 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robust Optical-SAR Object Detection under Missing Modalities: A Dynamic Quality-Aware Fusion Framework
Dec 27, 2025Optical and Synthetic Aperture Radar (SAR) fusion-based object detection has attracted significant research interest in remote sensing, as these modalities provide complementary information for all-weather monitoring. However, practical deployment is severely limited by inherent challenges. Due to distinct imaging mechanisms, temporal asynchrony, and registration difficulties, obtaining well-aligned optical-SAR image pairs remains extremely difficult, frequently resulting in missing or degraded modality data. Although recent approaches have attempted to address this issue, they still suffer from limited robustness to random missing modalities and lack effective mechanisms to ensure consistent performance improvement in fusion-based detection. To address these limitations, we propose a novel Quality-Aware Dynamic Fusion Network (QDFNet) for robust optical-SAR object detection. Our proposed method leverages learnable reference tokens to dynamically assess feature reliability and guide adaptive fusion in the presence of missing modalities. In particular, we design a Dynamic Modality Quality Assessment (DMQA) module that employs learnable reference tokens to iteratively refine feature reliability assessment, enabling precise identification of degraded regions and providing quality guidance for subsequent fusion. Moreover, we develop an Orthogonal Constraint Normalization Fusion (OCNF) module that employs orthogonal constraints to preserve modality independence while dynamically adjusting fusion weights based on reliability scores, effectively suppressing unreliable feature propagation. Extensive experiments on the SpaceNet6-OTD and OGSOD-2.0 datasets demonstrate the superiority and effectiveness of QDFNet compared to state-of-the-art methods, particularly under partial modality corruption or missing data scenarios.
NEXT: Multi-Grained Mixture of Experts via Text-Modulation for Multi-Modal Object Re-ID
May 26, 2025



Multi-modal object re-identification (ReID) aims to extract identity features across heterogeneous spectral modalities to enable accurate recognition and retrieval in complex real-world scenarios. However, most existing methods rely on implicit feature fusion structures, making it difficult to model fine-grained recognition strategies under varying challenging conditions. Benefiting from the powerful semantic understanding capabilities of Multi-modal Large Language Models (MLLMs), the visual appearance of an object can be effectively translated into descriptive text. In this paper, we propose a reliable multi-modal caption generation method based on attribute confidence, which significantly reduces the unknown recognition rate of MLLMs in multi-modal semantic generation and improves the quality of generated text. Additionally, we propose a novel ReID framework NEXT, the Multi-grained Mixture of Experts via Text-Modulation for Multi-modal Object Re-Identification. Specifically, we decouple the recognition problem into semantic and structural expert branches to separately capture modality-specific appearance and intrinsic structure. For semantic recognition, we propose the Text-Modulated Semantic-sampling Experts (TMSE), which leverages randomly sampled high-quality semantic texts to modulate expert-specific sampling of multi-modal features and mining intra-modality fine-grained semantic cues. Then, to recognize coarse-grained structure features, we propose the Context-Shared Structure-aware Experts (CSSE) that focuses on capturing the holistic object structure across modalities and maintains inter-modality structural consistency through a soft routing mechanism. Finally, we propose the Multi-Modal Feature Aggregation (MMFA), which adopts a unified feature fusion strategy to simply and effectively integrate semantic and structural expert outputs into the final identity representations.
Towards General Multimodal Visual Tracking
Mar 14, 2025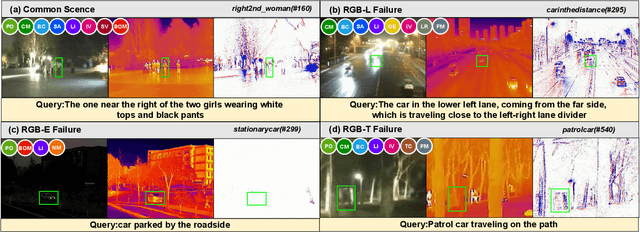
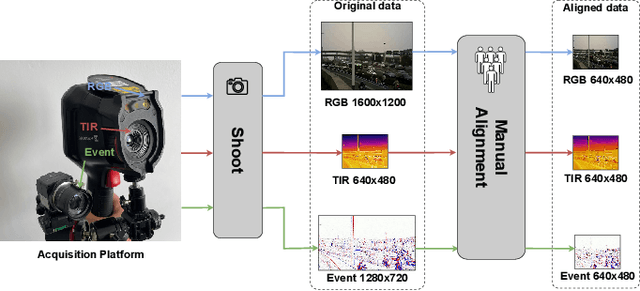
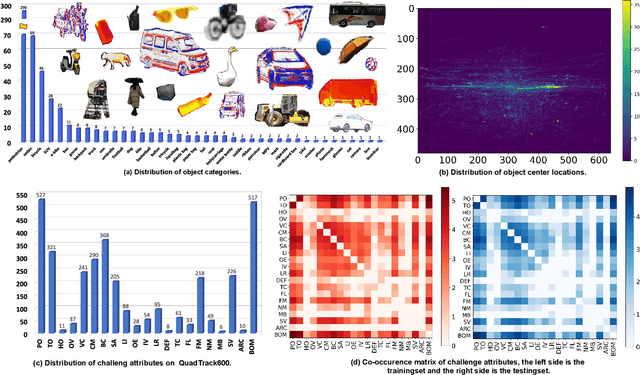
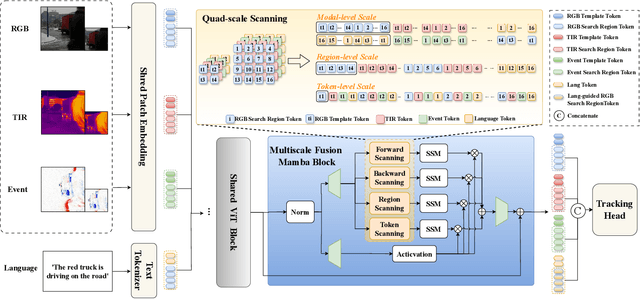
