 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAFT: Sensitivity-Aware Filtering and Transmission for Adaptive 3D Point Cloud Communication over Wireless Channels
Mar 27, 2026Reliable transmission of 3D point clouds over wireless channels is challenging due to time-varying signal-to-noise ratio (SNR) and limited bandwidth. This paper introduces sensitivity-aware filtering and transmission (SAFT), a learned transmission framework that integrates a Point-BERT-inspired encoder, a sensitivity-guided token filtering (STF) unit, a quantization block, and an SNR-aware decoder for adaptive reconstruction. Specifically, the STF module assigns token-wise importance scores based on the reconstruction sensitivity of each token under channel perturbation. We further employ a training-only symbol-usage penalty to stabilize the discrete representation, without affecting the transmitted payload. Experiments on ShapeNet, ModelNet40, and 8iVFB show that SAFT improves geometric fidelity (D1/D2 PSNR) compared with a separate source--channel coding pipeline (G-PCC combined with LDPC and QAM) and existing learned baselines, with the largest gains observed in low-SNR regimes, highlighting improved robustness under limited bandwidth.
DistrAttention: An Efficient and Flexible Self-Attention Mechanism on Modern GPUs
Jul 23, 2025The Transformer architecture has revolutionized deep learning, delivering the state-of-the-art performance in areas such as natural language processing, computer vision, and time series prediction. However, its core component, self-attention, has the quadratic time complexity relative to input sequence length, which hinders the scalability of Transformers. The exsiting approaches on optimizing self-attention either discard full-contextual information or lack of flexibility. In this work, we design DistrAttention, an effcient and flexible self-attention mechanism with the full context. DistrAttention achieves this by grouping data on the embedding dimensionality, usually referred to as $d$. We realize DistrAttention with a lightweight sampling and fusion method that exploits locality-sensitive hashing to group similar data. A block-wise grouping framework is further designed to limit the errors introduced by locality sensitive hashing. By optimizing the selection of block sizes, DistrAttention could be easily integrated with FlashAttention-2, gaining high-performance on modern GPUs. We evaluate DistrAttention with extensive experiments. The results show that our method is 37% faster than FlashAttention-2 on calculating self-attention. In ViT inference, DistrAttention is the fastest and the most accurate among approximate self-attention mechanisms. In Llama3-1B, DistrAttention still achieves the lowest inference time with only 1% accuray loss.
PipeDec: Low-Latency Pipeline-based Inference with Dynamic Speculative Decoding towards Large-scale Models
Apr 05, 2025Autoregressive large language model inference primarily consists of two stages: pre-filling and decoding. Decoding involves sequential computation for each token, which leads to significant latency. Speculative decoding is a technique that leverages the draft model combined with large model verification to enhance parallelism without sacrificing accuracy. However, existing external prediction methods face challenges in adapting to multi-node serial deployments. While they can maintain speedup under such conditions, the high latency of multi-node deployments ultimately results in low overall efficiency. We propose a speculative decoding framework named PipeDec to address the low global resource utilization of single tasks in pipeline deployments thereby reducing decoding latency. We integrate a draft model into the pipeline of the large model and immediately forward each prediction from the draft model to subsequent pipeline stages. A dynamic prediction tree manages prediction sequences across nodes, enabling efficient updating and pruning. This approach leverages the draft model's predictions to utilize all pipeline nodes for parallel decoding of a single task. Experiments were conducted using LLama3.2 1B as the draft model in conjunction with a 14-stage parallel pipeline to accelerate LLama3.1 70B by six different types of datasets. During the decoding phase of a single task, PipeDec achieved a 4.46x-7.79x speedup compared to traditional pipeline parallelism and a 2.2x-2.69x speedup compared to baseline tree-based speculative decoding methods. The code will be released after the review process.
