 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangle-then-Align: Non-Iterative Hybrid Multimodal Image Registration via Cross-Scale Feature Disentanglement
Mar 20, 2026Multimodal image registration is a fundamental task and a prerequisite for downstream cross-modal analysis. Despite recent progress in shared feature extraction and multi-scale architectures, two key limitations remain. First, some methods use disentanglement to learn shared features but mainly regularize the shared part, allowing modality-private cues to leak into the shared space. Second, most multi-scale frameworks support only a single transformation type, limiting their applicability when global misalignment and local deformation coexist. To address these issues, we formulate hybrid multimodal registration as jointly learning a stable shared feature space and a unified hybrid transformation. Based on this view, we propose HRNet, a Hybrid Registration Network that couples representation disentanglement with hybrid parameter prediction. A shared backbone with Modality-Specific Batch Normalization (MSBN) extracts multi-scale features, while a Cross-scale Disentanglement and Adaptive Projection (CDAP) module suppresses modality-private cues and projects shared features into a stable subspace for matching. Built on this shared space, a Hybrid Parameter Prediction Module (HPPM) performs non-iterative coarse-to-fine estimation of global rigid parameters and deformation fields, which are fused into a coherent deformation field. Extensive experiments on four multimodal datasets demonstrate state-of-the-art performance on rigid and non-rigid registration tasks. The code is available at the project website.
Dynamic Disentangled Fusion Network for RGBT Tracking
Dec 11, 2024



RGBT tracking usually suffers from various challenging factors of low resolution, similar appearance, extreme illumination, thermal crossover and occlusion, to name a few. Existing works often study complex fusion models to handle challenging scenarios, but can not well adapt to various challenges, which might limit tracking performance. To handle this problem, we propose a novel Dynamic Disentangled Fusion Network called DDFNet, which disentangles the fusion process into several dynamic fusion models via the challenge attributes to adapt to various challenging scenarios, for robust RGBT tracking. In particular, we design six attribute-based fusion models to integrate RGB and thermal features under the six challenging scenarios respectively.Since each fusion model is to deal with the corresponding challenges, such disentangled fusion scheme could increase the fusion capacity without the dependence on large-scale training data. Considering that every challenging scenario also has different levels of difficulty, we propose to optimize the combination of multiple fusion units to form each attribute-based fusion model in a dynamic manner, which could well adapt to the difficulty of the corresponding challenging scenario. To address the issue that which fusion models should be activated in the tracking process, we design an adaptive aggregation fusion module to integrate all features from attribute-based fusion models in an adaptive manner with a three-stage training algorithm. In addition, we design an enhancement fusion module to further strengthen the aggregated feature and modality-specific features. Experimental results on benchmark datasets demonstrate the effectiveness of our DDFNet against other state-of-the-art methods.
ContextDet: Temporal Action Detection with Adaptive Context Aggregation
Oct 20, 2024



Temporal action detection (TAD), which locates and recognizes action segments, remains a challenging task in video understanding due to variable segment lengths and ambiguous boundaries. Existing methods treat neighboring contexts of an action segment indiscriminately, leading to imprecise boundary predictions. We introduce a single-stage ContextDet framework, which makes use of large-kernel convolutions in TAD for the first time. Our model features a pyramid adaptive context aggragation (ACA) architecture, capturing long context and improving action discriminability. Each ACA level consists of two novel modules. The context attention module (CAM) identifies salient contextual information, encourages context diversity, and preserves context integrity through a context gating block (CGB). The long context module (LCM) makes use of a mixture of large- and small-kernel convolutions to adaptively gather long-range context and fine-grained local features. Additionally, by varying the length of these large kernels across the ACA pyramid, our model provides lightweight yet effective context aggregation and action discrimination. We conducted extensive experiments and compared our model with a number of advanced TAD methods on six challenging TAD benchmarks: MultiThumos, Charades, FineAction, EPIC-Kitchens 100, Thumos14, and HACS, demonstrating superior accuracy at reduced inference speed.
