 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEditing the Mind of Giants: An In-Depth Exploration of Pitfalls of Knowledge Editing in Large Language Models
Jun 03, 2024Knowledge editing is a rising technique for efficiently updating factual knowledge in Large Language Models (LLMs) with minimal alteration of parameters. However, recent studies have identified concerning side effects, such as knowledge distortion and the deterioration of general abilities, that have emerged after editing. This survey presents a comprehensive study of these side effects, providing a unified view of the challenges associated with knowledge editing in LLMs. We discuss related works and summarize potential research directions to overcome these limitations. Our work highlights the limitations of current knowledge editing methods, emphasizing the need for deeper understanding of inner knowledge structures of LLMs and improved knowledge editing methods. To foster future research, we have released the complementary materials such as paper collection publicly at https://github.com/MiuLab/EditLLM-Survey
Prompting and Adapter Tuning for Self-supervised Encoder-Decoder Speech Model
Oct 04, 2023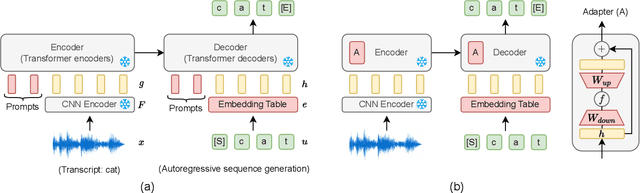
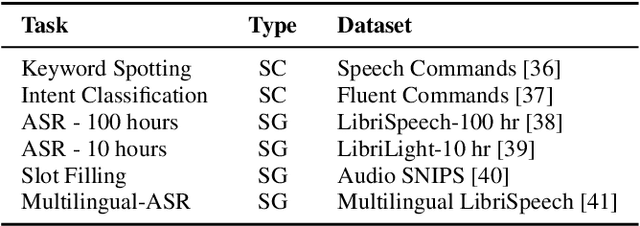
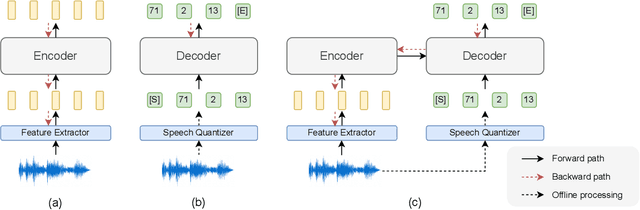

Prompting and adapter tuning have emerged as efficient alternatives to fine-tuning (FT) methods. However, existing studies on speech prompting focused on classification tasks and failed on more complex sequence generation tasks. Besides, adapter tuning is primarily applied with a focus on encoder-only self-supervised models. Our experiments show that prompting on Wav2Seq, a self-supervised encoder-decoder model, surpasses previous works in sequence generation tasks. It achieves a remarkable 53% relative improvement in word error rate for ASR and a 27% in F1 score for slot filling. Additionally, prompting competes with the FT method in the low-resource scenario. Moreover, we show the transferability of prompting and adapter tuning on Wav2Seq in cross-lingual ASR. When limited trainable parameters are involved, prompting and adapter tuning consistently outperform conventional FT across 7 languages. Notably, in the low-resource scenario, prompting consistently outperforms adapter tuning.
Score-based Conditional Generation with Fewer Labeled Data by Self-calibrating Classifier Guidance
Jul 09, 2023Score-based Generative Models (SGMs) are a popular family of deep generative models that achieves leading image generation quality. Earlier studies have extended SGMs to tackle class-conditional generation by coupling an unconditional SGM with the guidance of a trained classifier. Nevertheless, such classifier-guided SGMs do not always achieve accurate conditional generation, especially when trained with fewer labeled data. We argue that the issue is rooted in unreliable gradients of the classifier and the inability to fully utilize unlabeled data during training. We then propose to improve classifier-guided SGMs by letting the classifier calibrate itself. Our key idea is to use principles from energy-based models to convert the classifier as another view of the unconditional SGM. Then, existing loss for the unconditional SGM can be adopted to calibrate the classifier using both labeled and unlabeled data. Empirical results validate that the proposed approach significantly improves the conditional generation quality across different percentages of labeled data. The improved performance makes the proposed approach consistently superior to other conditional SGMs when using fewer labeled data. The results confirm the potential of the proposed approach for generative modeling with limited labeled data.