 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking Modality Gap in RGBT Tracking: Coupled Knowledge Distillation
Oct 15, 2024



Modality gap between RGB and thermal infrared (TIR) images is a crucial issue but often overlooked in existing RGBT tracking methods. It can be observed that modality gap mainly lies in the image style difference. In this work, we propose a novel Coupled Knowledge Distillation framework called CKD, which pursues common styles of different modalities to break modality gap, for high performance RGBT tracking. In particular, we introduce two student networks and employ the style distillation loss to make their style features consistent as much as possible. Through alleviating the style difference of two student networks, we can break modality gap of different modalities well. However, the distillation of style features might harm to the content representations of two modalities in student networks. To handle this issue, we take original RGB and TIR networks as the teachers, and distill their content knowledge into two student networks respectively by the style-content orthogonal feature decoupling scheme. We couple the above two distillation processes in an online optimization framework to form new feature representations of RGB and thermal modalities without modality gap. In addition, we design a masked modeling strategy and a multi-modal candidate token elimination strategy into CKD to improve tracking robustness and efficiency respectively. Extensive experiments on five standard RGBT tracking datasets validate the effectiveness of the proposed method against state-of-the-art methods while achieving the fastest tracking speed of 96.4 FPS. Code available at https://github.com/Multi-Modality-Tracking/CKD.
Cross-modulated Attention Transformer for RGBT Tracking
Aug 05, 2024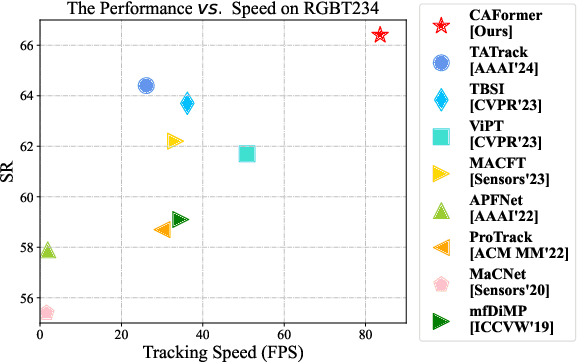
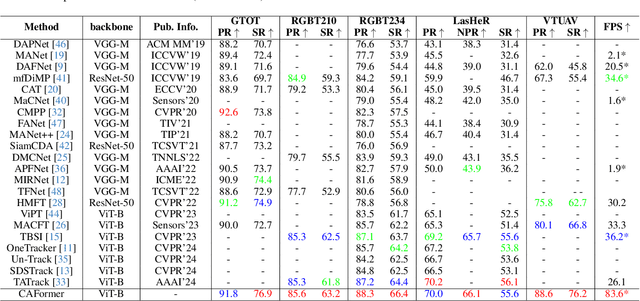
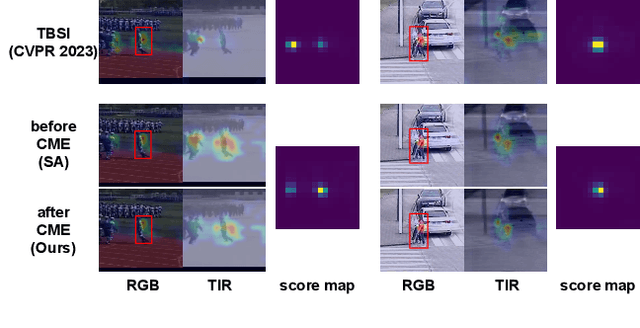
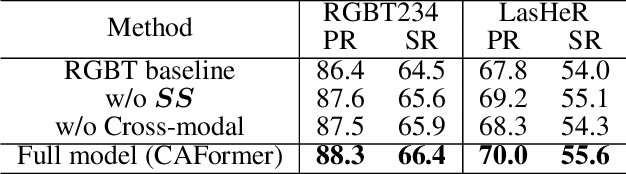
Existing Transformer-based RGBT trackers achieve remarkable performance benefits by leveraging self-attention to extract uni-modal features and cross-attention to enhance multi-modal feature interaction and template-search correlation computation. Nevertheless, the independent search-template correlation calculations ignore the consistency between branches, which can result in ambiguous and inappropriate correlation weights. It not only limits the intra-modal feature representation, but also harms the robustness of cross-attention for multi-modal feature interaction and search-template correlation computation. To address these issues, we propose a novel approach called Cross-modulated Attention Transformer (CAFormer), which performs intra-modality self-correlation, inter-modality feature interaction, and search-template correlation computation in a unified attention model, for RGBT tracking. In particular, we first independently generate correlation maps for each modality and feed them into the designed Correlation Modulated Enhancement module, modulating inaccurate correlation weights by seeking the consensus between modalities. Such kind of design unifies self-attention and cross-attention schemes, which not only alleviates inaccurate attention weight computation in self-attention but also eliminates redundant computation introduced by extra cross-attention scheme. In addition, we propose a collaborative token elimination strategy to further improve tracking inference efficiency and accuracy. Extensive experiments on five public RGBT tracking benchmarks show the outstanding performance of the proposed CAFormer against state-of-the-art methods.