 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKathDB: Explainable Multimodal Database Management System with Human-AI Collaboration
Dec 11, 2025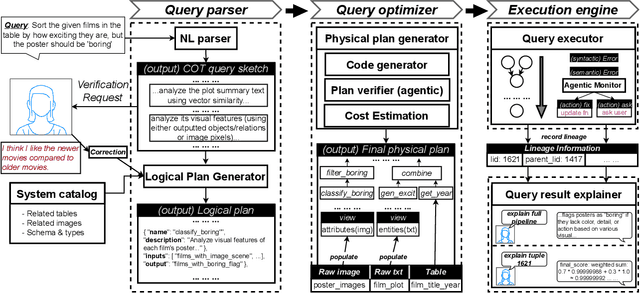

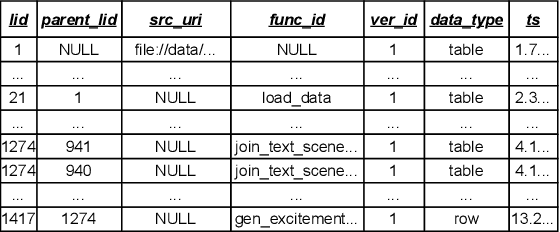
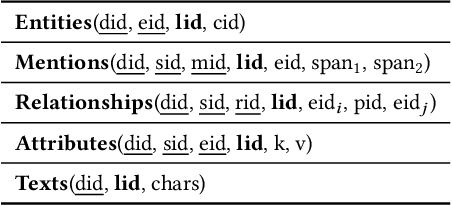
Traditional DBMSs execute user- or application-provided SQL queries over relational data with strong semantic guarantees and advanced query optimization, but writing complex SQL is hard and focuses only on structured tables. Contemporary multimodal systems (which operate over relations but also text, images, and even videos) either expose low-level controls that force users to use (and possibly create) machine learning UDFs manually within SQL or offload execution entirely to black-box LLMs, sacrificing usability or explainability. We propose KathDB, a new system that combines relational semantics with the reasoning power of foundation models over multimodal data. Furthermore, KathDB includes human-AI interaction channels during query parsing, execution, and result explanation, such that users can iteratively obtain explainable answers across data modalities.
RACOON: An LLM-based Framework for Retrieval-Augmented Column Type Annotation with a Knowledge Graph
Sep 22, 2024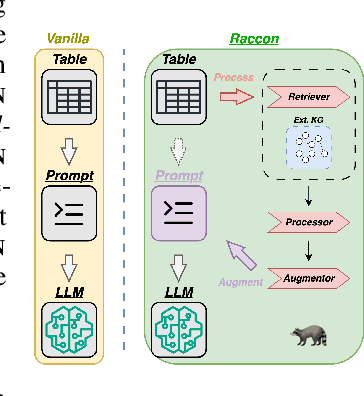



As an important component of data exploration and integration, Column Type Annotation (CTA) aims to label columns of a table with one or more semantic types. With the recent development of Large Language Models (LLMs), researchers have started to explore the possibility of using LLMs for CTA, leveraging their strong zero-shot capabilities. In this paper, we build on this promising work and improve on LLM-based methods for CTA by showing how to use a Knowledge Graph (KG) to augment the context information provided to the LLM. Our approach, called RACOON, combines both pre-trained parametric and non-parametric knowledge during generation to improve LLMs' performance on CTA. Our experiments show that RACOON achieves up to a 0.21 micro F-1 improvement compared against vanilla LLM inference.
Demonstration of MaskSearch: Efficiently Querying Image Masks for Machine Learning Workflows
Apr 09, 2024
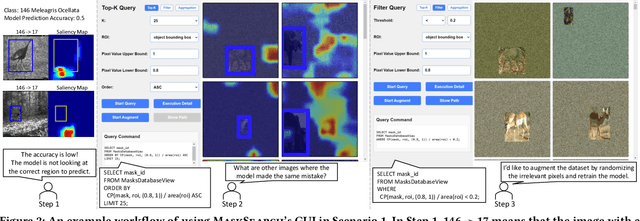


We demonstrate MaskSearch, a system designed to accelerate queries over databases of image masks generated by machine learning models. MaskSearch formalizes and accelerates a new category of queries for retrieving images and their corresponding masks based on mask properties, which support various applications, from identifying spurious correlations learned by models to exploring discrepancies between model saliency and human attention. This demonstration makes the following contributions:(1) the introduction of MaskSearch's graphical user interface (GUI), which enables interactive exploration of image databases through mask properties, (2) hands-on opportunities for users to explore MaskSearch's capabilities and constraints within machine learning workflows, and (3) an opportunity for conference attendees to understand how MaskSearch accelerates queries over image masks.