Breaking Modality Gap in RGBT Tracking: Coupled Knowledge Distillation
Oct 15, 2024



Modality gap between RGB and thermal infrared (TIR) images is a crucial issue but often overlooked in existing RGBT tracking methods. It can be observed that modality gap mainly lies in the image style difference. In this work, we propose a novel Coupled Knowledge Distillation framework called CKD, which pursues common styles of different modalities to break modality gap, for high performance RGBT tracking. In particular, we introduce two student networks and employ the style distillation loss to make their style features consistent as much as possible. Through alleviating the style difference of two student networks, we can break modality gap of different modalities well. However, the distillation of style features might harm to the content representations of two modalities in student networks. To handle this issue, we take original RGB and TIR networks as the teachers, and distill their content knowledge into two student networks respectively by the style-content orthogonal feature decoupling scheme. We couple the above two distillation processes in an online optimization framework to form new feature representations of RGB and thermal modalities without modality gap. In addition, we design a masked modeling strategy and a multi-modal candidate token elimination strategy into CKD to improve tracking robustness and efficiency respectively. Extensive experiments on five standard RGBT tracking datasets validate the effectiveness of the proposed method against state-of-the-art methods while achieving the fastest tracking speed of 96.4 FPS. Code available at https://github.com/Multi-Modality-Tracking/CKD.
Cross-modulated Attention Transformer for RGBT Tracking
Aug 05, 2024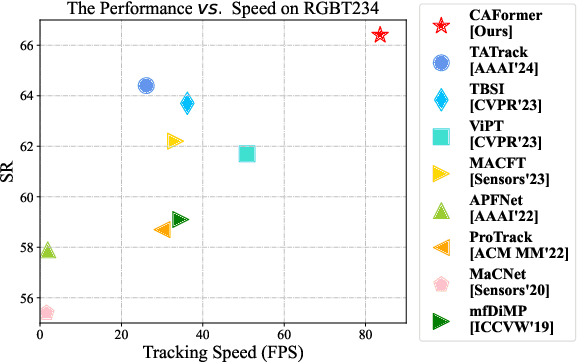
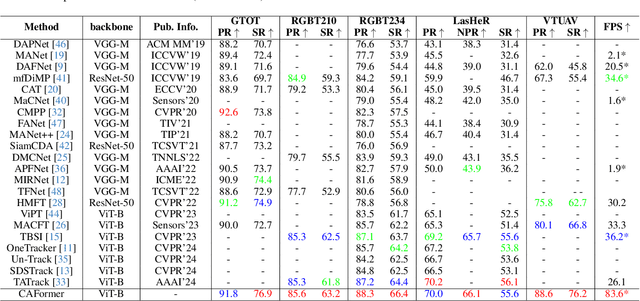
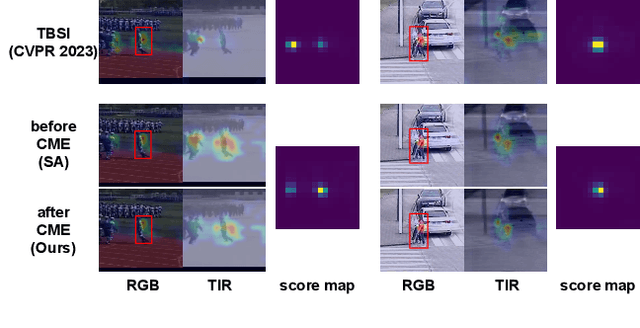
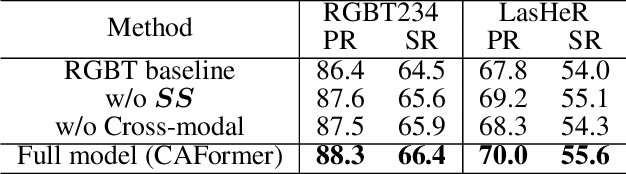
Existing Transformer-based RGBT trackers achieve remarkable performance benefits by leveraging self-attention to extract uni-modal features and cross-attention to enhance multi-modal feature interaction and template-search correlation computation. Nevertheless, the independent search-template correlation calculations ignore the consistency between branches, which can result in ambiguous and inappropriate correlation weights. It not only limits the intra-modal feature representation, but also harms the robustness of cross-attention for multi-modal feature interaction and search-template correlation computation. To address these issues, we propose a novel approach called Cross-modulated Attention Transformer (CAFormer), which performs intra-modality self-correlation, inter-modality feature interaction, and search-template correlation computation in a unified attention model, for RGBT tracking. In particular, we first independently generate correlation maps for each modality and feed them into the designed Correlation Modulated Enhancement module, modulating inaccurate correlation weights by seeking the consensus between modalities. Such kind of design unifies self-attention and cross-attention schemes, which not only alleviates inaccurate attention weight computation in self-attention but also eliminates redundant computation introduced by extra cross-attention scheme. In addition, we propose a collaborative token elimination strategy to further improve tracking inference efficiency and accuracy. Extensive experiments on five public RGBT tracking benchmarks show the outstanding performance of the proposed CAFormer against state-of-the-art methods.
