiers could yield confident, incorrect predictions for out-of-distribution (OOD) samples. Thus, it is an urgent and challenging task to detect these samples drawn far away from training distribution based on the security considerations of artificial intelligence. Many current methods based on neural networks mainly rely on complex processing strategies, such as temperature scaling and input preprocessing, to obtain satisfactory results. In this paper, we propose an effective algorithm for detecting out-of-distribution examples utilizing PEDCC-Loss. We mathematically analyze the nature of the confidence score output by the PEDCC (Predefined Evenly-Distribution Class Centroids) classifier, and then construct a more effective scoring function to distinguish in-distribution (ID) and out-of-distribution. In this method, there is no need to preprocess the input samples and the computational burden of the algorithm is reduced. Experiments demonstrate that our method can achieve better OOD detection performance.
A Softmax-free Loss Function Based on Predefined Optimal-distribution of Latent Features for CNN Classifier
Nov 25, 2021



In the field of pattern classification, the training of convolutional neural network classifiers is mostly end-to-end learning, and the loss function is the constraint on the final output (posterior probability) of the network, so the existence of Softmax is essential. In the case of end-to-end learning, there is usually no effective loss function that completely relies on the features of the middle layer to restrict learning, resulting in the distribution of sample latent features is not optimal, so there is still room for improvement in classification accuracy. Based on the concept of Predefined Evenly-Distributed Class Centroids (PEDCC), this article proposes a Softmax-free loss function (POD Loss) based on predefined optimal-distribution of latent features. The loss function only restricts the latent features of the samples, including the cosine distance between the latent feature vector of the sample and the center of the predefined evenly-distributed class, and the correlation between the latent features of the samples. Finally, cosine distance is used for classification. Compared with the commonly used Softmax Loss and the typical Softmax related AM-Softmax Loss, COT-Loss and PEDCC-Loss, experiments on several commonly used datasets on a typical network show that the classification performance of POD Loss is always better and easier to converge. Code is available in https://github.com/TianYuZu/POD-Loss.
Single Underwater Image Enhancement Using an Analysis-Synthesis Network
Aug 20, 2021



Most deep models for underwater image enhancement resort to training on synthetic datasets based on underwater image formation models. Although promising performances have been achieved, they are still limited by two problems: (1) existing underwater image synthesis models have an intrinsic limitation, in which the homogeneous ambient light is usually randomly generated and many important dependencies are ignored, and thus the synthesized training data cannot adequately express characteristics of real underwater environments; (2) most of deep models disregard lots of favorable underwater priors and heavily rely on training data, which extensively limits their application ranges. To address these limitations, a new underwater synthetic dataset is first established, in which a revised ambient light synthesis equation is embedded. The revised equation explicitly defines the complex mathematical relationship among intensity values of the ambient light in RGB channels and many dependencies such as surface-object depth, water types, etc, which helps to better simulate real underwater scene appearances. Secondly, a unified framework is proposed, named ANA-SYN, which can effectively enhance underwater images under collaborations of priors (underwater domain knowledge) and data information (underwater distortion distribution). The proposed framework includes an analysis network and a synthesis network, one for priors exploration and another for priors integration. To exploit more accurate priors, the significance of each prior for the input image is explored in the analysis network and an adaptive weighting module is designed to dynamically recalibrate them. Meanwhile, a novel prior guidance module is introduced in the synthesis network, which effectively aggregates the prior and data features and thus provides better hybrid information to perform the more reasonable image enhancement.