 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-stage feature decorrelation constraints for improving CNN classification performance
Aug 24, 2023
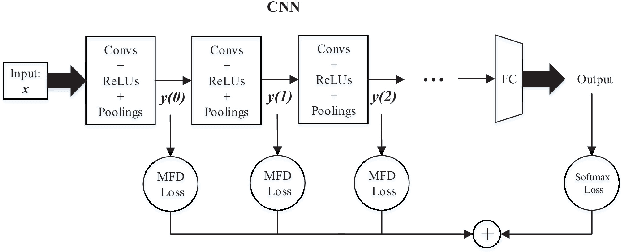

For the convolutional neural network (CNN) used for pattern classification, the training loss function is usually applied to the final output of the network, except for some regularization constraints on the network parameters. However, with the increasing of the number of network layers, the influence of the loss function on the network front layers gradually decreases, and the network parameters tend to fall into local optimization. At the same time, it is found that the trained network has significant information redundancy at all stages of features, which reduces the effectiveness of feature mapping at all stages and is not conducive to the change of the subsequent parameters of the network in the direction of optimality. Therefore, it is possible to obtain a more optimized solution of the network and further improve the classification accuracy of the network by designing a loss function for restraining the front stage features and eliminating the information redundancy of the front stage features .For CNN, this article proposes a multi-stage feature decorrelation loss (MFD Loss), which refines effective features and eliminates information redundancy by constraining the correlation of features at all stages. Considering that there are many layers in CNN, through experimental comparison and analysis, MFD Loss acts on multiple front layers of CNN, constrains the output features of each layer and each channel, and performs supervision training jointly with classification loss function during network training. Compared with the single Softmax Loss supervised learning, the experiments on several commonly used datasets on several typical CNNs prove that the classification performance of Softmax Loss+MFD Loss is significantly better. Meanwhile, the comparison experiments before and after the combination of MFD Loss and some other typical loss functions verify its good universality.
A Softmax-free Loss Function Based on Predefined Optimal-distribution of Latent Features for CNN Classifier
Nov 25, 2021



In the field of pattern classification, the training of convolutional neural network classifiers is mostly end-to-end learning, and the loss function is the constraint on the final output (posterior probability) of the network, so the existence of Softmax is essential. In the case of end-to-end learning, there is usually no effective loss function that completely relies on the features of the middle layer to restrict learning, resulting in the distribution of sample latent features is not optimal, so there is still room for improvement in classification accuracy. Based on the concept of Predefined Evenly-Distributed Class Centroids (PEDCC), this article proposes a Softmax-free loss function (POD Loss) based on predefined optimal-distribution of latent features. The loss function only restricts the latent features of the samples, including the cosine distance between the latent feature vector of the sample and the center of the predefined evenly-distributed class, and the correlation between the latent features of the samples. Finally, cosine distance is used for classification. Compared with the commonly used Softmax Loss and the typical Softmax related AM-Softmax Loss, COT-Loss and PEDCC-Loss, experiments on several commonly used datasets on a typical network show that the classification performance of POD Loss is always better and easier to converge. Code is available in https://github.com/TianYuZu/POD-Loss.