 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards General Multimodal Visual Tracking
Mar 14, 2025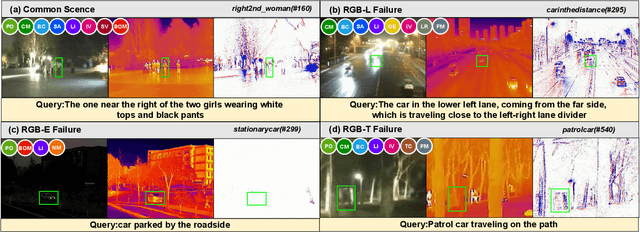
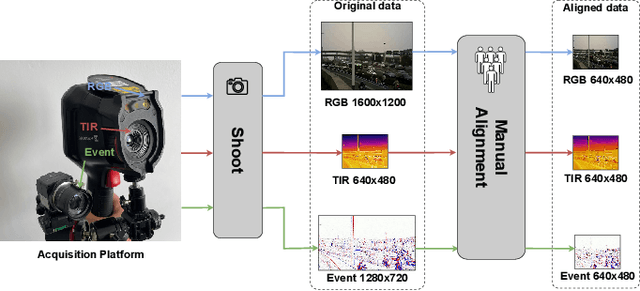
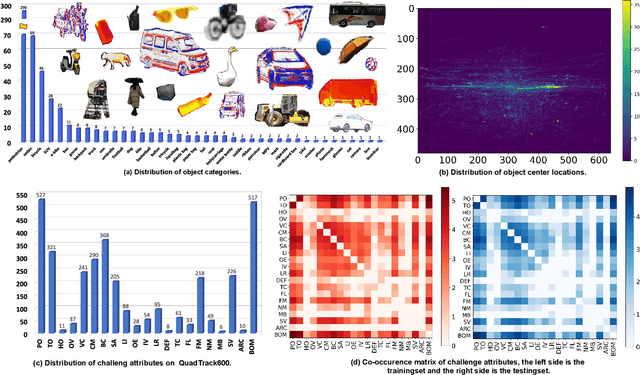
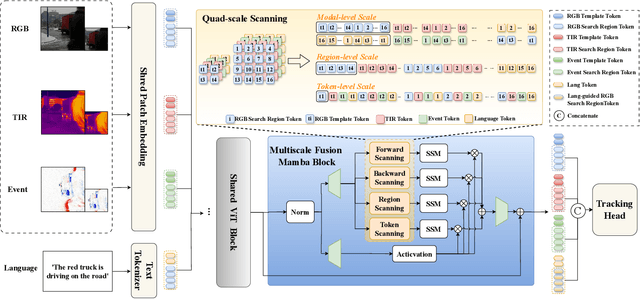
Existing multimodal tracking studies focus on bi-modal scenarios such as RGB-Thermal, RGB-Event, and RGB-Language. Although promising tracking performance is achieved through leveraging complementary cues from different sources, it remains challenging in complex scenes due to the limitations of bi-modal scenarios. In this work, we introduce a general multimodal visual tracking task that fully exploits the advantages of four modalities, including RGB, thermal infrared, event, and language, for robust tracking under challenging conditions. To provide a comprehensive evaluation platform for general multimodal visual tracking, we construct QuadTrack600, a large-scale, high-quality benchmark comprising 600 video sequences (totaling 384.7K high-resolution (640x480) frame groups). In each frame group, all four modalities are spatially aligned and meticulously annotated with bounding boxes, while 21 sequence-level challenge attributes are provided for detailed performance analysis. Despite quad-modal data provides richer information, the differences in information quantity among modalities and the computational burden from four modalities are two challenging issues in fusing four modalities. To handle these issues, we propose a novel approach called QuadFusion, which incorporates an efficient Multiscale Fusion Mamba with four different scanning scales to achieve sufficient interactions of the four modalities while overcoming the exponential computational burden, for general multimodal visual tracking. Extensive experiments on the QuadTrack600 dataset and three bi-modal tracking datasets, including LasHeR, VisEvent, and TNL2K, validate the effectiveness of our QuadFusion.
Breaking Shallow Limits: Task-Driven Pixel Fusion for Gap-free RGBT Tracking
Mar 14, 2025Current RGBT tracking methods often overlook the impact of fusion location on mitigating modality gap, which is key factor to effective tracking. Our analysis reveals that shallower fusion yields smaller distribution gap. However, the limited discriminative power of shallow networks hard to distinguish task-relevant information from noise, limiting the potential of pixel-level fusion. To break shallow limits, we propose a novel \textbf{T}ask-driven \textbf{P}ixel-level \textbf{F}usion network, named \textbf{TPF}, which unveils the power of pixel-level fusion in RGBT tracking through a progressive learning framework. In particular, we design a lightweight Pixel-level Fusion Adapter (PFA) that exploits Mamba's linear complexity to ensure real-time, low-latency RGBT tracking. To enhance the fusion capabilities of the PFA, our task-driven progressive learning framework first utilizes adaptive multi-expert distillation to inherits fusion knowledge from state-of-the-art image fusion models, establishing robust initialization, and then employs a decoupled representation learning scheme to achieve task-relevant information fusion. Moreover, to overcome appearance variations between the initial template and search frames, we presents a nearest-neighbor dynamic template updating scheme, which selects the most reliable frame closest to the current search frame as the dynamic template. Extensive experiments demonstrate that TPF significantly outperforms existing most of advanced trackers on four public RGBT tracking datasets. The code will be released upon acceptance.