 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFound in the Middle: Calibrating Positional Attention Bias Improves Long Context Utilization
Paper and Code
Jun 23, 2024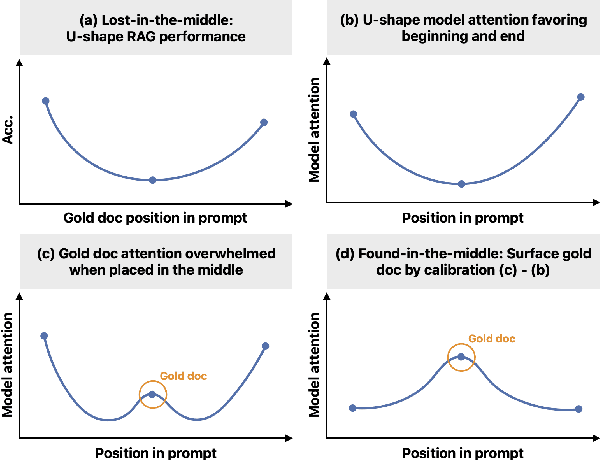


Large language models (LLMs), even when specifically trained to process long input contexts, struggle to capture relevant information located in the middle of their input. This phenomenon has been known as the lost-in-the-middle problem. In this work, we make three contributions. First, we set out to understand the factors that cause this phenomenon. In doing so, we establish a connection between lost-in-the-middle to LLMs' intrinsic attention bias: LLMs exhibit a U-shaped attention bias where the tokens at the beginning and at the end of its input receive higher attention, regardless of their relevance. Second, we mitigate this positional bias through a calibration mechanism, found-in-the-middle, that allows the model to attend to contexts faithfully according to their relevance, even though when they are in the middle. Third, we show found-in-the-middle not only achieves better performance in locating relevant information within a long context, but also eventually leads to improved retrieval-augmented generation (RAG) performance across various tasks, outperforming existing methods by up to 15 percentage points. These findings open up future directions in understanding LLM attention bias and its potential consequences.