Multi-Source EEG Emotion Recognition via Dynamic Contrastive Domain Adaptation
Aug 04, 2024



Electroencephalography (EEG) provides reliable indications of human cognition and mental states. Accurate emotion recognition from EEG remains challenging due to signal variations among individuals and across measurement sessions. To address these challenges, we introduce a multi-source dynamic contrastive domain adaptation method (MS-DCDA), which models coarse-grained inter-domain and fine-grained intra-class adaptations through a multi-branch contrastive neural network and contrastive sub-domain discrepancy learning. Our model leverages domain knowledge from each individual source and a complementary source ensemble and uses dynamically weighted learning to achieve an optimal tradeoff between domain transferability and discriminability. The proposed MS-DCDA model was evaluated using the SEED and SEED-IV datasets, achieving respectively the highest mean accuracies of $90.84\%$ and $78.49\%$ in cross-subject experiments as well as $95.82\%$ and $82.25\%$ in cross-session experiments. Our model outperforms several alternative domain adaptation methods in recognition accuracy, inter-class margin, and intra-class compactness. Our study also suggests greater emotional sensitivity in the frontal and parietal brain lobes, providing insights for mental health interventions, personalized medicine, and development of preventive strategies.
Automatic Generation of Product-Image Sequence in E-commerce
Jun 26, 2022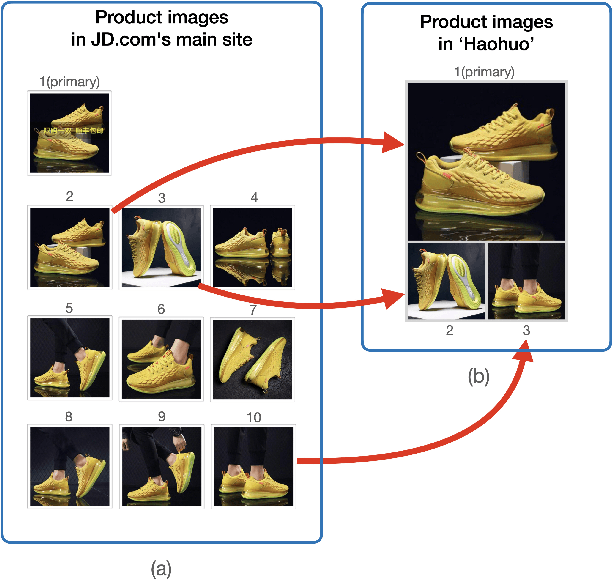

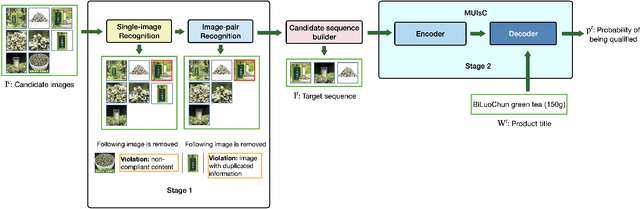
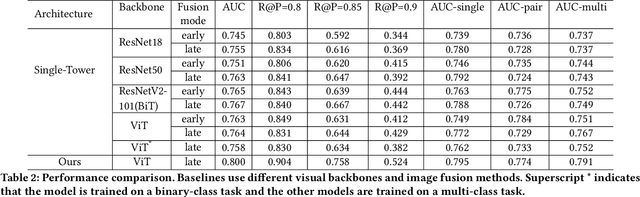
Product images are essential for providing desirable user experience in an e-commerce platform. For a platform with billions of products, it is extremely time-costly and labor-expensive to manually pick and organize qualified images. Furthermore, there are the numerous and complicated image rules that a product image needs to comply in order to be generated/selected. To address these challenges, in this paper, we present a new learning framework in order to achieve Automatic Generation of Product-Image Sequence (AGPIS) in e-commerce. To this end, we propose a Multi-modality Unified Image-sequence Classifier (MUIsC), which is able to simultaneously detect all categories of rule violations through learning. MUIsC leverages textual review feedback as the additional training target and utilizes product textual description to provide extra semantic information. Based on offline evaluations, we show that the proposed MUIsC significantly outperforms various baselines. Besides MUIsC, we also integrate some other important modules in the proposed framework, such as primary image selection, noncompliant content detection, and image deduplication. With all these modules, our framework works effectively and efficiently in JD.com recommendation platform. By Dec 2021, our AGPIS framework has generated high-standard images for about 1.5 million products and achieves 13.6% in reject rate.
