 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTableRAG: Million-Token Table Understanding with Language Models
Oct 07, 2024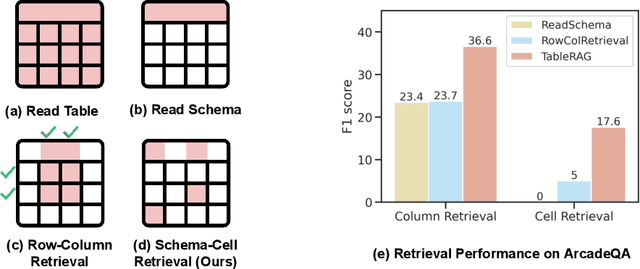
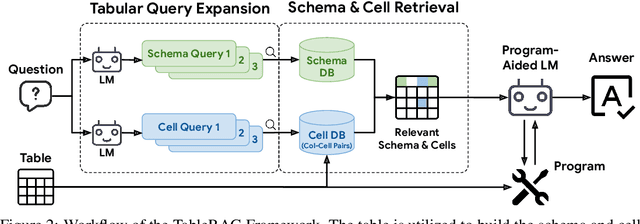
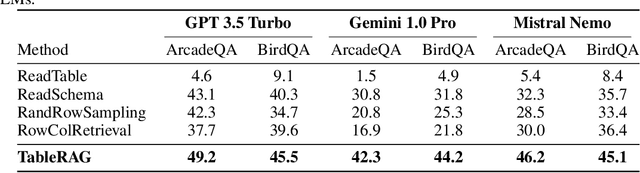
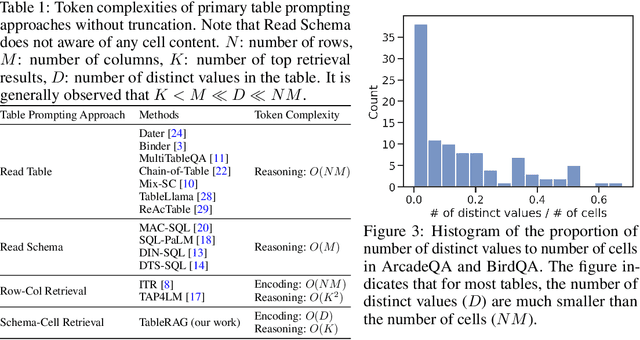
Recent advancements in language models (LMs) have notably enhanced their ability to reason with tabular data, primarily through program-aided mechanisms that manipulate and analyze tables. However, these methods often require the entire table as input, leading to scalability challenges due to the positional bias or context length constraints. In response to these challenges, we introduce TableRAG, a Retrieval-Augmented Generation (RAG) framework specifically designed for LM-based table understanding. TableRAG leverages query expansion combined with schema and cell retrieval to pinpoint crucial information before providing it to the LMs. This enables more efficient data encoding and precise retrieval, significantly reducing prompt lengths and mitigating information loss. We have developed two new million-token benchmarks from the Arcade and BIRD-SQL datasets to thoroughly evaluate TableRAG's effectiveness at scale. Our results demonstrate that TableRAG's retrieval design achieves the highest retrieval quality, leading to the new state-of-the-art performance on large-scale table understanding.
Tool Documentation Enables Zero-Shot Tool-Usage with Large Language Models
Aug 01, 2023Today, large language models (LLMs) are taught to use new tools by providing a few demonstrations of the tool's usage. Unfortunately, demonstrations are hard to acquire, and can result in undesirable biased usage if the wrong demonstration is chosen. Even in the rare scenario that demonstrations are readily available, there is no principled selection protocol to determine how many and which ones to provide. As tasks grow more complex, the selection search grows combinatorially and invariably becomes intractable. Our work provides an alternative to demonstrations: tool documentation. We advocate the use of tool documentation, descriptions for the individual tool usage, over demonstrations. We substantiate our claim through three main empirical findings on 6 tasks across both vision and language modalities. First, on existing benchmarks, zero-shot prompts with only tool documentation are sufficient for eliciting proper tool usage, achieving performance on par with few-shot prompts. Second, on a newly collected realistic tool-use dataset with hundreds of available tool APIs, we show that tool documentation is significantly more valuable than demonstrations, with zero-shot documentation significantly outperforming few-shot without documentation. Third, we highlight the benefits of tool documentations by tackling image generation and video tracking using just-released unseen state-of-the-art models as tools. Finally, we highlight the possibility of using tool documentation to automatically enable new applications: by using nothing more than the documentation of GroundingDino, Stable Diffusion, XMem, and SAM, LLMs can re-invent the functionalities of the just-released Grounded-SAM and Track Anything models.
