 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Testing Neural Network Verifiers: A Soundness Benchmark with Hidden Counterexamples
Dec 04, 2024



In recent years, many neural network (NN) verifiers have been developed to formally verify certain properties of neural networks such as robustness. Although many benchmarks have been constructed to evaluate the performance of NN verifiers, they typically lack a ground-truth for hard instances where no current verifier can verify and no counterexample can be found, which makes it difficult to check the soundness of a new verifier if it claims to verify hard instances which no other verifier can do. We propose to develop a soundness benchmark for NN verification. Our benchmark contains instances with deliberately inserted counterexamples while we also try to hide the counterexamples from regular adversarial attacks which can be used for finding counterexamples. We design a training method to produce neural networks with such hidden counterexamples. Our benchmark aims to be used for testing the soundness of NN verifiers and identifying falsely claimed verifiability when it is known that hidden counterexamples exist. We systematically construct our benchmark and generate instances across diverse model architectures, activation functions, input sizes, and perturbation radii. We demonstrate that our benchmark successfully identifies bugs in state-of-the-art NN verifiers, as well as synthetic bugs, providing a crucial step toward enhancing the reliability of testing NN verifiers. Our code is available at https://github.com/MVP-Harry/SoundnessBench and our benchmark is available at https://huggingface.co/datasets/SoundnessBench/SoundnessBench.
Cuboid-Net: A Multi-Branch Convolutional Neural Network for Joint Space-Time Video Super Resolution
Jul 24, 2024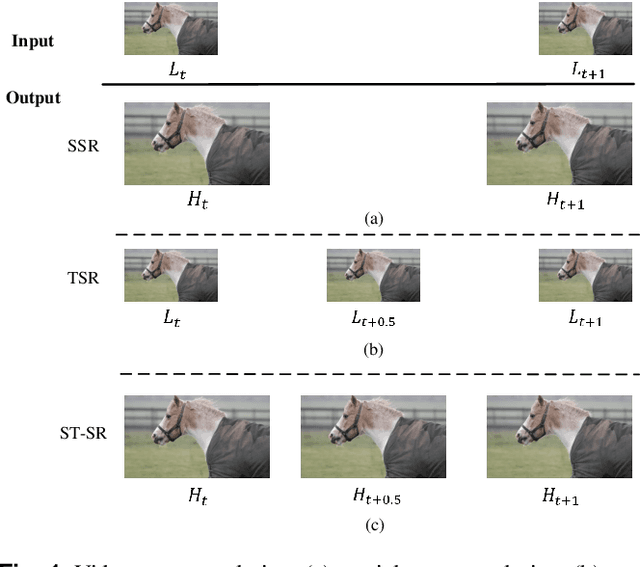
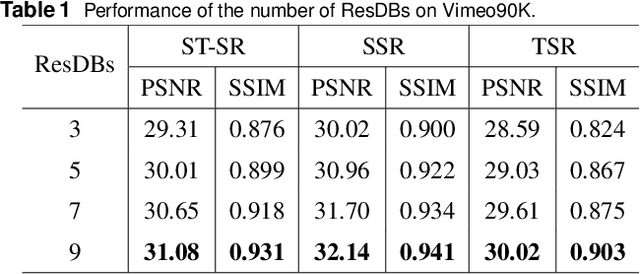
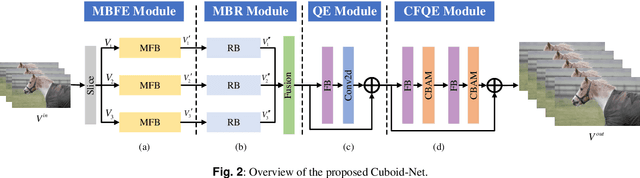
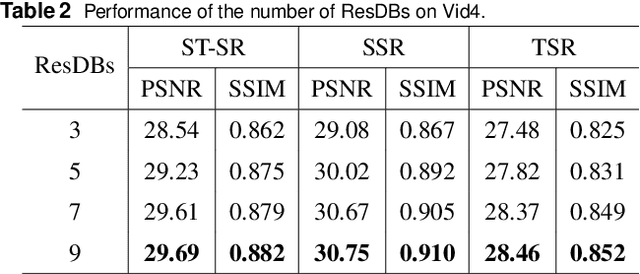
The demand for high-resolution videos has been consistently rising across various domains, propelled by continuous advancements in science, technology, and societal. Nonetheless, challenges arising from limitations in imaging equipment capabilities, imaging conditions, as well as economic and temporal factors often result in obtaining low-resolution images in particular situations. Space-time video super-resolution aims to enhance the spatial and temporal resolutions of low-resolution and low-frame-rate videos. The currently available space-time video super-resolution methods often fail to fully exploit the abundant information existing within the spatio-temporal domain. To address this problem, we tackle the issue by conceptualizing the input low-resolution video as a cuboid structure. Drawing on this perspective, we introduce an innovative methodology called "Cuboid-Net," which incorporates a multi-branch convolutional neural network. Cuboid-Net is designed to collectively enhance the spatial and temporal resolutions of videos, enabling the extraction of rich and meaningful information across both spatial and temporal dimensions. Specifically, we take the input video as a cuboid to generate different directional slices as input for different branches of the network. The proposed network contains four modules, i.e., a multi-branch-based hybrid feature extraction (MBFE) module, a multi-branch-based reconstruction (MBR) module, a first stage quality enhancement (QE) module, and a second stage cross frame quality enhancement (CFQE) module for interpolated frames only. Experimental results demonstrate that the proposed method is not only effective for spatial and temporal super-resolution of video but also for spatial and angular super-resolution of light field.