Automatic Controllable Product Copywriting for E-Commerce
Jun 21, 2022
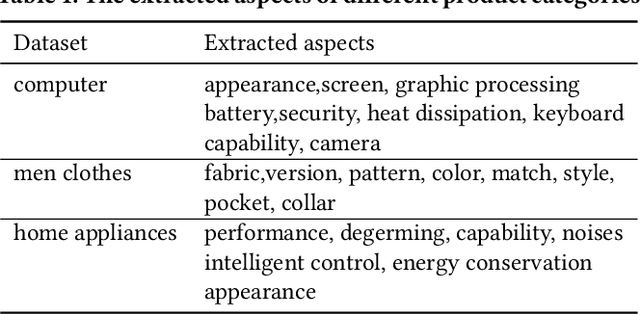
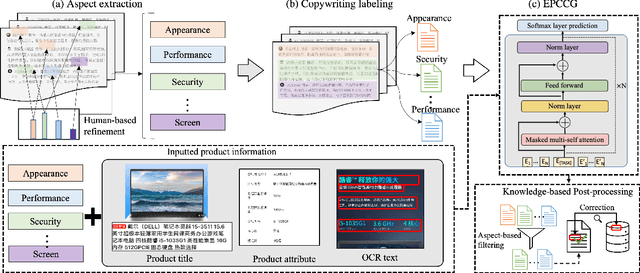
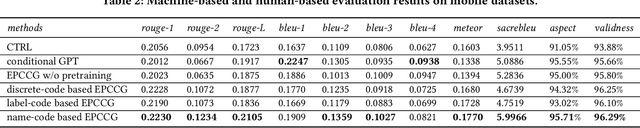
Automatic product description generation for e-commerce has witnessed significant advancement in the past decade. Product copywriting aims to attract users' interest and improve user experience by highlighting product characteristics with textual descriptions. As the services provided by e-commerce platforms become diverse, it is necessary to adapt the patterns of automatically-generated descriptions dynamically. In this paper, we report our experience in deploying an E-commerce Prefix-based Controllable Copywriting Generation (EPCCG) system into the JD.com e-commerce product recommendation platform. The development of the system contains two main components: 1) copywriting aspect extraction; 2) weakly supervised aspect labeling; 3) text generation with a prefix-based language model; 4) copywriting quality control. We conduct experiments to validate the effectiveness of the proposed EPCCG. In addition, we introduce the deployed architecture which cooperates with the EPCCG into the real-time JD.com e-commerce recommendation platform and the significant payoff since deployment.
TeKo: Text-Rich Graph Neural Networks with External Knowledge
Jun 15, 2022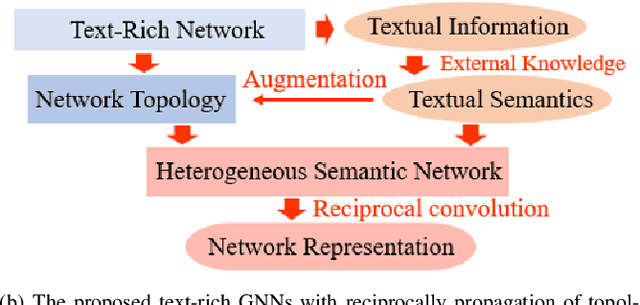
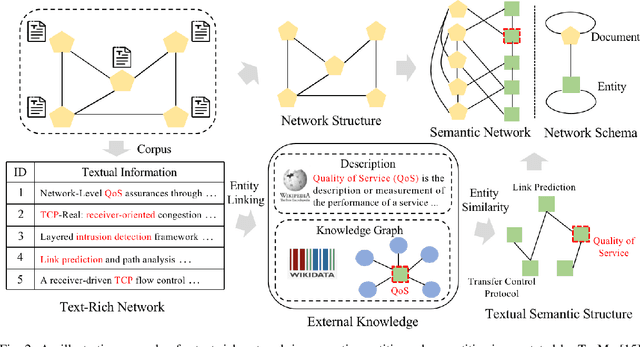
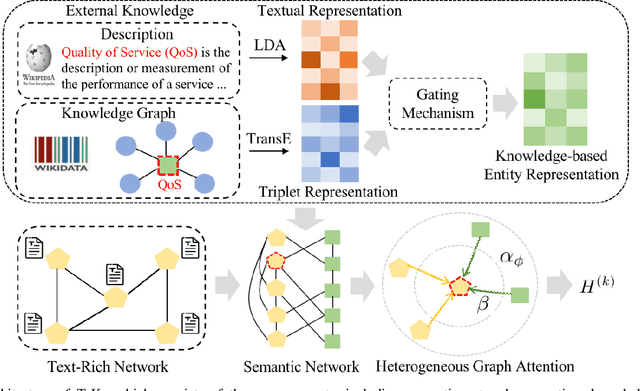

Graph Neural Networks (GNNs) have gained great popularity in tackling various analytical tasks on graph-structured data (i.e., networks). Typical GNNs and their variants follow a message-passing manner that obtains network representations by the feature propagation process along network topology, which however ignore the rich textual semantics (e.g., local word-sequence) that exist in many real-world networks. Existing methods for text-rich networks integrate textual semantics by mainly utilizing internal information such as topics or phrases/words, which often suffer from an inability to comprehensively mine the text semantics, limiting the reciprocal guidance between network structure and text semantics. To address these problems, we propose a novel text-rich graph neural network with external knowledge (TeKo), in order to take full advantage of both structural and textual information within text-rich networks. Specifically, we first present a flexible heterogeneous semantic network that incorporates high-quality entities and interactions among documents and entities. We then introduce two types of external knowledge, that is, structured triplets and unstructured entity description, to gain a deeper insight into textual semantics. We further design a reciprocal convolutional mechanism for the constructed heterogeneous semantic network, enabling network structure and textual semantics to collaboratively enhance each other and learn high-level network representations. Extensive experimental results on four public text-rich networks as well as a large-scale e-commerce searching dataset illustrate the superior performance of TeKo over state-of-the-art baselines.
