 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn Pursuit of Pixel Supervision for Visual Pre-training
Dec 17, 2025At the most basic level, pixels are the source of the visual information through which we perceive the world. Pixels contain information at all levels, ranging from low-level attributes to high-level concepts. Autoencoders represent a classical and long-standing paradigm for learning representations from pixels or other raw inputs. In this work, we demonstrate that autoencoder-based self-supervised learning remains competitive today and can produce strong representations for downstream tasks, while remaining simple, stable, and efficient. Our model, codenamed "Pixio", is an enhanced masked autoencoder (MAE) with more challenging pre-training tasks and more capable architectures. The model is trained on 2B web-crawled images with a self-curation strategy with minimal human curation. Pixio performs competitively across a wide range of downstream tasks in the wild, including monocular depth estimation (e.g., Depth Anything), feed-forward 3D reconstruction (i.e., MapAnything), semantic segmentation, and robot learning, outperforming or matching DINOv3 trained at similar scales. Our results suggest that pixel-space self-supervised learning can serve as a promising alternative and a complement to latent-space approaches.
Demystifying Synthetic Data in LLM Pre-training: A Systematic Study of Scaling Laws, Benefits, and Pitfalls
Oct 02, 2025Training data plays a crucial role in Large Language Models (LLM) scaling, yet high quality data is of limited supply. Synthetic data techniques offer a potential path toward sidestepping these limitations. We conduct a large-scale empirical investigation (>1000 LLMs with >100k GPU hours) using a unified protocol and scaling laws, comparing natural web data, diverse synthetic types (rephrased text, generated textbooks), and mixtures of natural and synthetic data. Specifically, we found pre-training on rephrased synthetic data \textit{alone} is not faster than pre-training on natural web texts; while pre-training on 1/3 rephrased synthetic data mixed with 2/3 natural web texts can speed up 5-10x (to reach the same validation loss) at larger data budgets. Pre-training on textbook-style synthetic data \textit{alone} results in notably higher loss on many downstream domains especially at small data budgets. "Good" ratios of synthetic data in training data mixtures depend on the model size and data budget, empirically converging to ~30% for rephrased synthetic data. Larger generator models do not necessarily yield better pre-training data than ~8B-param models. These results contribute mixed evidence on "model collapse" during large-scale single-round (n=1) model training on synthetic data--training on rephrased synthetic data shows no degradation in performance in foreseeable scales whereas training on mixtures of textbook-style pure-generated synthetic data shows patterns predicted by "model collapse". Our work demystifies synthetic data in pre-training, validates its conditional benefits, and offers practical guidance.
MetaCLIP 2: A Worldwide Scaling Recipe
Jul 29, 2025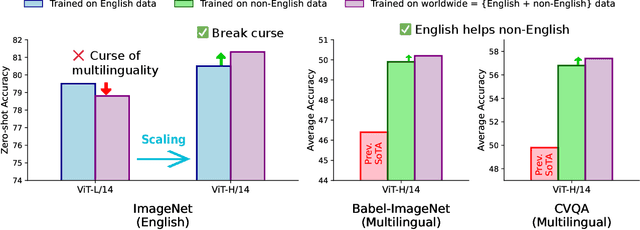
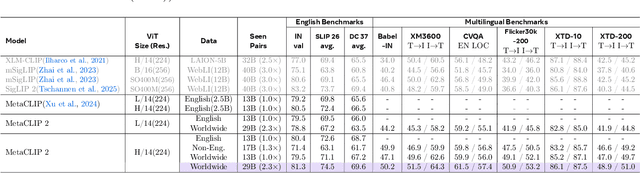
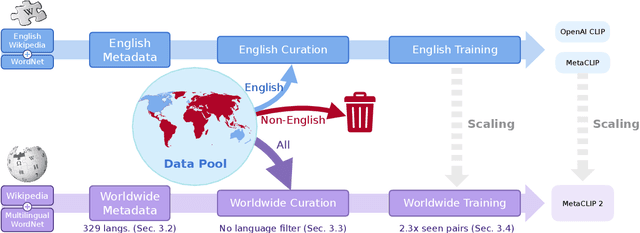

Contrastive Language-Image Pretraining (CLIP) is a popular foundation model, supporting from zero-shot classification, retrieval to encoders for multimodal large language models (MLLMs). Although CLIP is successfully trained on billion-scale image-text pairs from the English world, scaling CLIP's training further to learning from the worldwide web data is still challenging: (1) no curation method is available to handle data points from non-English world; (2) the English performance from existing multilingual CLIP is worse than its English-only counterpart, i.e., "curse of multilinguality" that is common in LLMs. Here, we present MetaCLIP 2, the first recipe training CLIP from scratch on worldwide web-scale image-text pairs. To generalize our findings, we conduct rigorous ablations with minimal changes that are necessary to address the above challenges and present a recipe enabling mutual benefits from English and non-English world data. In zero-shot ImageNet classification, MetaCLIP 2 ViT-H/14 surpasses its English-only counterpart by 0.8% and mSigLIP by 0.7%, and surprisingly sets new state-of-the-art without system-level confounding factors (e.g., translation, bespoke architecture changes) on multilingual benchmarks, such as CVQA with 57.4%, Babel-ImageNet with 50.2% and XM3600 with 64.3% on image-to-text retrieval.