Existing multimodal tracking studies focus on bi-modal scenarios such as RGB-Thermal, RGB-Event, and RGB-Language. Although promising tracking performance is achieved through leveraging complementary cues from different sources, it remains challenging in complex scenes due to the limitations of bi-modal scenarios. In this work, we introduce a general multimodal visual tracking task that fully exploits the advantages of four modalities, including RGB, thermal infrared, event, and language, for robust tracking under challenging conditions. To provide a comprehensive evaluation platform for general multimodal visual tracking, we construct QuadTrack600, a large-scale, high-quality benchmark comprising 600 video sequences (totaling 384.7K high-resolution (640x480) frame groups). In each frame group, all four modalities are spatially aligned and meticulously annotated with bounding boxes, while 21 sequence-level challenge attributes are provided for detailed performance analysis. Despite quad-modal data provides richer information, the differences in information quantity among modalities and the computational burden from four modalities are two challenging issues in fusing four modalities. To handle these issues, we propose a novel approach called QuadFusion, which incorporates an efficient Multiscale Fusion Mamba with four different scanning scales to achieve sufficient interactions of the four modalities while overcoming the exponential computational burden, for general multimodal visual tracking. Extensive experiments on the QuadTrack600 dataset and three bi-modal tracking datasets, including LasHeR, VisEvent, and TNL2K, validate the effectiveness of our QuadFusion.
Breaking Shallow Limits: Task-Driven Pixel Fusion for Gap-free RGBT Tracking
Mar 14, 2025Current RGBT tracking methods often overlook the impact of fusion location on mitigating modality gap, which is key factor to effective tracking. Our analysis reveals that shallower fusion yields smaller distribution gap. However, the limited discriminative power of shallow networks hard to distinguish task-relevant information from noise, limiting the potential of pixel-level fusion. To break shallow limits, we propose a novel \textbf{T}ask-driven \textbf{P}ixel-level \textbf{F}usion network, named \textbf{TPF}, which unveils the power of pixel-level fusion in RGBT tracking through a progressive learning framework. In particular, we design a lightweight Pixel-level Fusion Adapter (PFA) that exploits Mamba's linear complexity to ensure real-time, low-latency RGBT tracking. To enhance the fusion capabilities of the PFA, our task-driven progressive learning framework first utilizes adaptive multi-expert distillation to inherits fusion knowledge from state-of-the-art image fusion models, establishing robust initialization, and then employs a decoupled representation learning scheme to achieve task-relevant information fusion. Moreover, to overcome appearance variations between the initial template and search frames, we presents a nearest-neighbor dynamic template updating scheme, which selects the most reliable frame closest to the current search frame as the dynamic template. Extensive experiments demonstrate that TPF significantly outperforms existing most of advanced trackers on four public RGBT tracking datasets. The code will be released upon acceptance.
Breaking Modality Gap in RGBT Tracking: Coupled Knowledge Distillation
Oct 15, 2024



Modality gap between RGB and thermal infrared (TIR) images is a crucial issue but often overlooked in existing RGBT tracking methods. It can be observed that modality gap mainly lies in the image style difference. In this work, we propose a novel Coupled Knowledge Distillation framework called CKD, which pursues common styles of different modalities to break modality gap, for high performance RGBT tracking. In particular, we introduce two student networks and employ the style distillation loss to make their style features consistent as much as possible. Through alleviating the style difference of two student networks, we can break modality gap of different modalities well. However, the distillation of style features might harm to the content representations of two modalities in student networks. To handle this issue, we take original RGB and TIR networks as the teachers, and distill their content knowledge into two student networks respectively by the style-content orthogonal feature decoupling scheme. We couple the above two distillation processes in an online optimization framework to form new feature representations of RGB and thermal modalities without modality gap. In addition, we design a masked modeling strategy and a multi-modal candidate token elimination strategy into CKD to improve tracking robustness and efficiency respectively. Extensive experiments on five standard RGBT tracking datasets validate the effectiveness of the proposed method against state-of-the-art methods while achieving the fastest tracking speed of 96.4 FPS. Code available at https://github.com/Multi-Modality-Tracking/CKD.
