 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Model Preference Evaluation with Multiple Weak Evaluators
Oct 14, 2024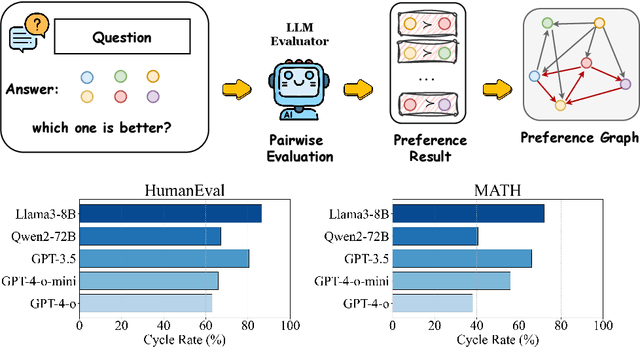
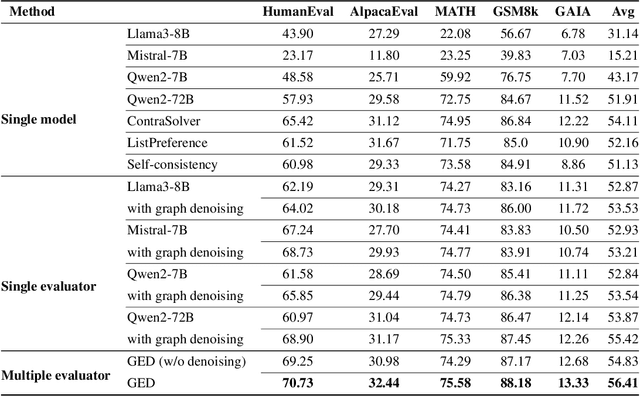
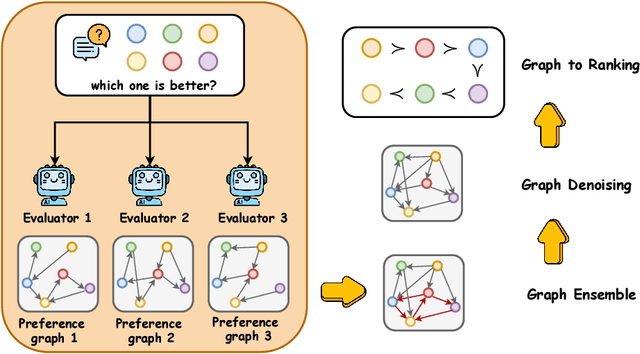
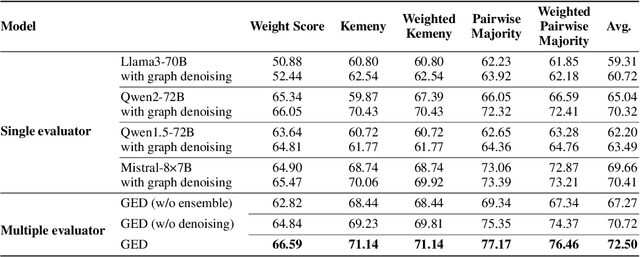
Despite the remarkable success of Large Language Models (LLMs), evaluating their outputs' quality regarding preference remains a critical challenge. Existing works usually leverage a powerful LLM (e.g., GPT4) as the judge for comparing LLMs' output pairwisely, yet such model-based evaluator is vulnerable to conflicting preference, i.e., output A is better than B, B than C, but C than A, causing contradictory evaluation results. To improve model-based preference evaluation, we introduce GED (Preference Graph Ensemble and Denoise), a novel approach that leverages multiple model-based evaluators to construct preference graphs, and then ensemble and denoise these graphs for better, non-contradictory evaluation results. In particular, our method consists of two primary stages: aggregating evaluations into a unified graph and applying a denoising process to eliminate cyclic inconsistencies, ensuring a directed acyclic graph (DAG) structure. We provide theoretical guarantees for our framework, demonstrating its efficacy in recovering the ground truth preference structure. Extensive experiments across ten benchmark datasets show that GED outperforms baseline methods in model ranking, response selection, and model alignment tasks. Notably, GED combines weaker evaluators like Llama3-8B, Mistral-7B, and Qwen2-7B to surpass the performance of stronger evaluators like Qwen2-72B, highlighting its ability to enhance evaluation reliability and improve model performance.
