 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Translation Evaluation Benchmark for Wu Chinese: Workflow and Analysis
Oct 14, 2024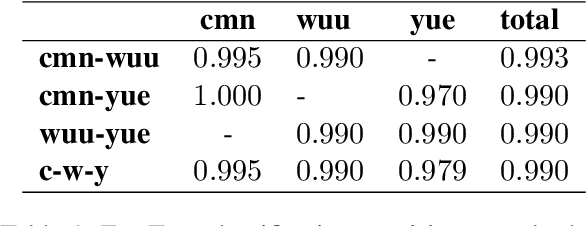
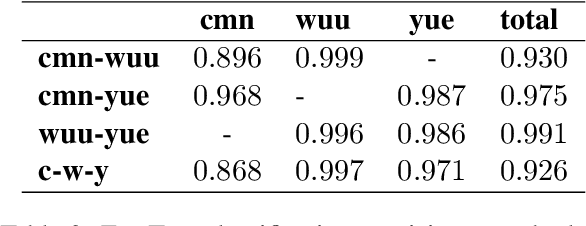
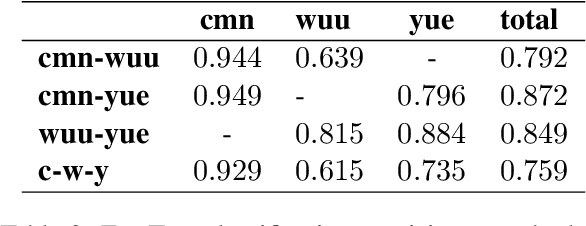
We introduce a FLORES+ dataset as an evaluation benchmark for modern Wu Chinese machine translation models and showcase its compatibility with existing Wu data. Wu Chinese is mutually unintelligible with other Sinitic languages such as Mandarin and Yue (Cantonese), but uses a set of Hanzi (Chinese characters) that profoundly overlaps with others. The population of Wu speakers is the second largest among languages in China, but the language has been suffering from significant drop in usage especially among the younger generations. We identify Wu Chinese as a textually low-resource language and address challenges for its machine translation models. Our contributions include: (1) an open-source, manually translated dataset, (2) full documentations on the process of dataset creation and validation experiments, (3) preliminary tools for Wu Chinese normalization and segmentation, and (4) benefits and limitations of our dataset, as well as implications to other low-resource languages.
Demonstration of MaskSearch: Efficiently Querying Image Masks for Machine Learning Workflows
Apr 09, 2024
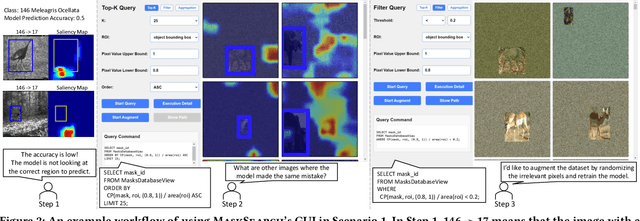


We demonstrate MaskSearch, a system designed to accelerate queries over databases of image masks generated by machine learning models. MaskSearch formalizes and accelerates a new category of queries for retrieving images and their corresponding masks based on mask properties, which support various applications, from identifying spurious correlations learned by models to exploring discrepancies between model saliency and human attention. This demonstration makes the following contributions:(1) the introduction of MaskSearch's graphical user interface (GUI), which enables interactive exploration of image databases through mask properties, (2) hands-on opportunities for users to explore MaskSearch's capabilities and constraints within machine learning workflows, and (3) an opportunity for conference attendees to understand how MaskSearch accelerates queries over image masks.
Convolutional neural network based on sparse graph attention mechanism for MRI super-resolution
May 29, 2023Magnetic resonance imaging (MRI) is a valuable clinical tool for displaying anatomical structures and aiding in accurate diagnosis. Medical image super-resolution (SR) reconstruction using deep learning techniques can enhance lesion analysis and assist doctors in improving diagnostic efficiency and accuracy. However, existing deep learning-based SR methods predominantly rely on convolutional neural networks (CNNs), which inherently limit the expressive capabilities of these models and therefore make it challenging to discover potential relationships between different image features. To overcome this limitation, we propose an A-network that utilizes multiple convolution operator feature extraction modules (MCO) for extracting image features using multiple convolution operators. These extracted features are passed through multiple sets of cross-feature extraction modules (MSC) to highlight key features through inter-channel feature interactions, enabling subsequent feature learning. An attention-based sparse graph neural network module is incorporated to establish relationships between pixel features, learning which adjacent pixels have the greatest impact on determining the features to be filled. To evaluate our model's effectiveness, we conducted experiments using different models on data generated from multiple datasets with different degradation multiples, and the experimental results show that our method is a significant improvement over the current state-of-the-art methods.
Spatial Correspondence between Graph Neural Network-Segmented Images
Mar 17, 2023Graph neural networks (GNNs) have been proposed for medical image segmentation, by predicting anatomical structures represented by graphs of vertices and edges. One such type of graph is predefined with fixed size and connectivity to represent a reference of anatomical regions of interest, thus known as templates. This work explores the potentials in these GNNs with common topology for establishing spatial correspondence, implicitly maintained during segmenting two or more images. With an example application of registering local vertebral sub-regions found in CT images, our experimental results showed that the GNN-based segmentation is capable of accurate and reliable localization of the same interventionally interesting structures between images, not limited to the segmentation classes. The reported average target registration errors of 2.2$\pm$1.3 mm and 2.7$\pm$1.4 mm, for aligning holdout test images with a reference and for aligning two test images, respectively, were by a considerable margin lower than those from the tested non-learning and learning-based registration algorithms. Further ablation studies assess the contributions towards the registration performance, from individual components in the originally segmentation-purposed network and its training algorithm. The results highlight that the proposed segmentation-in-lieu-of-registration approach shares methodological similarities with existing registration methods, such as the use of displacement smoothness constraint and point distance minimization albeit on non-grid graphs, which interestingly yielded benefits for both segmentation and registration. We, therefore, conclude that the template-based GNN segmentation can effectively establish spatial correspondence in our application, without any other dedicated registration algorithms.
WSC-Trans: A 3D network model for automatic multi-structural segmentation of temporal bone CT
Nov 14, 2022Cochlear implantation is currently the most effective treatment for patients with severe deafness, but mastering cochlear implantation is extremely challenging because the temporal bone has extremely complex and small three-dimensional anatomical structures, and it is important to avoid damaging the corresponding structures when performing surgery. The spatial location of the relevant anatomical tissues within the target area needs to be determined using CT prior to the procedure. Considering that the target structures are too small and complex, the time required for manual segmentation is too long, and it is extremely challenging to segment the temporal bone and its nearby anatomical structures quickly and accurately. To overcome this difficulty, we propose a deep learning-based algorithm, a 3D network model for automatic segmentation of multi-structural targets in temporal bone CT that can automatically segment the cochlea, facial nerve, auditory tubercle, vestibule and semicircular canal. The algorithm combines CNN and Transformer for feature extraction and takes advantage of spatial attention and channel attention mechanisms to further improve the segmentation effect, the experimental results comparing with the results of various existing segmentation algorithms show that the dice similarity scores, Jaccard coefficients of all targets anatomical structures are significantly higher while HD95 and ASSD scores are lower, effectively proving that our method outperforms other advanced methods.