 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHRTransNet: HRFormer-Driven Two-Modality Salient Object Detection
Jan 08, 2023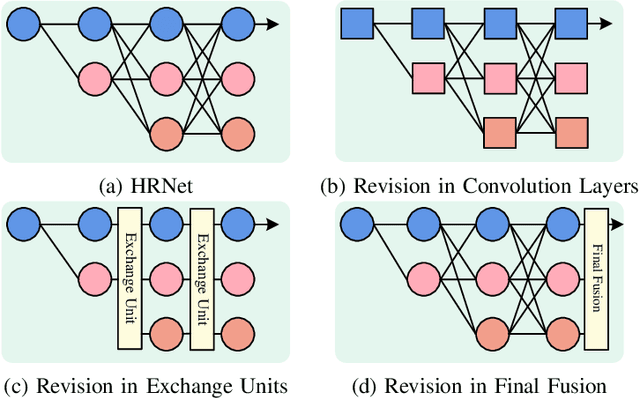
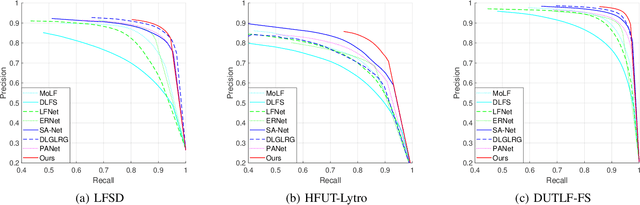

The High-Resolution Transformer (HRFormer) can maintain high-resolution representation and share global receptive fields. It is friendly towards salient object detection (SOD) in which the input and output have the same resolution. However, two critical problems need to be solved for two-modality SOD. One problem is two-modality fusion. The other problem is the HRFormer output's fusion. To address the first problem, a supplementary modality is injected into the primary modality by using global optimization and an attention mechanism to select and purify the modality at the input level. To solve the second problem, a dual-direction short connection fusion module is used to optimize the output features of HRFormer, thereby enhancing the detailed representation of objects at the output level. The proposed model, named HRTransNet, first introduces an auxiliary stream for feature extraction of supplementary modality. Then, features are injected into the primary modality at the beginning of each multi-resolution branch. Next, HRFormer is applied to achieve forwarding propagation. Finally, all the output features with different resolutions are aggregated by intra-feature and inter-feature interactive transformers. Application of the proposed model results in impressive improvement for driving two-modality SOD tasks, e.g., RGB-D, RGB-T, and light field SOD.https://github.com/liuzywen/HRTransNet
RGB-T Multi-Modal Crowd Counting Based on Transformer
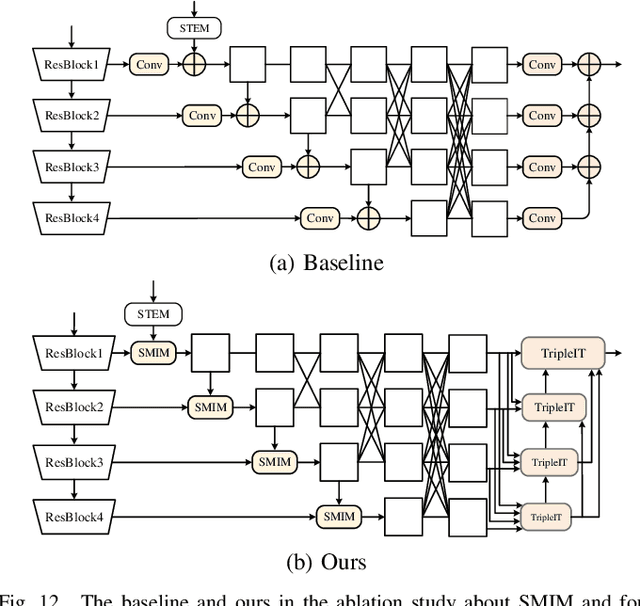
Jan 08, 2023Crowd counting aims to estimate the number of persons in a scene. Most state-of-the-art crowd counting methods based on color images can't work well in poor illumination conditions due to invisible objects. With the widespread use of infrared cameras, crowd counting based on color and thermal images is studied. Existing methods only achieve multi-modal fusion without count objective constraint. To better