NaturalThoughts: Selecting and Distilling Reasoning Traces for General Reasoning Tasks
Jul 02, 2025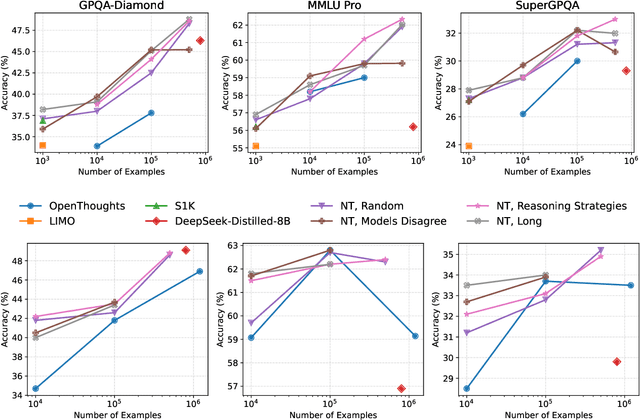
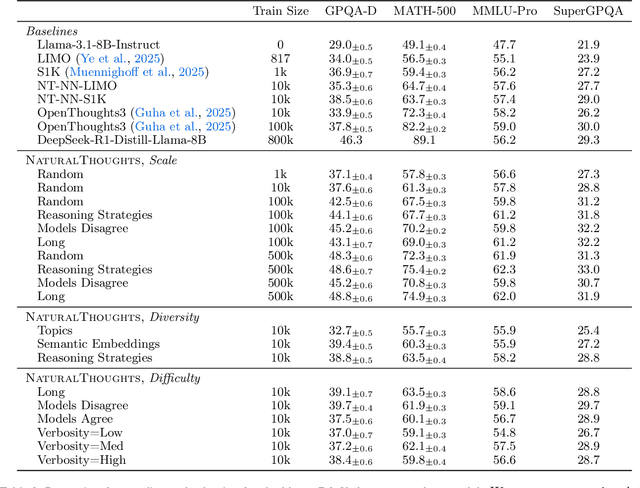
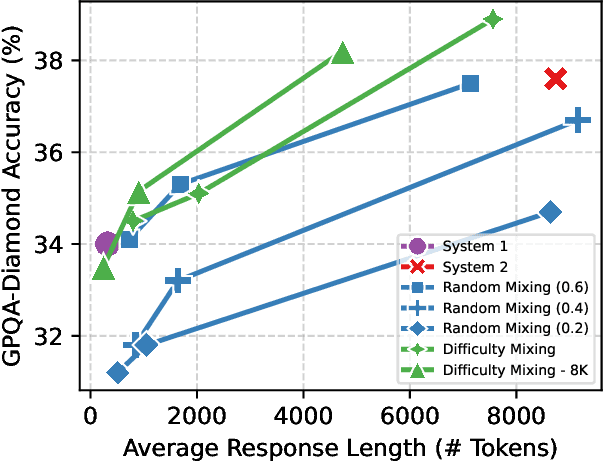
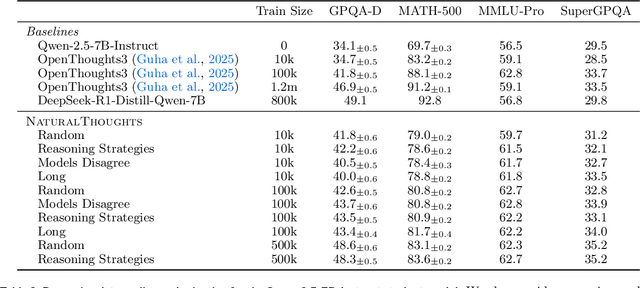
Recent work has shown that distilling reasoning traces from a larger teacher model via supervised finetuning outperforms reinforcement learning with the smaller student model alone (Guo et al. 2025). However, there has not been a systematic study of what kind of reasoning demonstrations from the teacher are most effective in improving the student model's reasoning capabilities. In this work we curate high-quality "NaturalThoughts" by selecting reasoning traces from a strong teacher model based on a large pool of questions from NaturalReasoning (Yuan et al. 2025). We first conduct a systematic analysis of factors that affect distilling reasoning capabilities, in terms of sample efficiency and scalability for general reasoning tasks. We observe that simply scaling up data size with random sampling is a strong baseline with steady performance gains. Further, we find that selecting difficult examples that require more diverse reasoning strategies is more sample-efficient to transfer the teacher model's reasoning skills. Evaluated on both Llama and Qwen models, training with NaturalThoughts outperforms existing reasoning datasets such as OpenThoughts, LIMO, etc. on general STEM reasoning benchmarks including GPQA-Diamond, MMLU-Pro and SuperGPQA.