MaskSearch: Querying Image Masks at Scale
May 03, 2023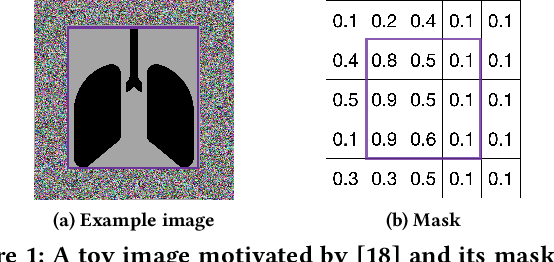


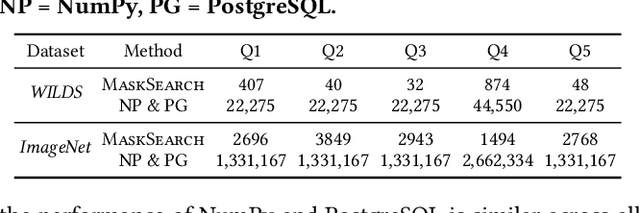
Machine learning tasks over image databases often generate masks that annotate image content (e.g., saliency maps, segmentation maps) and enable a variety of applications (e.g., determine if a model is learning spurious correlations or if an image was maliciously modified to mislead a model). While queries that retrieve examples based on mask properties are valuable to practitioners, existing systems do not support such queries efficiently. In this paper, we formalize the problem and propose a system, MaskSearch, that focuses on accelerating queries over databases of image masks. MaskSearch leverages a novel indexing technique and an efficient filter-verification query execution framework. Experiments on real-world datasets with our prototype show that MaskSearch, using indexes approximately 5% the size of the data, accelerates individual queries by up to two orders of magnitude and consistently outperforms existing methods on various multi-query workloads that simulate dataset exploration and analysis processes.
VOCALExplore: Pay-as-You-Go Video Data Exploration and Model Building
Mar 07, 2023
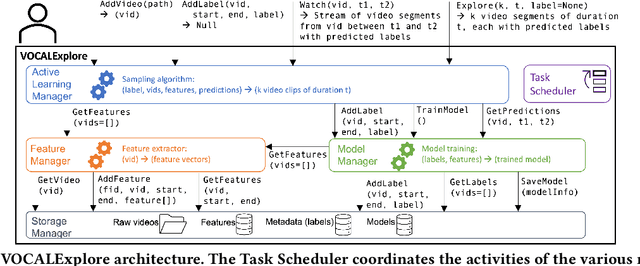


We introduce VOCALExplore, a system designed to support users in building domain-specific models over video datasets. VOCALExplore supports interactive labeling sessions and trains models using user-supplied labels. VOCALExplore maximizes model quality by automatically deciding how to select samples based on observed skew in the collected labels. It also selects the optimal video representations to use when training models by casting feature selection as a rising bandit problem. Finally, VOCALExplore implements optimizations to achieve low latency without sacrificing model performance. We demonstrate that VOCALExplore achieves close to the best possible model quality given candidate acquisition functions and feature extractors, and it does so with low visible latency (~1 second per iteration) and no expensive preprocessing.