Score-based Conditional Generation with Fewer Labeled Data by Self-calibrating Classifier Guidance
Jul 09, 2023Score-based Generative Models (SGMs) are a popular family of deep generative models that achieves leading image generation quality. Earlier studies have extended SGMs to tackle class-conditional generation by coupling an unconditional SGM with the guidance of a trained classifier. Nevertheless, such classifier-guided SGMs do not always achieve accurate conditional generation, especially when trained with fewer labeled data. We argue that the issue is rooted in unreliable gradients of the classifier and the inability to fully utilize unlabeled data during training. We then propose to improve classifier-guided SGMs by letting the classifier calibrate itself. Our key idea is to use principles from energy-based models to convert the classifier as another view of the unconditional SGM. Then, existing loss for the unconditional SGM can be adopted to calibrate the classifier using both labeled and unlabeled data. Empirical results validate that the proposed approach significantly improves the conditional generation quality across different percentages of labeled data. The improved performance makes the proposed approach consistently superior to other conditional SGMs when using fewer labeled data. The results confirm the potential of the proposed approach for generative modeling with limited labeled data.
Linear Classifier: An Often-Forgotten Baseline for Text Classification
Jun 12, 2023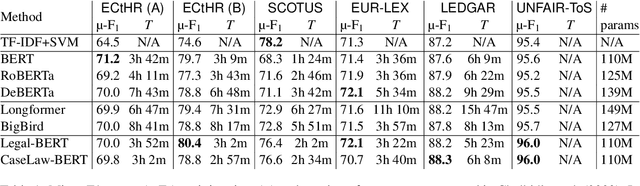
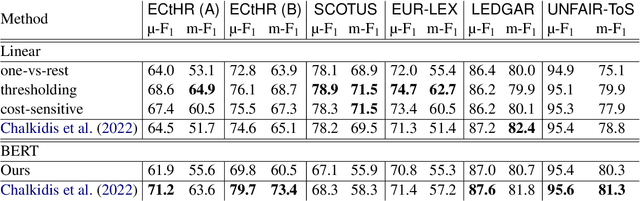
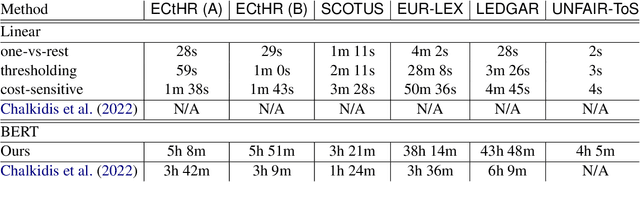

Large-scale pre-trained language models such as BERT are popular solutions for text classification. Due to the superior performance of these advanced methods, nowadays, people often directly train them for a few epochs and deploy the obtained model. In this opinion paper, we point out that this way may only sometimes get satisfactory results. We argue the importance of running a simple baseline like linear classifiers on bag-of-words features along with advanced methods. First, for many text data, linear methods show competitive performance, high efficiency, and robustness. Second, advanced models such as BERT may only achieve the best results if properly applied. Simple baselines help to confirm whether the results of advanced models are acceptable. Our experimental results fully support these points.
