 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNEXT: Multi-Grained Mixture of Experts via Text-Modulation for Multi-Modal Object Re-ID
May 26, 2025



Multi-modal object re-identification (ReID) aims to extract identity features across heterogeneous spectral modalities to enable accurate recognition and retrieval in complex real-world scenarios. However, most existing methods rely on implicit feature fusion structures, making it difficult to model fine-grained recognition strategies under varying challenging conditions. Benefiting from the powerful semantic understanding capabilities of Multi-modal Large Language Models (MLLMs), the visual appearance of an object can be effectively translated into descriptive text. In this paper, we propose a reliable multi-modal caption generation method based on attribute confidence, which significantly reduces the unknown recognition rate of MLLMs in multi-modal semantic generation and improves the quality of generated text. Additionally, we propose a novel ReID framework NEXT, the Multi-grained Mixture of Experts via Text-Modulation for Multi-modal Object Re-Identification. Specifically, we decouple the recognition problem into semantic and structural expert branches to separately capture modality-specific appearance and intrinsic structure. For semantic recognition, we propose the Text-Modulated Semantic-sampling Experts (TMSE), which leverages randomly sampled high-quality semantic texts to modulate expert-specific sampling of multi-modal features and mining intra-modality fine-grained semantic cues. Then, to recognize coarse-grained structure features, we propose the Context-Shared Structure-aware Experts (CSSE) that focuses on capturing the holistic object structure across modalities and maintains inter-modality structural consistency through a soft routing mechanism. Finally, we propose the Multi-Modal Feature Aggregation (MMFA), which adopts a unified feature fusion strategy to simply and effectively integrate semantic and structural expert outputs into the final identity representations.
Reliable Multi-Modal Object Re-Identification via Modality-Aware Graph Reasoning
Apr 21, 2025Multi-modal data provides abundant and diverse object information, crucial for effective modal interactions in Re-Identification (ReID) tasks. However, existing approaches often overlook the quality variations in local features and fail to fully leverage the complementary information across modalities, particularly in the case of low-quality features. In this paper, we propose to address this issue by leveraging a novel graph reasoning model, termed the Modality-aware Graph Reasoning Network (MGRNet). Specifically, we first construct modality-aware graphs to enhance the extraction of fine-grained local details by effectively capturing and modeling the relationships between patches. Subsequently, the selective graph nodes swap operation is employed to alleviate the adverse effects of low-quality local features by considering both local and global information, enhancing the representation of discriminative information. Finally, the swapped modality-aware graphs are fed into the local-aware graph reasoning module, which propagates multi-modal information to yield a reliable feature representation. Another advantage of the proposed graph reasoning approach is its ability to reconstruct missing modal information by exploiting inherent structural relationships, thereby minimizing disparities between different modalities. Experimental results on four benchmarks (RGBNT201, Market1501-MM, RGBNT100, MSVR310) indicate that the proposed method achieves state-of-the-art performance in multi-modal object ReID. The code for our method will be available upon acceptance.
WSC-Trans: A 3D network model for automatic multi-structural segmentation of temporal bone CT
Nov 14, 2022Cochlear implantation is currently the most effective treatment for patients with severe deafness, but mastering cochlear implantation is extremely challenging because the temporal bone has extremely complex and small three-dimensional anatomical structures, and it is important to avoid damaging the corresponding structures when performing surgery. The spatial location of the relevant anatomical tissues within the target area needs to be determined using CT prior to the procedure. Considering that the target structures are too small and complex, the time required for manual segmentation is too long, and it is extremely challenging to segment the temporal bone and its nearby anatomical structures quickly and accurately. To overcome this difficulty, we propose a deep learning-based algorithm, a 3D network model for automatic segmentation of multi-structural targets in temporal bone CT that can automatically segment the cochlea, facial nerve, auditory tubercle, vestibule and semicircular canal. The algorithm combines CNN and Transformer for feature extraction and takes advantage of spatial attention and channel attention mechanisms to further improve the segmentation effect, the experimental results comparing with the results of various existing segmentation algorithms show that the dice similarity scores, Jaccard coefficients of all targets anatomical structures are significantly higher while HD95 and ASSD scores are lower, effectively proving that our method outperforms other advanced methods.