RGBT Tracking via All-layer Multimodal Interactions with Progressive Fusion Mamba
Aug 16, 2024Existing RGBT tracking methods often design various interaction models to perform cross-modal fusion of each layer, but can not execute the feature interactions among all layers, which plays a critical role in robust multimodal representation, due to large computational burden. To address this issue, this paper presents a novel All-layer multimodal Interaction Network, named AINet, which performs efficient and effective feature interactions of all modalities and layers in a progressive fusion Mamba, for robust RGBT tracking. Even though modality features in different layers are known to contain different cues, it is always challenging to build multimodal interactions in each layer due to struggling in balancing interaction capabilities and efficiency. Meanwhile, considering that the feature discrepancy between RGB and thermal modalities reflects their complementary information to some extent, we design a Difference-based Fusion Mamba (DFM) to achieve enhanced fusion of different modalities with linear complexity. When interacting with features from all layers, a huge number of token sequences (3840 tokens in this work) are involved and the computational burden is thus large. To handle this problem, we design an Order-dynamic Fusion Mamba (OFM) to execute efficient and effective feature interactions of all layers by dynamically adjusting the scan order of different layers in Mamba. Extensive experiments on four public RGBT tracking datasets show that AINet achieves leading performance against existing state-of-the-art methods.
Cross-modulated Attention Transformer for RGBT Tracking
Aug 05, 2024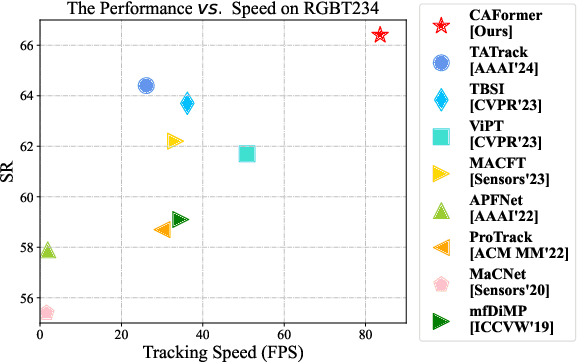
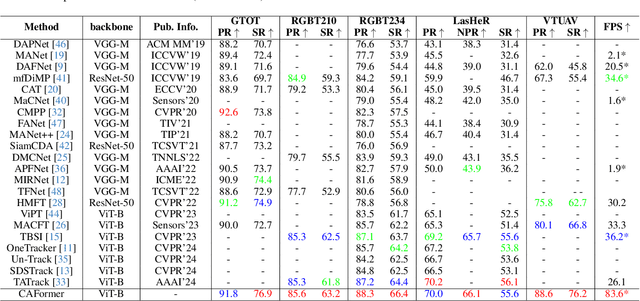
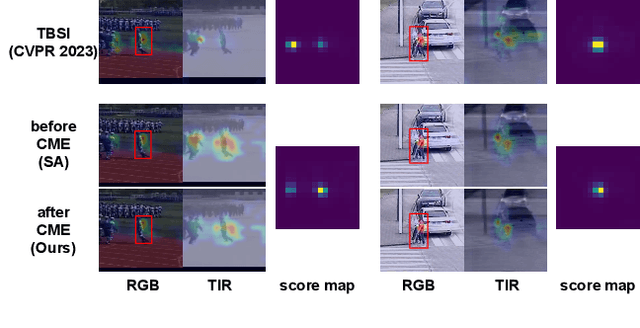
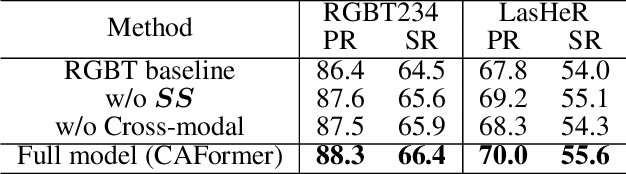
Existing Transformer-based RGBT trackers achieve remarkable performance benefits by leveraging self-attention to extract uni-modal features and cross-attention to enhance multi-modal feature interaction and template-search correlation computation. Nevertheless, the independent search-template correlation calculations ignore the consistency between branches, which can result in ambiguous and inappropriate correlation weights. It not only limits the intra-modal feature representation, but also harms the robustness of cross-attention for multi-modal feature interaction and search-template correlation computation. To address these issues, we propose a novel approach called Cross-modulated Attention Transformer (CAFormer), which performs intra-modality self-correlation, inter-modality feature interaction, and search-template correlation computation in a unified attention model, for RGBT tracking. In particular, we first independently generate correlation maps for each modality and feed them into the designed Correlation Modulated Enhancement module, modulating inaccurate correlation weights by seeking the consensus between modalities. Such kind of design unifies self-attention and cross-attention schemes, which not only alleviates inaccurate attention weight computation in self-attention but also eliminates redundant computation introduced by extra cross-attention scheme. In addition, we propose a collaborative token elimination strategy to further improve tracking inference efficiency and accuracy. Extensive experiments on five public RGBT tracking benchmarks show the outstanding performance of the proposed CAFormer against state-of-the-art methods.