Sampling for Deep Learning Model Diagnosis (Technical Report)
Feb 22, 2020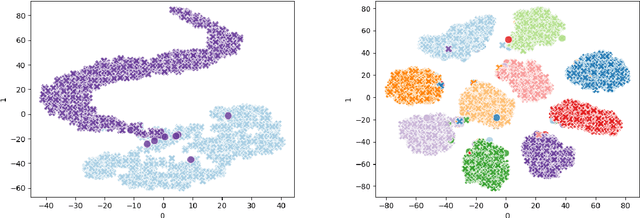
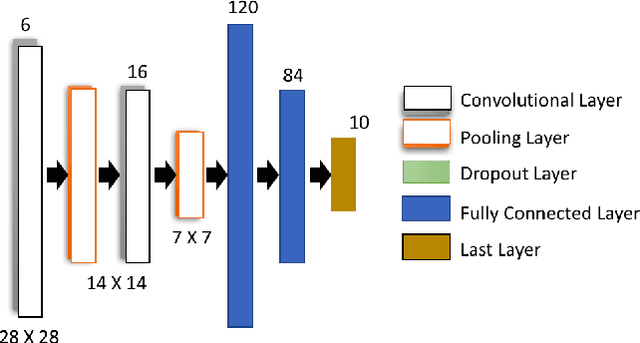
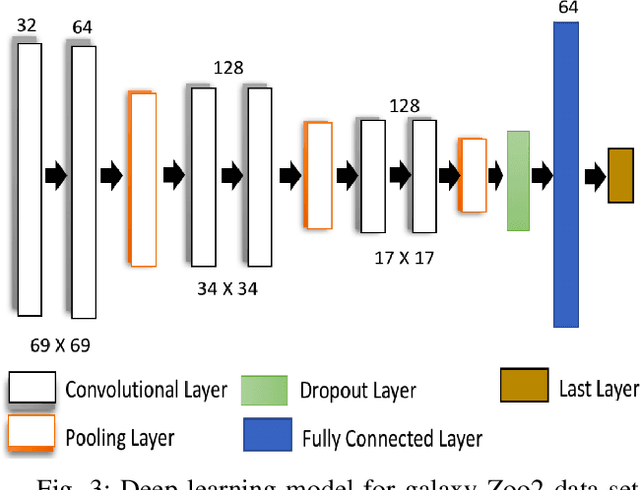
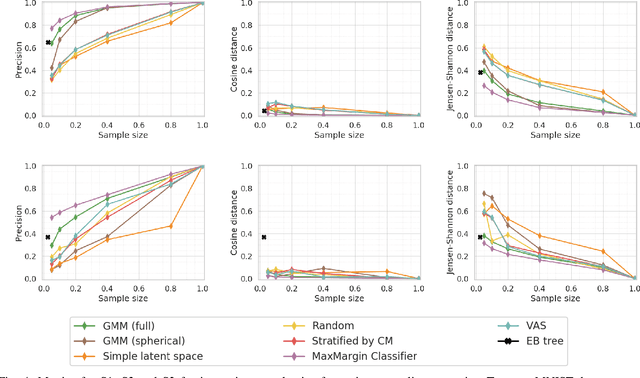
Deep learning (DL) models have achieved paradigm-changing performance in many fields with high dimensional data, such as images, audio, and text. However, the black-box nature of deep neural networks is a barrier not just to adoption in applications such as medical diagnosis, where interpretability is essential, but also impedes diagnosis of under performing models. The task of diagnosing or explaining DL models requires the computation of additional artifacts, such as activation values and gradients. These artifacts are large in volume, and their computation, storage, and querying raise significant data management challenges. In this paper, we articulate DL diagnosis as a data management problem, and we propose a general, yet representative, set of queries to evaluate systems that strive to support this new workload. We further develop a novel data sampling technique that produce approximate but accurate results for these model debugging queries. Our sampling technique utilizes the lower dimension representation learned by the DL model and focuses on model decision boundaries for the data in this lower dimensional space. We evaluate our techniques on one standard computer vision and one scientific data set and demonstrate that our sampling technique outperforms a variety of state-of-the-art alternatives in terms of query accuracy.
Learning State Representations for Query Optimization with Deep Reinforcement Learning
Mar 22, 2018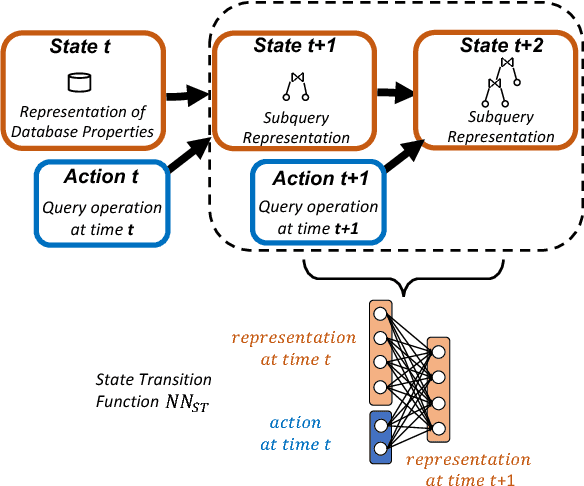
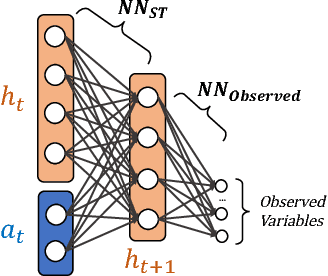
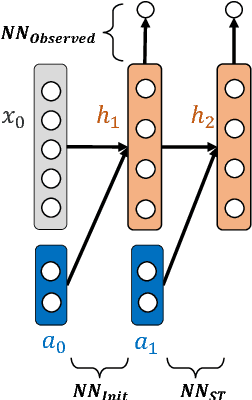
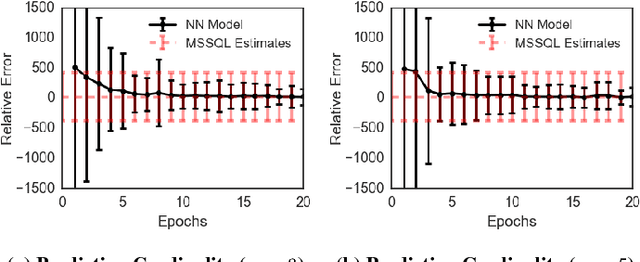
Deep reinforcement learning is quickly changing the field of artificial intelligence. These models are able to capture a high level understanding of their environment, enabling them to learn difficult dynamic tasks in a variety of domains. In the database field, query optimization remains a difficult problem. Our goal in this work is to explore the capabilities of deep reinforcement learning in the