TSMixer: An all-MLP Architecture for Time Series Forecasting
Mar 10, 2023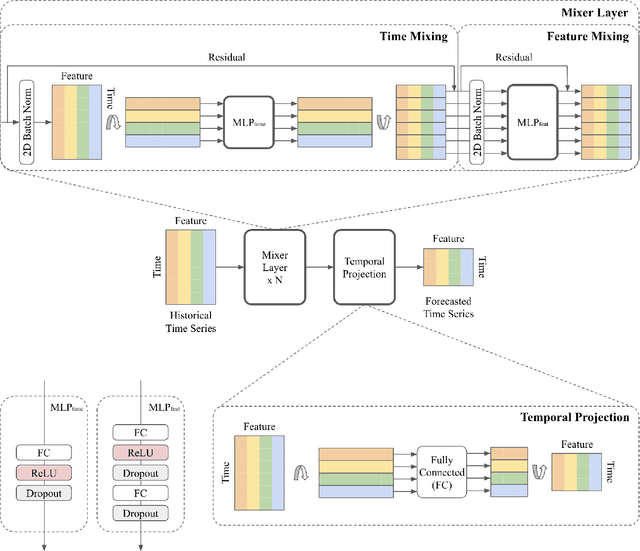
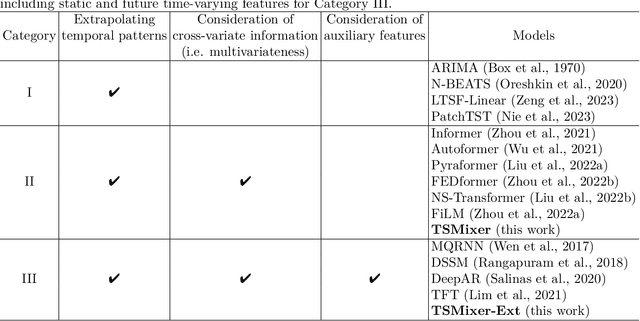
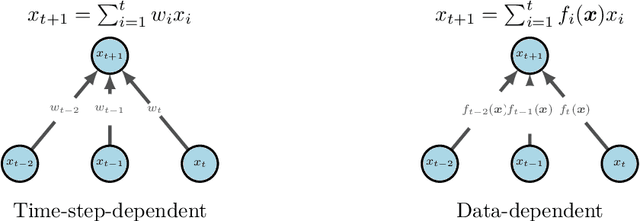
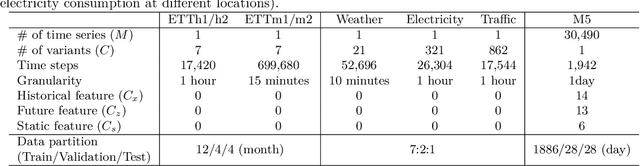
Real-world time-series datasets are often multivariate with complex dynamics. Commonly-used high capacity architectures like recurrent- or attention-based sequential models have become popular. However, recent work demonstrates that simple univariate linear models can outperform those deep alternatives. In this paper, we investigate the capabilities of linear models for time-series forecasting and present Time-Series Mixer (TSMixer), an architecture designed by stacking multi-layer perceptrons (MLPs). TSMixer is based on mixing operations along time and feature dimensions to extract information efficiently. On popular academic benchmarks, the simple-to-implement TSMixer is comparable to specialized state-of-the-art models that leverage the inductive biases of specific benchmarks. On the challenging and large scale M5 benchmark, a real-world retail dataset, TSMixer demonstrates superior performance compared to the state-of-the-art alternatives. Our results underline the importance of efficiently utilizing cross-variate and auxiliary information for improving the performance of time series forecasting. The design paradigms utilized in TSMixer are expected to open new horizons for deep learning-based time series forecasting.
Improving Model Compatibility of Generative Adversarial Networks by Boundary Calibration
Nov 03, 2021


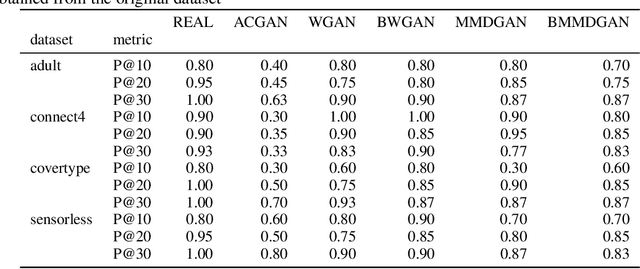
Generative Adversarial Networks (GANs) is a powerful family of models that learn an underlying distribution to generate synthetic data. Many existing studies of GANs focus on improving the realness of the generated image data for visual applications, and few of them concern about improving the quality of the generated data for training other classifiers -- a task known as the model compatibility problem. As a consequence, existing GANs often prefer generating `easier' synthetic data that are far from the boundaries of the classifiers, and refrain from generating near-boundary data, which are known to play an important roles in training the classifiers. To improve GAN in terms of model compatibility, we propose Boundary-Calibration GANs (BCGANs), which leverage the boundary information from a set of pre-trained classifiers using the original data. In particular, we introduce an auxiliary Boundary-Calibration loss (BC-loss) into the generator of GAN to match the statistics between the posterior distributions of original data and generated data with respect to the boundaries of the pre-trained classifiers. The BC-loss is provably unbiased and can be easily coupled with different GAN variants to improve their model compatibility. Experimental results demonstrate that BCGANs not only generate realistic images like original GANs but also achieves superior model compatibility than the original GANs.
