 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Compression for Cloud-Edge Multimodal 3D Object Detection
Sep 06, 2024



Machine vision systems, which can efficiently manage extensive visual perception tasks, are becoming increasingly popular in industrial production and daily life. Due to the challenge of simultaneously obtaining accurate depth and texture information with a single sensor, multimodal data captured by cameras and LiDAR is commonly used to enhance performance. Additionally, cloud-edge cooperation has emerged as a novel computing approach to improve user experience and ensure data security in machine vision systems. This paper proposes a pioneering solution to address the feature compression problem in multimodal 3D object detection. Given a sparse tensor-based object detection network at the edge device, we introduce two modes to accommodate different application requirements: Transmission-Friendly Feature Compression (T-FFC) and Accuracy-Friendly Feature Compression (A-FFC). In T-FFC mode, only the output of the last layer of the network's backbone is transmitted from the edge device. The received feature is processed at the cloud device through a channel expansion module and two spatial upsampling modules to generate multi-scale features. In A-FFC mode, we expand upon the T-FFC mode by transmitting two additional types of features. These added features enable the cloud device to generate more accurate multi-scale features. Experimental results on the KITTI dataset using the VirConv-L detection network showed that T-FFC was able to compress the features by a factor of 6061 with less than a 3% reduction in detection performance. On the other hand, A-FFC compressed the features by a factor of about 901 with almost no degradation in detection performance. We also designed optional residual extraction and 3D object reconstruction modules to facilitate the reconstruction of detected objects. The reconstructed objects effectively reflected details of the original objects.
3DAttGAN: A 3D Attention-based Generative Adversarial Network for Joint Space-Time Video Super-Resolution
Jul 24, 2024