context of query optimization. At each state, we build queries incrementally and encode properties of subqueries through a learned representation. The challenge here lies in the formation of the state transition function, which defines how the current subquery state combines with the next query operation (action) to yield the next state. As a first step in this direction, we focus the state representation problem and the formation of the state transition function. We describe our approach and show preliminary results. We further discuss how we can use the state representation to improve query optimization using reinforcement learning.
Believe It or Not: Adding Belief Annotations to Databases
Dec 30, 2009
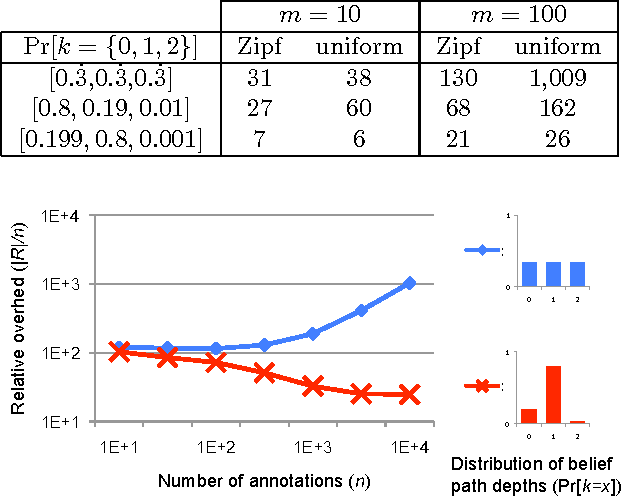
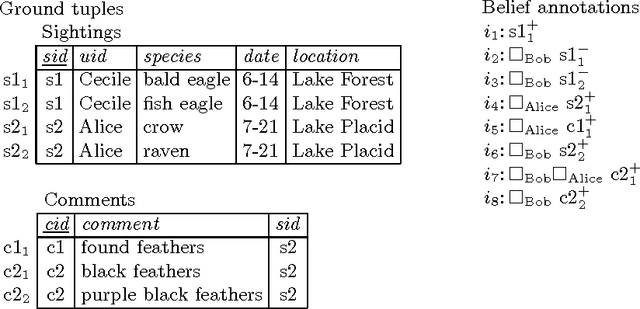
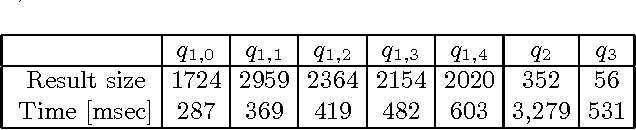
We propose a database model that allows users to annotate data with belief statements. Our motivation comes from scientific database applications where a community of users is working together to assemble, revise, and curate a shared data repository. As the community accumulates knowledge and the database content evolves over time, it may contain conflicting information and members can disagree on the information it should store. For example, Alice may believe that a tuple should be in the database, whereas Bob disagrees. He may also insert the reason why he thinks Alice believes the tuple should be in the database, and explain what he thinks the correct tuple should be instead. We propose a formal model for Belief Databases that interprets users' annotations as belief statements. These annotations can refer both to the base data and to other annotations. We give a formal semantics based on a fragment of multi-agent epistemic logic and define a query language over belief databases. We then prove a key technical result, stating that every belief database can be encoded as a canonical Kripke structure. We use this structure to describe a relational representation of belief databases, and give an algorithm for translating queries over the belief database into standard relational queries. Finally, we report early experimental results with our prototype implementation on synthetic data.
* 17 pages, 10 figures