A Unified View of cGANs with and without Classifiers
Nov 01, 2021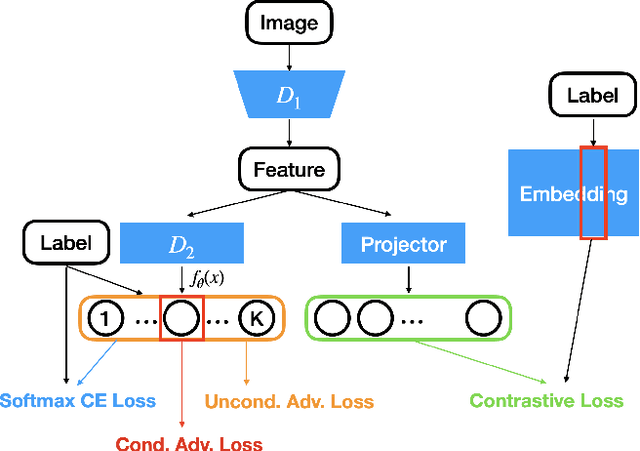


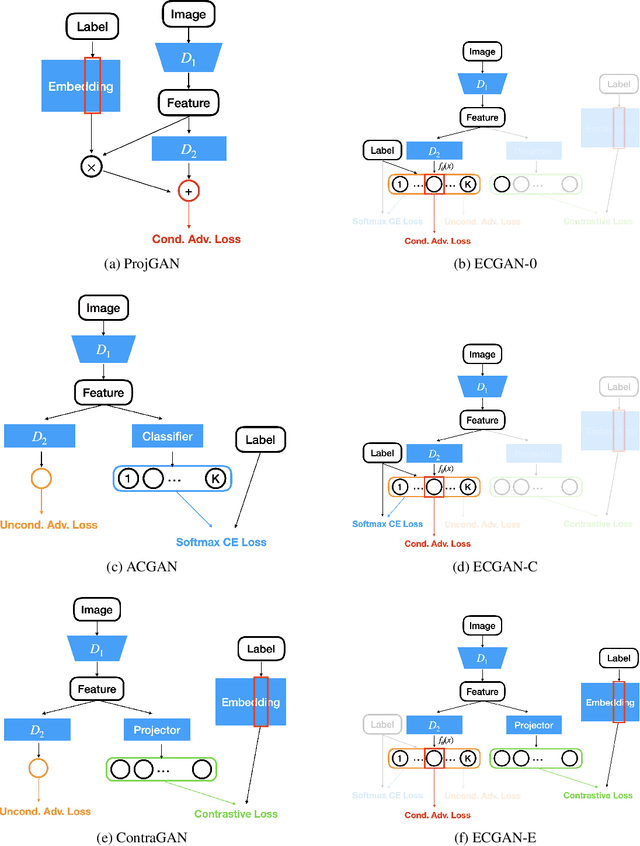
Conditional Generative Adversarial Networks (cGANs) are implicit generative models which allow to sample from class-conditional distributions. Existing cGANs are based on a wide range of different discriminator designs and training objectives. One popular design in earlier works is to include a classifier during training with the assumption that good classifiers can help eliminate samples generated with wrong classes. Nevertheless, including classifiers in cGANs often comes with a side effect of only generating easy-to-classify samples. Recently, some representative cGANs avoid the shortcoming and reach state-of-the-art performance without having classifiers. Somehow it remains unanswered whether the classifiers can be resurrected to design better cGANs. In this work, we demonstrate that classifiers can be properly leveraged to improve cGANs. We start by using the decomposition of the joint probability distribution to connect the goals of cGANs and classification as a unified framework. The framework, along with a classic energy model to parameterize distributions, justifies the use of classifiers for cGANs in a principled manner. It explains several popular cGAN variants, such as ACGAN, ProjGAN, and ContraGAN, as special cases with different levels of approximations, which provides a unified view and brings new insights to understanding cGANs. Experimental results demonstrate that the design inspired by the proposed framework outperforms state-of-the-art cGANs on multiple benchmark datasets, especially on the most challenging ImageNet. The code is available at https://github.com/sian-chen/PyTorch-ECGAN.