In many applications, including surveillance, entertainment, and restoration, there is a need to increase both the spatial resolution and the frame rate of a video sequence. The aim is to improve visual quality, refine details, and create a more realistic viewing experience. Existing space-time video super-resolution methods do not effectively use spatio-temporal information. To address this limitation, we propose a generative adversarial network for joint space-time video super-resolution. The generative network consists of three operations: shallow feature extraction, deep feature extraction, and reconstruction. It uses three-dimensional (3D) convolutions to process temporal and spatial information simultaneously and includes a novel 3D attention mechanism to extract the most important channel and spatial information. The discriminative network uses a two-branch structure to handle details and motion information, making the generated results more accurate. Experimental results on the Vid4, Vimeo-90K, and REDS datasets demonstrate the effectiveness of the proposed method. The source code is publicly available at https://github.com/FCongRui/3DAttGan.git.
Cuboid-Net: A Multi-Branch Convolutional Neural Network for Joint Space-Time Video Super Resolution
Jul 24, 2024
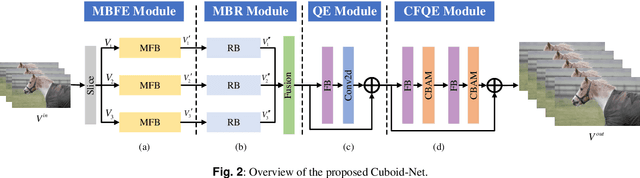
The demand for high-resolution videos has been consistently rising across various domains, propelled by continuous advancements in science, technology, and societal. Nonetheless, challenges arising from limitations in imaging equipment capabilities, imaging conditions, as well as economic and temporal factors often result in obtaining low-resolution images in particular situations. Space-time video super-resolution aims to enhance the spatial and temporal resolutions of low-resolution and low-frame-rate videos. The currently available space-time video super-resolution methods often fail to fully exploit the abundant information existing within the spatio-temporal domain. To address this problem, we tackle the issue by conceptualizing the input low-resolution video as a cuboid structure. Drawing on this perspective, we introduce an innovative methodology called "Cuboid-Net," which incorporates a multi-branch convolutional neural network. Cuboid-Net is designed to collectively enhance the spatial and temporal resolutions of videos, enabling the extraction of rich and meaningful information across both spatial and temporal dimensions. Specifically, we take the input video as a cuboid to generate different directional slices as input for different branches of the network. The proposed network contains four modules, i.e., a multi-branch-based hybrid feature extraction (MBFE) module, a multi-branch-based reconstruction (MBR) module, a first stage quality enhancement (QE) module, and a second stage cross frame quality enhancement (CFQE) module for interpolated frames only. Experimental results demonstrate that the proposed method is not only effective for spatial and temporal super-resolution of video but also for spatial and angular super-resolution of light field.
Global Spatial-Temporal Information-based Residual ConvLSTM for Video Space-Time Super-Resolution
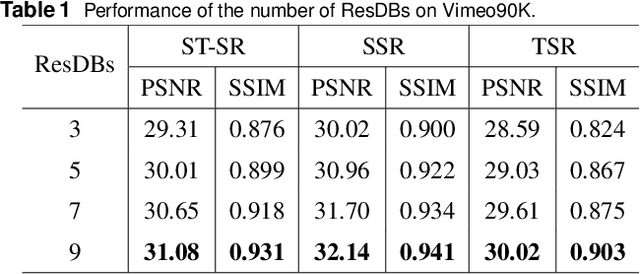
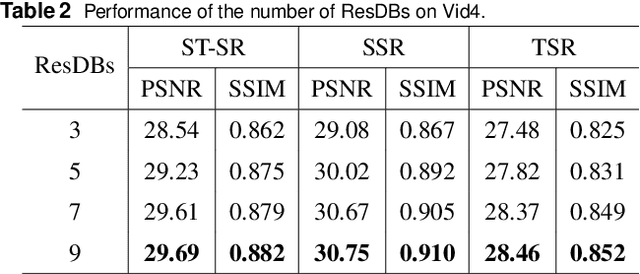
Jul 11, 2024By converting low-frame-rate, low-resolution videos into high-frame-rate, high-resolution ones, space-time video super-resolution techniques can enhance visual experiences and facilitate more efficient information dissemination. We propose a convolutional neural network (CNN) for space-time video super-resolution, namely GIRNet. To generate highly accurate features and thus improve performance, the proposed network integrates a feature-level temporal interpolation module with deformable convolutions and a global spatial-temporal information-based residual convolutional long short-term memory (convLSTM) module. In the feature-level temporal interpolation module, we leverage deformable convolution, which adapts to deformations and scale variations of objects across different scene locations. This presents a more efficient solution than conventional convolution for extracting features from moving objects. Our network effectively uses forward and backward feature information to determine inter-frame offsets, leading to the direct generation of interpolated frame features. In the global spatial-temporal information-based residual convLSTM module, the first convLSTM is used to derive global spatial-temporal information from the input features, and the second convLSTM uses the previously computed global spatial-temporal information feature as its initial cell state. This second convLSTM adopts residual connections to preserve spatial information, thereby enhancing the output features. Experiments on the Vimeo90K dataset show that the proposed method outperforms state-of-the-art techniques in peak signal-to-noise-ratio (by 1.45 dB, 1.14 dB, and 0.02 dB over STARnet, TMNet, and 3DAttGAN, respectively), structural similarity index(by 0.027, 0.023, and 0.006 over STARnet, TMNet, and 3DAttGAN, respectively), and visually.
Towards Real-World HDR Video Reconstruction: A Large-Scale Benchmark Dataset and A Two-Stage Alignment Network
Apr 30, 2024
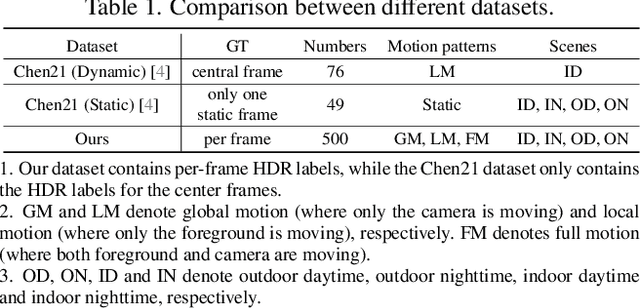
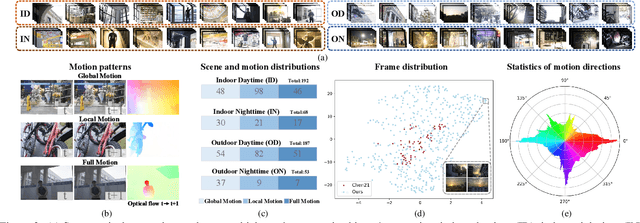