Found in the Middle: Calibrating Positional Attention Bias Improves Long Context Utilization
Jun 23, 2024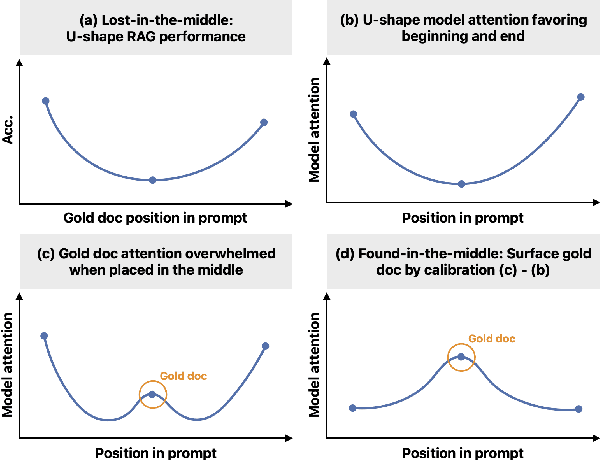


Large language models (LLMs), even when specifically trained to process long input contexts, struggle to capture relevant information located in the middle of their input. This phenomenon has been known as the lost-in-the-middle problem. In this work, we make three contributions. First, we set out to understand the factors that cause this phenomenon. In doing so, we establish a connection between lost-in-the-middle to LLMs' intrinsic attention bias: LLMs exhibit a U-shaped attention bias where the tokens at the beginning and at the end of its input receive higher attention, regardless of their relevance. Second, we mitigate this positional bias through a calibration mechanism, found-in-the-middle, that allows the model to attend to contexts faithfully according to their relevance, even though when they are in the middle. Third, we show found-in-the-middle not only achieves better performance in locating relevant information within a long context, but also eventually leads to improved retrieval-augmented generation (RAG) performance across various tasks, outperforming existing methods by up to 15 percentage points. These findings open up future directions in understanding LLM attention bias and its potential consequences.
Tool Documentation Enables Zero-Shot Tool-Usage with Large Language Models
Aug 01, 2023Today, large language models (LLMs) are taught to use new tools by providing a few demonstrations of the tool's usage. Unfortunately, demonstrations are hard to acquire, and can result in undesirable biased usage if the wrong demonstration is chosen. Even in the rare scenario that demonstrations are readily available, there is no principled selection protocol to determine how many and which ones to provide. As tasks grow more complex, the selection search grows combinatorially and invariably becomes intractable. Our work provides an alternative to demonstrations: tool documentation. We advocate the use of tool documentation, descriptions for the individual tool usage, over demonstrations. We substantiate our claim through three main empirical findings on 6 tasks across both vision and language modalities. First, on existing benchmarks, zero-shot prompts with only tool documentation are sufficient for eliciting proper tool usage, achieving performance on par with few-shot prompts. Second, on a newly collected realistic tool-use dataset with hundreds of available tool APIs, we show that tool documentation is significantly more valuable than demonstrations, with zero-shot documentation significantly outperforming few-shot without documentation. Third, we highlight the benefits of tool documentations by tackling image generation and video tracking using just-released unseen state-of-the-art models as tools. Finally, we highlight the possibility of using tool documentation to automatically enable new applications: by using nothing more than the documentation of GroundingDino, Stable Diffusion, XMem, and SAM, LLMs can re-invent the functionalities of the just-released Grounded-SAM and Track Anything models.