Parameter Selection: Why We Should Pay More Attention to It
Jul 08, 2021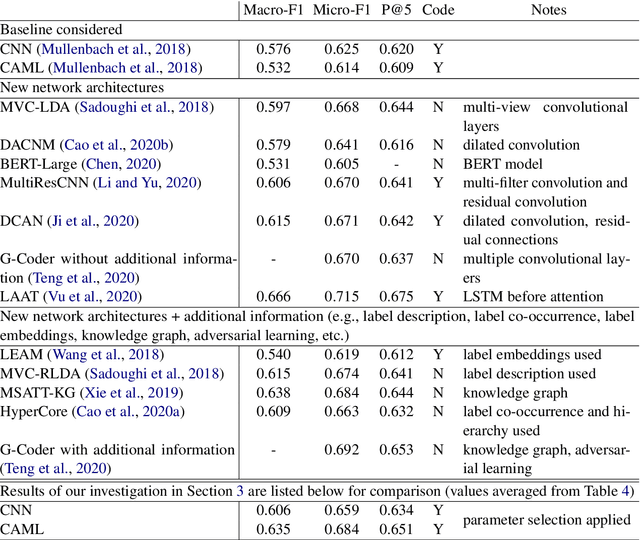
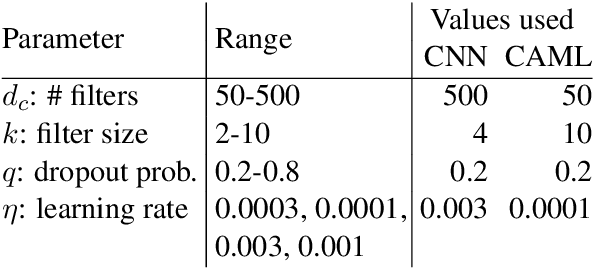
The importance of parameter selection in supervised learning is well known. However, due to the many parameter combinations, an incomplete or an insufficient procedure is often applied. This situation may cause misleading or confusing conclusions. In this opinion paper, through an intriguing example we point out that the seriousness goes beyond what is generally recognized. In the topic of multi-label classification for medical code prediction, one influential paper conducted a proper parameter selection on a set, but when moving to a subset of frequently occurring labels, the authors used the same parameters without a separate tuning. The set of frequent labels became a popular benchmark in subsequent studies, which kept pushing the state of the art. However, we discovered that most of the results in these studies cannot surpass the approach in the original paper if a parameter tuning had been conducted at the time. Thus it is unclear how much progress the subsequent developments have actually brought. The lesson clearly indicates that without enough attention on parameter selection, the research progress in our field can be uncertain or even illusive.
Active Deep Q-learning with Demonstration
Dec 06, 2018
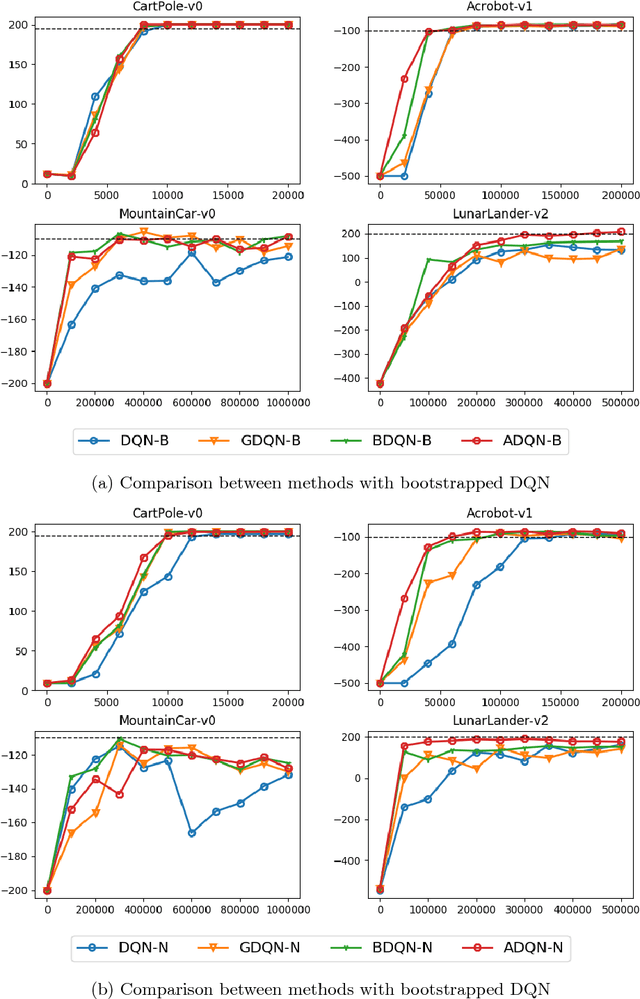
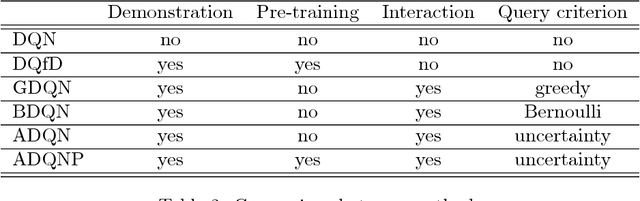
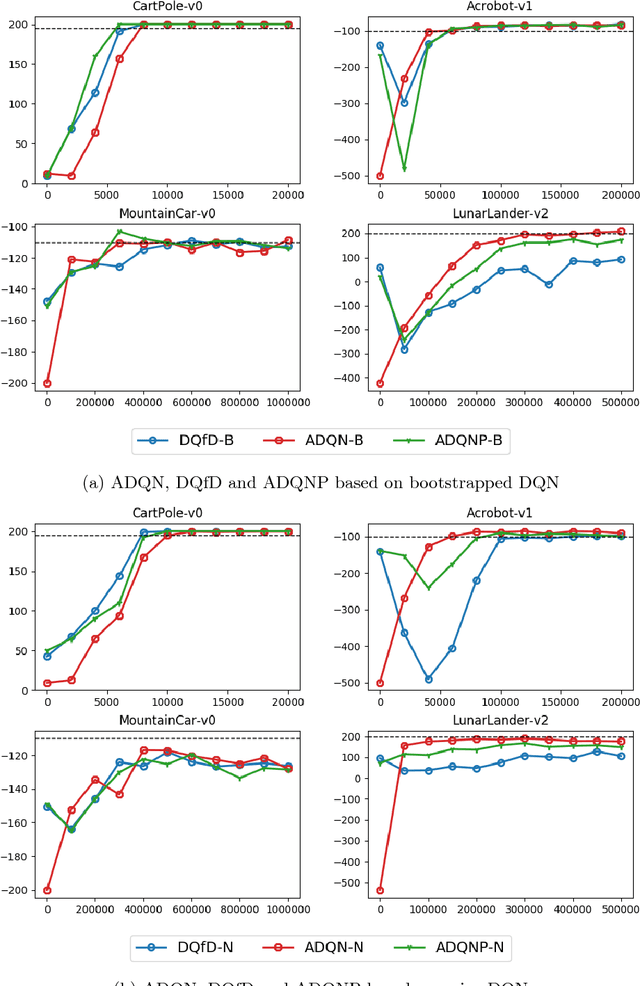