excavate multi-modal information, we use count-guided multi-modal fusion and modal-guided count enhancement to achieve the impressive performance. The proposed count-guided multi-modal fusion module utilizes a multi-scale token transformer to interact two-modal information under the guidance of count information and perceive different scales from the token perspective. The proposed modal-guided count enhancement module employs multi-scale deformable transformer decoder structure to enhance one modality feature and count information by the other modality. Experiment in public RGBT-CC dataset shows that our method refreshes the state-of-the-art results. https://github.com/liuzywen/RGBTCC
SwinNet: Swin Transformer drives edge-aware RGB-D and RGB-T salient object detection
Apr 12, 2022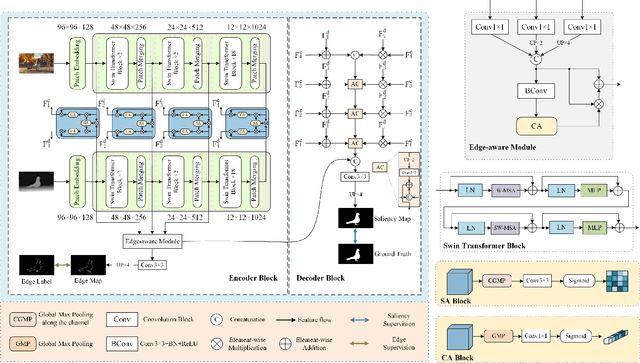
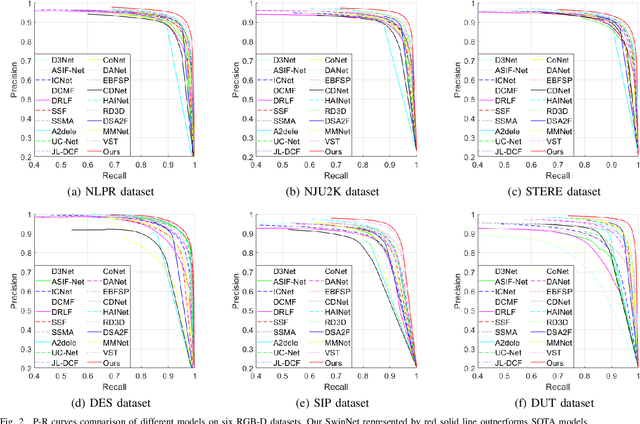
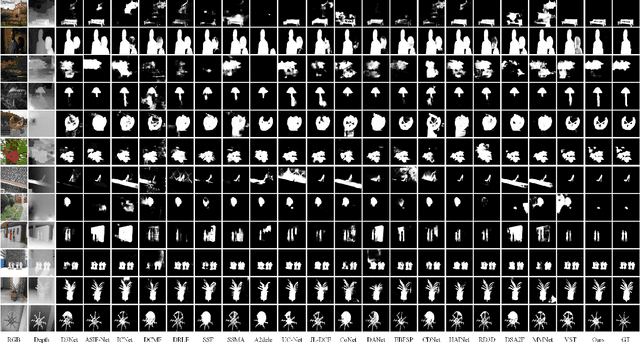
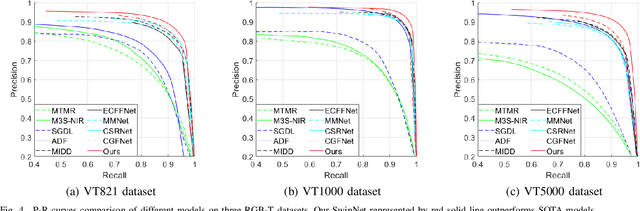
Convolutional neural networks (CNNs) are good at extracting contexture features within certain receptive fields, while transformers can model the global long-range dependency features. By absorbing the advantage of transformer and the merit of CNN, Swin Transformer shows strong feature representation ability. Based on it, we propose a cross-modality fusion model SwinNet for RGB-D and RGB-T salient object detection. It is driven by Swin Transformer to extract the hierarchical features, boosted by attention mechanism to bridge the gap between two modalities, and guided by edge information to sharp the contour of salient object. To be specific, two-stream Swin Transformer encoder first extracts multi-modality features, and then spatial alignment and channel re-calibration module is presented to optimize intra-level cross-modality features. To clarify the fuzzy boundary, edge-guided decoder achieves inter-level cross-modality fusion under the guidance of edge features. The proposed model outperforms the state-of-the-art models on RGB-D and RGB-T datasets, showing that it provides more insight into the cross-modality complementarity task.
* Online published in TCSVT