 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DAttGAN: A 3D Attention-based Generative Adversarial Network for Joint Space-Time Video Super-Resolution
Jul 24, 2024



In many applications, including surveillance, entertainment, and restoration, there is a need to increase both the spatial resolution and the frame rate of a video sequence. The aim is to improve visual quality, refine details, and create a more realistic viewing experience. Existing space-time video super-resolution methods do not effectively use spatio-temporal information. To address this limitation, we propose a generative adversarial network for joint space-time video super-resolution. The generative network consists of three operations: shallow feature extraction, deep feature extraction, and reconstruction. It uses three-dimensional (3D) convolutions to process temporal and spatial information simultaneously and includes a novel 3D attention mechanism to extract the most important channel and spatial information. The discriminative network uses a two-branch structure to handle details and motion information, making the generated results more accurate. Experimental results on the Vid4, Vimeo-90K, and REDS datasets demonstrate the effectiveness of the proposed method. The source code is publicly available at https://github.com/FCongRui/3DAttGan.git.
Cuboid-Net: A Multi-Branch Convolutional Neural Network for Joint Space-Time Video Super Resolution
Jul 24, 2024
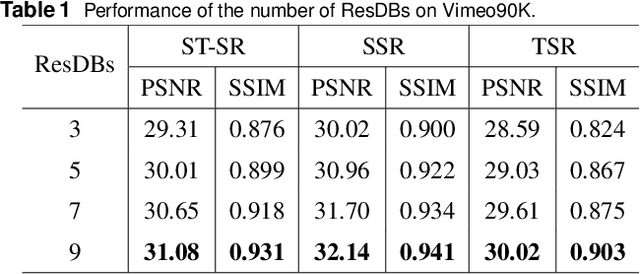
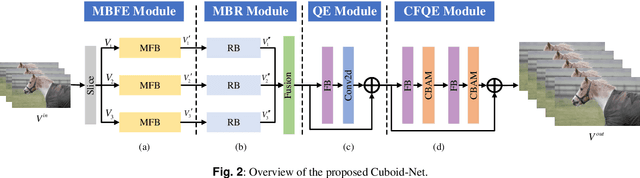
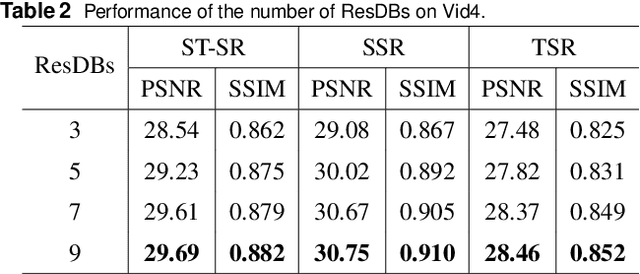
The demand for high-resolution videos has been consistently rising across various domains, propelled by continuous advancements in science, technology, and societal. Nonetheless, challenges arising from limitations in imaging equipment capabilities, imaging conditions, as well as economic and temporal factors often result in obtaining low-resolution images in particular situations. Space-time video super-resolution aims to enhance the spatial and temporal resolutions of low-resolution and low-frame-rate videos. The currently available space-time video super-resolution methods often fail to fully exploit the abundant information existing within the spatio-temporal domain. To address this problem, we tackle the issue by conceptualizing the input low-resolution video as a cuboid structure. Drawing on this perspective, we introduce an innovative methodology called "Cuboid-Net," which incorporates a multi-branch convolutional neural network. Cuboid-Net is designed to collectively enhance the spatial and temporal resolutions of videos, enabling the extraction of rich and meaningful information across both spatial and temporal dimensions. Specifically, we take the input video as a cuboid to generate different directional slices as input for different branches of the network. The proposed network contains four modules, i.e., a multi-branch-based hybrid feature extraction (MBFE) module, a multi-branch-based reconstruction (MBR) module, a first stage quality enhancement (QE) module, and a second stage cross frame quality enhancement (CFQE) module for interpolated frames only. Experimental results demonstrate that the proposed method is not only effective for spatial and temporal super-resolution of video but also for spatial and angular super-resolution of light field.
OMR-NET: a two-stage octave multi-scale residual network for screen content image compression
Jul 11, 2024



Screen content (SC) differs from natural scene (NS) with unique characteristics such as noise-free, repetitive patterns, and high contrast. Aiming at addressing the inadequacies of current learned image compression (LIC) methods for SC, we propose an improved two-stage octave convolutional residual blocks (IToRB) for high and low-frequency feature extraction and a cascaded two-stage multi-scale residual blocks (CTMSRB) for improved multi-scale learning and nonlinearity in SC. Additionally, we employ a window-based attention module (WAM) to capture pixel correlations, especially for high contrast regions in the image. We also construct a diverse SC image compression dataset (SDU-SCICD2K) for training, including text, charts, graphics, animation, movie, game and mixture of SC images and NS images. Experimental results show our method, more suited for SC than NS data, outperforms existing LIC methods in rate-distortion performance on SC images. The code is publicly available at https://github.com/SunshineSki/OMR Net.git.
* 7 figures, 2 tables
Global Spatial-Temporal Information-based Residual ConvLSTM for Video Space-Time Super-Resolution
Jul 11, 2024By converting low-frame-rate, low-resolution videos into high-frame-rate, high-resolution ones, space-time video super-resolution techniques can enhance visual experiences and facilitate more efficient information dissemination. We propose a convolutional neural network (CNN) for space-time video super-resolution, namely GIRNet. To generate highly accurate features and thus improve performance, the proposed network integrates a feature-level temporal interpolation module with deformable convolutions and a global spatial-temporal information-based residual convolutional long short-term memory (convLSTM) module. In the feature-level temporal interpolation module, we leverage deformable convolution, which adapts to deformations and scale variations of objects across different scene locations. This presents a more efficient solution than conventional convolution for extracting features from moving objects. Our network effectively uses forward and backward feature information to determine inter-frame offsets, leading to the direct generation of interpolated frame features. In the global spatial-temporal information-based residual convLSTM module, the first convLSTM is used to derive global spatial-temporal information from the input features, and the second convLSTM uses the previously computed global spatial-temporal information feature as its initial cell state. This second convLSTM adopts residual connections to preserve spatial information, thereby enhancing the output features. Experiments on the Vimeo90K dataset show that the proposed method outperforms state-of-the-art techniques in peak signal-to-noise-ratio (by 1.45 dB, 1.14 dB, and 0.02 dB over STARnet, TMNet, and 3DAttGAN, respectively), structural similarity index(by 0.027, 0.023, and 0.006 over STARnet, TMNet, and 3DAttGAN, respectively), and visually.