Recent research has shown that although Reinforcement Learning (RL) can benefit from expert demonstration, it usually takes considerable efforts to obtain enough demonstration. The efforts prevent training decent RL agents with expert demonstration in practice. In this work, we propose Active Reinforcement Learning with Demonstration (ARLD), a new framework to streamline RL in terms of demonstration efforts by allowing the RL agent to query for demonstration actively during training. Under the framework, we propose Active Deep Q-Network, a novel query strategy which adapts to the dynamically-changing distributions during the RL training process by estimating the uncertainty of recent states. The expert demonstration data within Active DQN are then utilized by optimizing supervised max-margin loss in addition to temporal difference loss within usual DQN training. We propose two methods of estimating the uncertainty based on two state-of-the-art DQN models, namely the divergence of bootstrapped DQN and the variance of noisy DQN. The empirical results validate that both methods not only learn faster than other passive expert demonstration methods with the same amount of demonstration and but also reach super-expert level of performance across four different tasks.
libact: Pool-based Active Learning in Python
Oct 01, 2017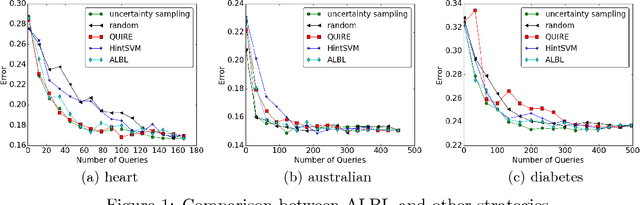
libact is a Python package designed to make active learning easier for general users. The package not only implements several popular active learning strategies, but also features the active-learning-by-learning meta-algorithm that assists the users to automatically select the best strategy on the fly. Furthermore, the package provides a unified interface for implementing more strategies, models and application-specific labelers. The package is open-source on Github, and can be easily installed from Python Package Index repository.