Large Language Model as Attributed Training Data Generator: A Tale of Diversity and Bias
Jun 28, 2023Large language models (LLMs) have been recently leveraged as training data generators for various natural language processing (NLP) tasks. While previous research has explored different approaches to training models using generated data, they generally rely on simple class-conditional prompts, which may limit the diversity of the generated data and inherit systematic biases of LLM. Thus, we investigate training data generation with diversely attributed prompts (e.g., specifying attributes like length and style), which have the potential to yield diverse and attributed generated data. Our investigation focuses on datasets with high cardinality and diverse domains, wherein we demonstrate that attributed prompts outperform simple class-conditional prompts in terms of the resulting model's performance. Additionally, we present a comprehensive empirical study on data generation encompassing vital aspects like bias, diversity, and efficiency, and highlight three key observations: firstly, synthetic datasets generated by simple prompts exhibit significant biases, such as regional bias; secondly, attribute diversity plays a pivotal role in enhancing model performance; lastly, attributed prompts achieve the performance of simple class-conditional prompts while utilizing only 5\% of the querying cost of ChatGPT associated with the latter. We release the generated dataset and used prompts to facilitate future research. The data and code will be available on \url{https://github.com/yueyu1030/AttrPrompt}.
On the Trade-off of Intra-/Inter-class Diversity for Supervised Pre-training
May 20, 2023



Pre-training datasets are critical for building state-of-the-art machine learning models, motivating rigorous study on their impact on downstream tasks. In this work, we study the impact of the trade-off between the intra-class diversity (the number of samples per class) and the inter-class diversity (the number of classes) of a supervised pre-training dataset. Empirically, we found that with the size of the pre-training dataset fixed, the best downstream performance comes with a balance on the intra-/inter-class diversity. To understand the underlying mechanism, we show theoretically that the downstream performance depends monotonically on both types of diversity. Notably, our theory reveals that the optimal class-to-sample ratio (#classes / #samples per class) is invariant to the size of the pre-training dataset, which motivates an application of predicting the optimal number of pre-training classes. We demonstrate the effectiveness of this application by an improvement of around 2 points on the downstream tasks when using ImageNet as the pre-training dataset.
DataComp: In search of the next generation of multimodal datasets
May 03, 2023Large multimodal datasets have been instrumental in recent breakthroughs such as CLIP, Stable Diffusion, and GPT-4. At the same time, datasets rarely receive the same research attention as model architectures or training algorithms. To address this shortcoming in the machine learning ecosystem, we introduce DataComp, a benchmark where the training code is fixed and researchers innovate by proposing new training sets. We provide a testbed for dataset experiments centered around a new candidate pool of 12.8B image-text pairs from Common Crawl. Participants in our benchmark design new filtering techniques or curate new data sources and then evaluate their new dataset by running our standardized CLIP training code and testing on 38 downstream test sets. Our benchmark consists of multiple scales, with four candidate pool sizes and associated compute budgets ranging from 12.8M to 12.8B samples seen during training. This multi-scale design facilitates the study of scaling trends and makes the benchmark accessible to researchers with varying resources. Our baseline experiments show that the DataComp workflow is a promising way of improving multimodal datasets. We introduce DataComp-1B, a dataset created by applying a simple filtering algorithm to the 12.8B candidate pool. The resulting 1.4B subset enables training a CLIP ViT-L/14 from scratch to 79.2% zero-shot accuracy on ImageNet. Our new ViT-L/14 model outperforms a larger ViT-g/14 trained on LAION-2B by 0.7 percentage points while requiring 9x less training compute. We also outperform OpenAI's CLIP ViT-L/14 by 3.7 percentage points, which is trained with the same compute budget as our model. These gains highlight the potential for improving model performance by carefully curating training sets. We view DataComp-1B as only the first step and hope that DataComp paves the way toward the next generation of multimodal datasets.
Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes
May 03, 2023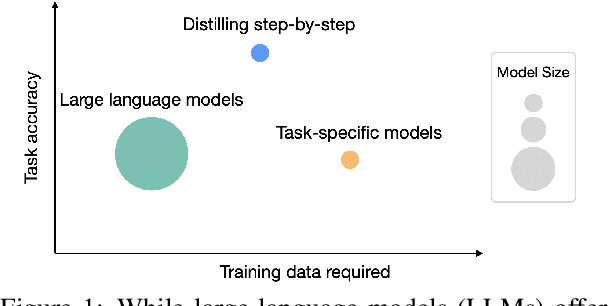
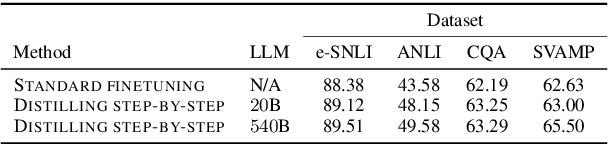
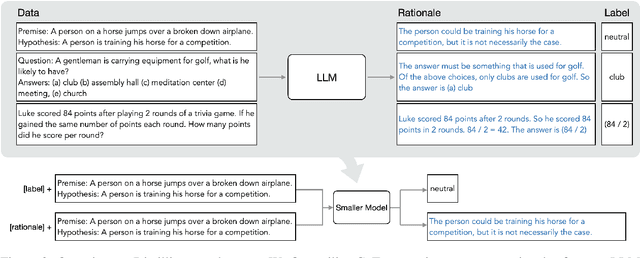

Deploying large language models (LLMs) is challenging because they are memory inefficient and compute-intensive for practical applications. In reaction, researchers train smaller task-specific models by either finetuning with human labels or distilling using LLM-generated labels. However, finetuning and distillation require large amounts of training data to achieve comparable performance to LLMs. We introduce Distilling step-by-step, a new mechanism that (a) trains smaller models that outperform LLMs, and (b) achieves so by leveraging less training data needed by finetuning or distillation. Our method extracts LLM rationales as additional supervision for small models within a multi-task training framework. We present three findings across 4 NLP benchmarks: First, compared to both finetuning and distillation, our mechanism achieves better performance with much fewer labeled/unlabeled training examples. Second, compared to LLMs, we achieve better performance using substantially smaller model sizes. Third, we reduce both the model size and the amount of data required to outperform LLMs; our 770M T5 model outperforms the 540B PaLM model using only 80% of available data on a benchmark task.
MaskSearch: Querying Image Masks at Scale
May 03, 2023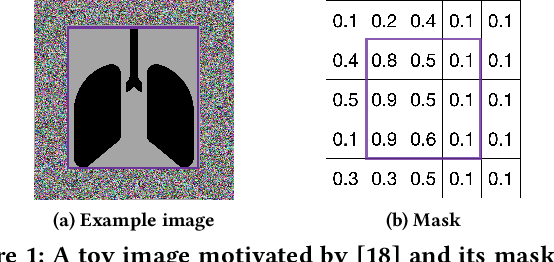


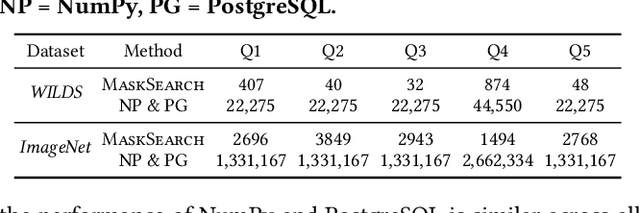
Machine learning tasks over image databases often generate masks that annotate image content (e.g., saliency maps, segmentation maps) and enable a variety of applications (e.g., determine if a model is learning spurious correlations or if an image was maliciously modified to mislead a model). While queries that retrieve examples based on mask properties are valuable to practitioners, existing systems do not support such queries efficiently. In this paper, we formalize the problem and propose a system, MaskSearch, that focuses on accelerating queries over databases of image masks. MaskSearch leverages a novel indexing technique and an efficient filter-verification query execution framework. Experiments on real-world datasets with our prototype show that MaskSearch, using indexes approximately 5% the size of the data, accelerates individual queries by up to two orders of magnitude and consistently outperforms existing methods on various multi-query workloads that simulate dataset exploration and analysis processes.
