 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSampling for Deep Learning Model Diagnosis (Technical Report)
Paper and Code
Feb 22, 2020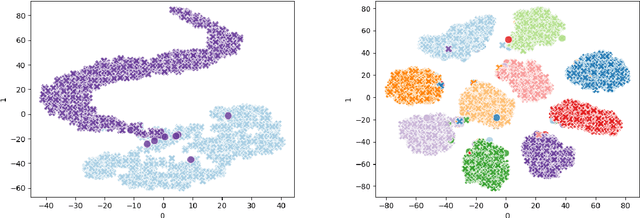
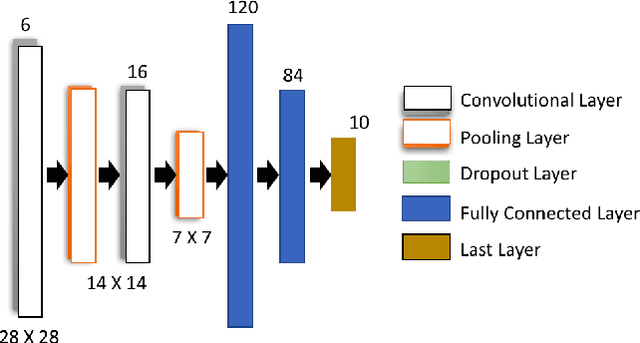
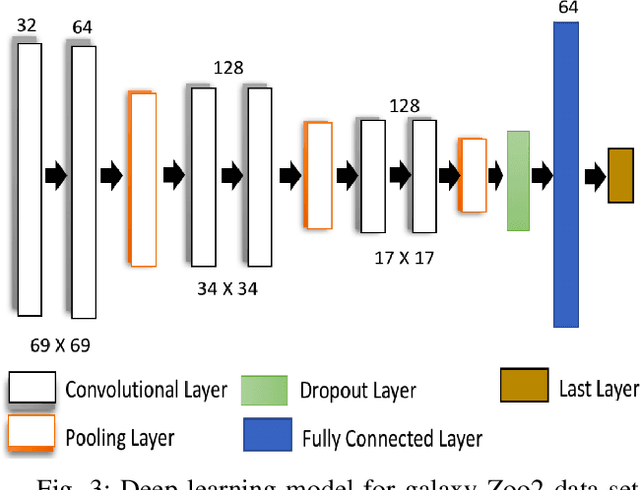
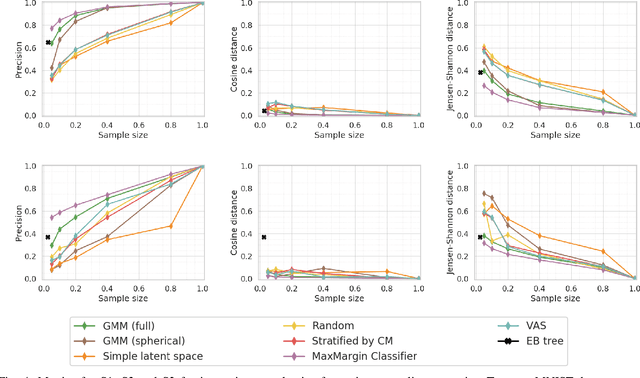
Deep learning (DL) models have achieved paradigm-changing performance in many fields with high dimensional data, such as images, audio, and text. However, the black-box nature of deep neural networks is a barrier not just to adoption in applications such as medical diagnosis, where interpretability is essential, but also impedes diagnosis of under performing models. The task of diagnosing or explaining DL models requires the computation of additional artifacts, such as activation values and gradients. These artifacts are large in volume, and their computation, storage, and querying raise significant data management challenges. In this paper, we articulate DL diagnosis as a data management problem, and we propose a general, yet representative, set of queries to evaluate systems that strive to support this new workload. We further develop a novel data sampling technique that produce approximate but accurate results for these model debugging queries. Our sampling technique utilizes the lower dimension representation learned by the DL model and focuses on model decision boundaries for the data in this lower dimensional space. We evaluate our techniques on one standard computer vision and one scientific data set and demonstrate that our sampling technique outperforms a variety of state-of-the-art alternatives in terms of query accuracy.