As an important and practical way to obtain high dynamic range (HDR) video, HDR video reconstruction from sequences with alternating exposures is still less explored, mainly due to the lack of large-scale real-world datasets. Existing methods are mostly trained on synthetic datasets, which perform poorly in real scenes. In this work, to facilitate the development of real-world HDR video reconstruction, we present Real-HDRV, a large-scale real-world benchmark dataset for HDR video reconstruction, featuring various scenes, diverse motion patterns, and high-quality labels. Specifically, our dataset contains 500 LDRs-HDRs video pairs, comprising about 28,000 LDR frames and 4,000 HDR labels, covering daytime, nighttime, indoor, and outdoor scenes. To our best knowledge, our dataset is the largest real-world HDR video reconstruction dataset. Correspondingly, we propose an end-to-end network for HDR video reconstruction, where a novel two-stage strategy is designed to perform alignment sequentially. Specifically, the first stage performs global alignment with the adaptively estimated global offsets, reducing the difficulty of subsequent alignment. The second stage implicitly performs local alignment in a coarse-to-fine manner at the feature level using the adaptive separable convolution. Extensive experiments demonstrate that: (1) models trained on our dataset can achieve better performance on real scenes than those trained on synthetic datasets; (2) our method outperforms previous state-of-the-art methods. Our dataset is available at https://github.com/yungsyu99/Real-HDRV.
RFD-ECNet: Extreme Underwater Image Compression with Reference to Feature Dictionar
Aug 17, 2023Thriving underwater applications demand efficient extreme compression technology to realize the transmission of underwater images (UWIs) in very narrow underwater bandwidth. However, existing image compression methods achieve inferior performance on UWIs because they do not consider the characteristics of UWIs: (1) Multifarious underwater styles of color shift and distance-dependent clarity, caused by the unique underwater physical imaging; (2) Massive redundancy between different UWIs, caused by the fact that different UWIs contain several common ocean objects, which have plenty of similarities in structures and semantics. To remove redundancy among UWIs, we first construct an exhaustive underwater multi-scale feature dictionary to provide coarse-to-fine reference features for UWI compression. Subsequently, an extreme UWI compression network with reference to the feature dictionary (RFD-ECNet) is creatively proposed, which utilizes feature match and reference feature variant to significantly remove redundancy among UWIs. To align the multifarious underwater styles and improve the accuracy of feature match, an underwater style normalized block (USNB) is proposed, which utilizes underwater physical priors extracted from the underwater physical imaging model to normalize the underwater styles of dictionary features toward the input. Moreover, a reference feature variant module (RFVM) is designed to adaptively morph the reference features, improving the similarity between the reference and input features. Experimental results on four UWI datasets show that our RFD-ECNet is the first work that achieves a significant BD-rate saving of 31% over the most advanced VVC.
UIERL: Internal-External Representation Learning Network for Underwater Image Enhancement
Jun 14, 2023



Underwater image enhancement (UIE) is a meaningful but challenging task, and many learning-based UIE methods have been proposed in recent years. Although much progress has been made, these methods still exist two issues: (1) There exists a significant region-wise quality difference in a single underwater image due to the underwater imaging process, especially in regions with different scene depths. However, existing methods neglect this internal characteristic of underwater images, resulting in inferior performance; (2) Due to the uniqueness of the acquisition approach, underwater image acquisition tools usually capture multiple images in the same or similar scenes. Thus, the underwater images to be enhanced in practical usage are highly correlated. However, when processing a single image, existing methods do not consider the rich external information provided by the related images. There is still room for improvement in their performance. Motivated by these two aspects, we propose a novel internal-external representation learning (UIERL) network to better perform UIE tasks with internal and external information, simultaneously. In the internal representation learning stage, a new depth-based region feature guidance network is designed, including a region segmentation based on scene depth to sense regions with different quality levels, followed by a region-wise space encoder module. With performing region-wise feature learning for regions with different quality separately, the network provides an effective guidance for global features and thus guides intra-image differentiated enhancement. In the external representation learning stage, we first propose an external information extraction network to mine the rich external information in the related images. Then, internal and external features interact with each other via the proposed external-assist-internal module and internal-assist-e
Multi-Modality Deep Network for JPEG Artifacts Reduction
May 04, 2023