Leveraging Instance Features for Label Aggregation in Programmatic Weak Supervision
Oct 09, 2022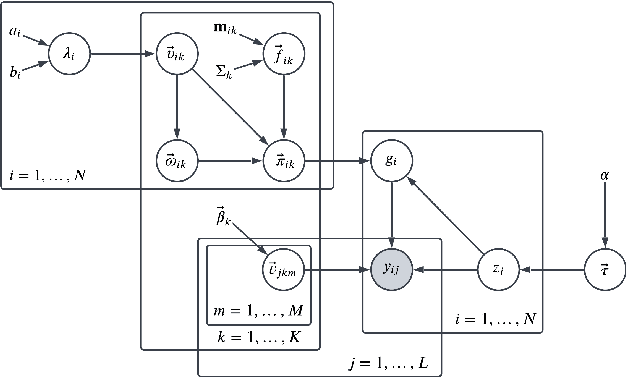

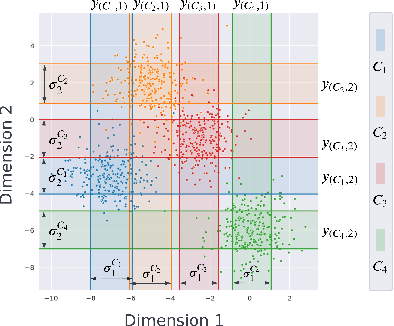
Programmatic Weak Supervision (PWS) has emerged as a widespread paradigm to synthesize training labels efficiently. The core component of PWS is the label model, which infers true labels by aggregating the outputs of multiple noisy supervision sources abstracted as labeling functions (LFs). Existing statistical label models typically rely only on the outputs of LF, ignoring the instance features when modeling the underlying generative process. In this paper, we attempt to incorporate the instance features into a statistical label model via the proposed FABLE. In particular, it is built on a mixture of Bayesian label models, each corresponding to a global pattern of correlation, and the coefficients of the mixture components are predicted by a Gaussian Process classifier based on instance features. We adopt an auxiliary variable-based variational inference algorithm to tackle the non-conjugate issue between the Gaussian Process and Bayesian label models. Extensive empirical comparison on eleven benchmark datasets sees FABLE achieving the highest averaged performance across nine baselines.
Binary Classification with Positive Labeling Sources
Aug 02, 2022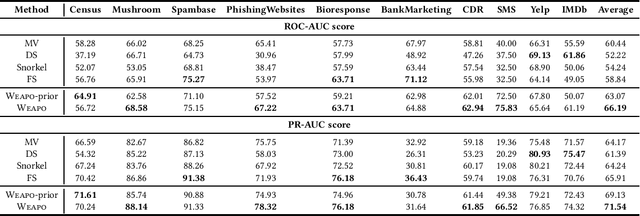
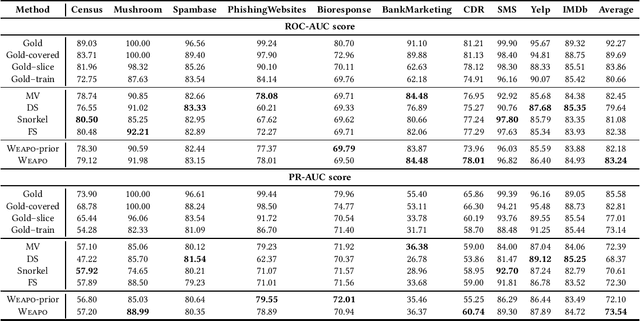
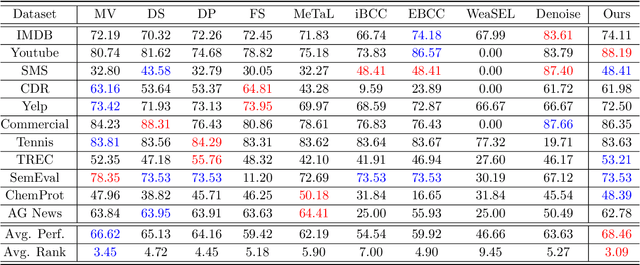
To create a large amount of training labels for machine learning models effectively and efficiently, researchers have turned to Weak Supervision (WS), which uses programmatic labeling sources rather than manual annotation. Existing works of WS for binary classification typically assume the presence of labeling sources that are able to assign both positive and negative labels to data in roughly balanced proportions. However, for many tasks of interest where there is a minority positive class, negative examples could be too diverse for developers to generate indicative labeling sources. Thus, in this work, we study the application of WS on binary classification tasks with positive labeling sources only. We propose WEAPO, a simple yet competitive WS method for producing training labels without negative labeling sources. On 10 benchmark datasets, we show WEAPO achieves the highest averaged performance in terms of both the quality of synthesized labels and the performance of the final classifier supervised with these labels. We incorporated the implementation of \method into WRENCH, an existing benchmarking platform.