Global Spatial-Temporal Information-based Residual ConvLSTM for Video Space-Time Super-Resolution
Jul 11, 2024By converting low-frame-rate, low-resolution videos into high-frame-rate, high-resolution ones, space-time video super-resolution techniques can enhance visual experiences and facilitate more efficient information dissemination. We propose a convolutional neural network (CNN) for space-time video super-resolution, namely GIRNet. To generate highly accurate features and thus improve performance, the proposed network integrates a feature-level temporal interpolation module with deformable convolutions and a global spatial-temporal information-based residual convolutional long short-term memory (convLSTM) module. In the feature-level temporal interpolation module, we leverage deformable convolution, which adapts to deformations and scale variations of objects across different scene locations. This presents a more efficient solution than conventional convolution for extracting features from moving objects. Our network effectively uses forward and backward feature information to determine inter-frame offsets, leading to the direct generation of interpolated frame features. In the global spatial-temporal information-based residual convLSTM module, the first convLSTM is used to derive global spatial-temporal information from the input features, and the second convLSTM uses the previously computed global spatial-temporal information feature as its initial cell state. This second convLSTM adopts residual connections to preserve spatial information, thereby enhancing the output features. Experiments on the Vimeo90K dataset show that the proposed method outperforms state-of-the-art techniques in peak signal-to-noise-ratio (by 1.45 dB, 1.14 dB, and 0.02 dB over STARnet, TMNet, and 3DAttGAN, respectively), structural similarity index(by 0.027, 0.023, and 0.006 over STARnet, TMNet, and 3DAttGAN, respectively), and visually.
Unsupervised Monocular Depth Estimation Based on Hierarchical Feature-Guided Diffusion
Jun 14, 2024



Unsupervised monocular depth estimation has received widespread attention because of its capability to train without ground truth. In real-world scenarios, the images may be blurry or noisy due to the influence of weather conditions and inherent limitations of the camera. Therefore, it is particularly important to develop a robust depth estimation model. Benefiting from the training strategies of generative networks, generative-based methods often exhibit enhanced robustness. In light of this, we employ a well-converging diffusion model among generative networks for unsupervised monocular depth estimation. Additionally, we propose a hierarchical feature-guided denoising module. This model significantly enriches the model's capacity for learning and interpreting depth distribution by fully leveraging image features to guide the denoising process. Furthermore, we explore the implicit depth within reprojection and design an implicit depth consistency loss. This loss function serves to enhance the performance of the model and ensure the scale consistency of depth within a video sequence. We conduct experiments on the KITTI, Make3D, and our self-collected SIMIT datasets. The results indicate that our approach stands out among generative-based models, while also showcasing remarkable robustness.
Scribble-Supervised RGB-T Salient Object Detection
Mar 17, 2023
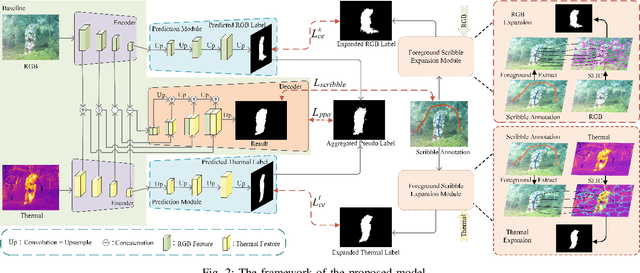


Salient object detection segments attractive objects in scenes. RGB and thermal modalities provide complementary information and scribble annotations alleviate large amounts of human labor. Based on the above facts, we propose a scribble-supervised RGB-T salient object detection model. By a four-step solution (expansion, prediction, aggregation, and supervision), label-sparse challenge of scribble-supervised method is solved. To expand scribble annotations, we collect the superpixels that foreground scribbles pass through in RGB and thermal images, respectively. The expanded multi-modal labels provide the coarse object boundary. To further polish the expanded labels, we propose a prediction module to alleviate the sharpness of boundary. To play the complementary roles of two modalities, we combine the two into aggregated pseudo labels. Supervised by scribble annotations and pseudo labels, our model achieves the state-of-the-art performance on the relabeled RGBT-S dataset. Furthermore, the model is applied to RGB-D and video scribble-supervised applications, achieving consistently excellent performance.
RGB-T Multi-Modal Crowd Counting Based on Transformer
Jan 08, 2023Crowd counting aims to estimate the number of persons in a scene. Most state-of-the-art crowd counting methods based on color images can't work well in poor illumination conditions due to invisible objects. With the widespread use of infrared cameras, crowd counting based on color and thermal images is studied. Existing methods only achieve multi-modal fusion without count objective constraint. To better excavate multi-modal information, we use count-guided multi-modal fusion and modal-guided count enhancement to achieve the impressive performance. The proposed count-guided multi-modal fusion module utilizes a multi-scale token transformer to interact two-modal information under the guidance of count information and perceive different scales from the token perspective. The proposed modal-guided count enhancement module employs multi-scale deformable transformer decoder structure to enhance one modality feature and count information by the other modality. Experiment in public RGBT-CC dataset shows that our method refreshes the state-of-the-art results. https://github.com/liuzywen/RGBTCC