In recent years, many convolutional neural network-based models are designed for JPEG artifacts reduction, and have achieved notable progress. However, few methods are suitable for extreme low-bitrate image compression artifacts reduction. The main challenge is that the highly compressed image loses too much information, resulting in reconstructing high-quality image difficultly. To address this issue, we propose a multimodal fusion learning method for text-guided JPEG artifacts reduction, in which the corresponding text description not only provides the potential prior information of the highly compressed image, but also serves as supplementary information to assist in image deblocking. We fuse image features and text semantic features from the global and local perspectives respectively, and design a contrastive loss built upon contrastive learning to produce visually pleasing results. Extensive experiments, including a user study, prove that our method can obtain better deblocking results compared to the state-of-the-art methods.
Multi-Modality Deep Network for Extreme Learned Image Compression
Apr 26, 2023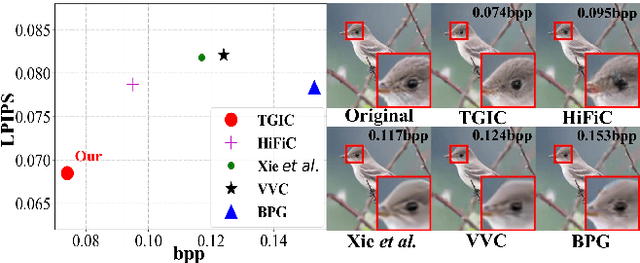

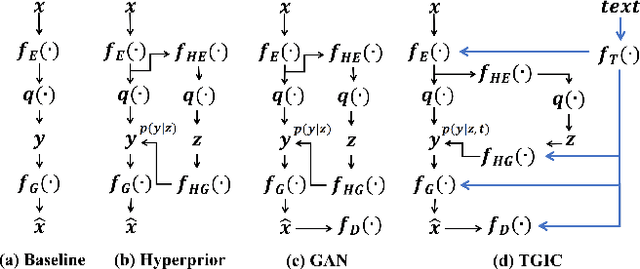

Image-based single-modality compression learning approaches have demonstrated exceptionally powerful encoding and decoding capabilities in the past few years , but suffer from blur and severe semantics loss at extremely low bitrates. To address this issue, we propose a multimodal machine learning method for text-guided image compression, in which the semantic information of text is used as prior information to guide image compression for better compression performance. We fully study the role of text description in different components of the codec, and demonstrate its effectiveness. In addition, we adopt the image-text attention module and image-request complement module to better fuse image and text features, and propose an improved multimodal semantic-consistent loss to produce semantically complete reconstructions. Extensive experiments, including a user study, prove that our method can obtain visually pleasing results at extremely low bitrates, and achieves a comparable or even better performance than state-of-the-art methods, even though these methods are at 2x to 4x bitrates of ours.
Domain Adaptation for Underwater Image Enhancement
Aug 22, 2021



Recently, learning-based algorithms have shown impressive performance in underwater image enhancement. Most of them resort to training on synthetic data and achieve outstanding performance. However, these methods ignore the significant domain gap between the synthetic and real data (i.e., interdomain gap), and thus the models trained on synthetic data often fail to generalize well to real underwater scenarios. Furthermore, the complex and changeable underwater environment also causes a great distribution gap among the real data itself (i.e., intra-domain gap). However, almost no research focuses on this problem and thus their techniques often produce visually unpleasing artifacts and color distortions on various real images. Motivated by these observations, we propose a novel Two-phase Underwater Domain Adaptation network (TUDA) to simultaneously minimize the inter-domain and intra-domain gap. Concretely, a new dual-alignment network is designed in the first phase, including a translation part for enhancing realism of input images, followed by an enhancement part. With performing image-level and feature-level adaptation in two parts by jointly adversarial learning, the network can better build invariance across domains and thus bridge the inter-domain gap. In the second phase, we perform an easy-hard classification of real data according to the assessed quality of enhanced images, where a rank-based underwater quality assessment method is embedded. By leveraging implicit quality information learned from rankings, this method can more accurately assess the perceptual quality of enhanced images. Using pseudo labels from the easy part, an easy-hard adaptation technique is then conducted to effectively decrease the intra-domain gap between easy and hard samples.