Multi-spectral Vehicle Re-identification with Cross-directional Consistency Network and a High-quality Benchmark
Aug 01, 2022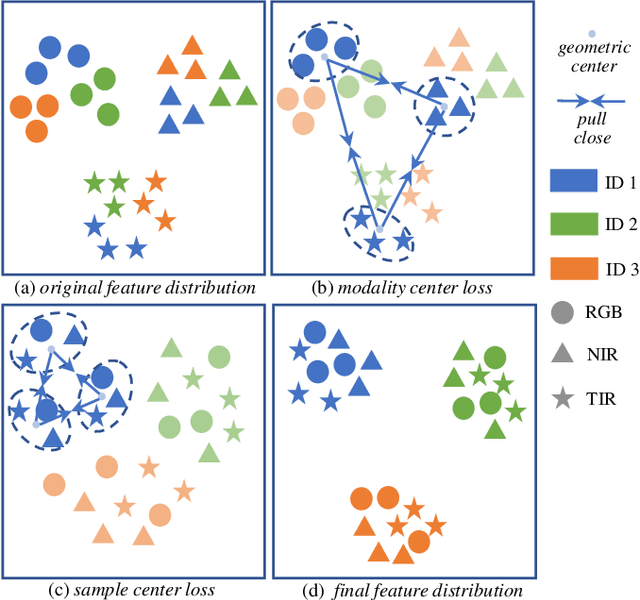
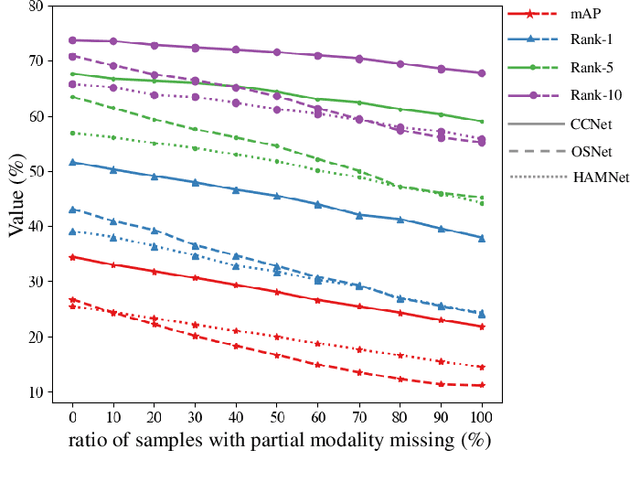
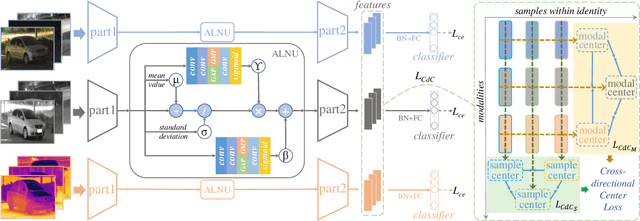
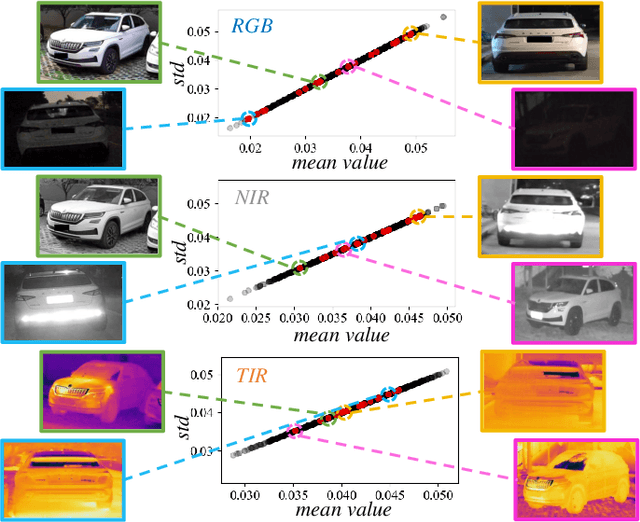
To tackle the challenge of vehicle re-identification (Re-ID) in complex lighting environments and diverse scenes, multi-spectral sources like visible and infrared information are taken into consideration due to their excellent complementary advantages. However, multi-spectral vehicle Re-ID suffers cross-modality discrepancy caused by heterogeneous properties of different modalities as well as a big challenge of the diverse appearance with different views in each identity. Meanwhile, diverse environmental interference leads to heavy sample distributional discrepancy in each modality. In this work, we propose a novel cross-directional consistency network to simultaneously overcome the discrepancies from both modality and sample aspects. In particular, we design a new cross-directional center loss to pull the modality centers of each identity close to mitigate cross-modality discrepancy, while the sample centers of each identity close to alleviate the sample discrepancy. Such strategy can generate discriminative multi-spectral feature representations for vehicle Re-ID. In addition, we design an adaptive layer normalization unit to dynamically adjust individual feature distribution to handle distributional discrepancy of intra-modality features for robust learning. To provide a comprehensive evaluation platform, we create a high-quality RGB-NIR-TIR multi-spectral vehicle Re-ID benchmark (MSVR310), including 310 different vehicles from a broad range of viewpoints, time spans and environmental complexities. Comprehensive experiments on both created and public datasets demonstrate the effectiveness of the proposed approach comparing to the state-of-the-art methods.