AFter: Attention-based Fusion Router for RGBT Tracking
May 04, 2024



Multi-modal feature fusion as a core investigative component of RGBT tracking emerges numerous fusion studies in recent years. However, existing RGBT tracking methods widely adopt fixed fusion structures to integrate multi-modal feature, which are hard to handle various challenges in dynamic scenarios. To address this problem, this work presents a novel \emph{A}ttention-based \emph{F}usion rou\emph{ter} called AFter, which optimizes the fusion structure to adapt to the dynamic challenging scenarios, for robust RGBT tracking. In particular, we design a fusion structure space based on the hierarchical attention network, each attention-based fusion unit corresponding to a fusion operation and a combination of these attention units corresponding to a fusion structure. Through optimizing the combination of attention-based fusion units, we can dynamically select the fusion structure to adapt to various challenging scenarios. Unlike complex search of different structures in neural architecture search algorithms, we develop a dynamic routing algorithm, which equips each attention-based fusion unit with a router, to predict the combination weights for efficient optimization of the fusion structure. Extensive experiments on five mainstream RGBT tracking datasets demonstrate the superior performance of the proposed AFter against state-of-the-art RGBT trackers. We release the code in https://github.com/Alexadlu/AFter.
Transformer RGBT Tracking with Spatio-Temporal Multimodal Tokens
Jan 03, 2024



Many RGBT tracking researches primarily focus on modal fusion design, while overlooking the effective handling of target appearance changes. While some approaches have introduced historical frames or fuse and replace initial templates to incorporate temporal information, they have the risk of disrupting the original target appearance and accumulating errors over time. To alleviate these limitations, we propose a novel Transformer RGBT tracking approach, which mixes spatio-temporal multimodal tokens from the static multimodal templates and multimodal search regions in Transformer to handle target appearance changes, for robust RGBT tracking. We introduce independent dynamic template tokens to interact with the search region, embedding temporal information to address appearance changes, while also retaining the involvement of the initial static template tokens in the joint feature extraction process to ensure the preservation of the original reliable target appearance information that prevent deviations from the target appearance caused by traditional temporal updates. We also use attention mechanisms to enhance the target features of multimodal template tokens by incorporating supplementary modal cues, and make the multimodal search region tokens interact with multimodal dynamic template tokens via attention mechanisms, which facilitates the conveyance of multimodal-enhanced target change information. Our module is inserted into the transformer backbone network and inherits joint feature extraction, search-template matching, and cross-modal interaction. Extensive experiments on three RGBT benchmark datasets show that the proposed approach maintains competitive performance compared to other state-of-the-art tracking algorithms while running at 39.1 FPS.
Modality-missing RGBT Tracking via Invertible Prompt Learning and A High-quality Data Simulation Method
Dec 25, 2023



Current RGBT tracking researches mainly focus on the modality-complete scenarios, overlooking the modality-missing challenge in real-world scenes. In this work, we comprehensively investigate the impact of modality-missing challenge in RGBT tracking and propose a novel invertible prompt learning approach, which integrates the content-preserving prompts into a well-trained tracking model to adapt to various modality-missing scenarios, for modality-missing RGBT tracking. In particular, given one modality-missing scenario, we propose to utilize the available modality to generate the prompt of the missing modality to adapt to RGBT tracking model. However, the cross-modality gap between available and missing modalities usually causes semantic distortion and information loss in prompt generation. To handle this issue, we propose the invertible prompt learning scheme by incorporating the full reconstruction of the input available modality from the prompt in prompt generation model. Considering that there lacks a modality-missing RGBT tracking dataset and many modality-missing scenarios are difficult to capture, we design a high-quality data simulation method based on hierarchical combination schemes to generate real-world modality-missing data. Extensive experiments on three modality-missing datasets show that our method achieves significant performance improvements compared with state-of-the-art methods. We will release the code and simulation dataset.