Meta Policy Learning for Cold-Start Conversational Recommendation
May 24, 2022
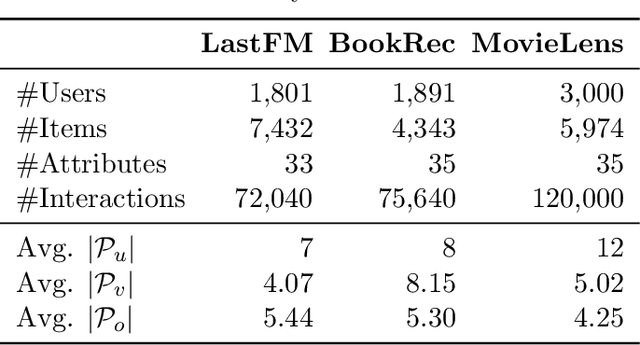
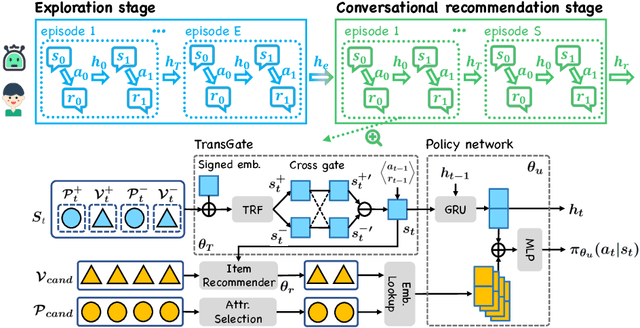
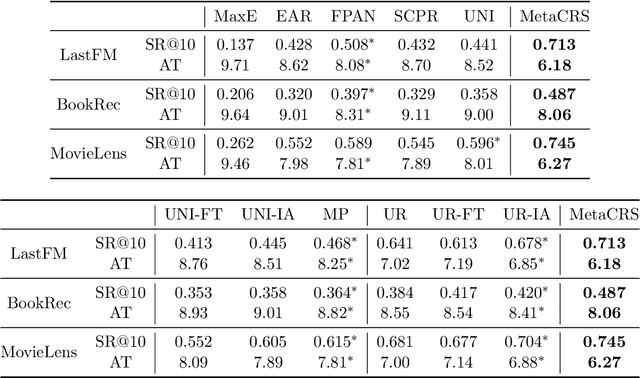
Conversational recommender systems (CRS) explicitly solicit users' preferences for improved recommendations on the fly. Most existing CRS solutions employ reinforcement learning methods to train a single policy for a population of users. However, for users new to the system, such a global policy becomes ineffective to produce conversational recommendations, i.e., the cold-start challenge. In this paper, we study CRS policy learning for cold-start users via meta reinforcement learning. We propose to learn a meta policy and adapt it to new users with only a few trials of conversational recommendations. To facilitate policy adaptation, we design three synergetic components. First is a meta-exploration policy dedicated to identify user preferences via exploratory conversations. Second is a Transformer-based state encoder to model a user's both positive and negative feedback during the conversation. And third is an adaptive item recommender based on the embedded states. Extensive experiments on three datasets demonstrate the advantage of our solution in serving new users, compared with a rich set of state-of-the-art CRS solutions.