VoiceStar: Robust Zero-Shot Autoregressive TTS with Duration Control and Extrapolation
May 26, 2025We present VoiceStar, the first zero-shot TTS model that achieves both output duration control and extrapolation. VoiceStar is an autoregressive encoder-decoder neural codec language model, that leverages a novel Progress-Monitoring Rotary Position Embedding (PM-RoPE) and is trained with Continuation-Prompt Mixed (CPM) training. PM-RoPE enables the model to better align text and speech tokens, indicates the target duration for the generated speech, and also allows the model to generate speech waveforms much longer in duration than those seen during. CPM training also helps to mitigate the training/inference mismatch, and significantly improves the quality of the generated speech in terms of speaker similarity and intelligibility. VoiceStar outperforms or is on par with current state-of-the-art models on short-form benchmarks such as Librispeech and Seed-TTS, and significantly outperforms these models on long-form/extrapolation benchmarks (20-50s) in terms of intelligibility and naturalness. Code and model weights: https://github.com/jasonppy/VoiceStar
SelfCite: Self-Supervised Alignment for Context Attribution in Large Language Models
Feb 13, 2025



We introduce SelfCite, a novel self-supervised approach that aligns LLMs to generate high-quality, fine-grained, sentence-level citations for the statements in their generated responses. Instead of only relying on costly and labor-intensive annotations, SelfCite leverages a reward signal provided by the LLM itself through context ablation: If a citation is necessary, removing the cited text from the context should prevent the same response; if sufficient, retaining the cited text alone should preserve the same response. This reward can guide the inference-time best-of-N sampling strategy to improve citation quality significantly, as well as be used in preference optimization to directly fine-tune the models for generating better citations. The effectiveness of SelfCite is demonstrated by increasing citation F1 up to 5.3 points on the LongBench-Cite benchmark across five long-form question answering tasks.
How to Learn a New Language? An Efficient Solution for Self-Supervised Learning Models Unseen Languages Adaption in Low-Resource Scenario
Nov 27, 2024



The utilization of speech Self-Supervised Learning (SSL) models achieves impressive performance on Automatic Speech Recognition (ASR). However, in low-resource language ASR, they encounter the domain mismatch problem between pre-trained and low-resource languages. Typical solutions like fine-tuning the SSL model suffer from high computation costs while using frozen SSL models as feature extractors comes with poor performance. To handle these issues, we extend a conventional efficient fine-tuning scheme based on the adapter. We add an extra intermediate adaptation to warm up the adapter and downstream model initialization. Remarkably, we update only 1-5% of the total model parameters to achieve the adaptation. Experimental results on the ML-SUPERB dataset show that our solution outperforms conventional efficient fine-tuning. It achieves up to a 28% relative improvement in the Character/Phoneme error rate when adapting to unseen languages.
Altogether: Image Captioning via Re-aligning Alt-text
Oct 22, 2024



This paper focuses on creating synthetic data to improve the quality of image captions. Existing works typically have two shortcomings. First, they caption images from scratch, ignoring existing alt-text metadata, and second, lack transparency if the captioners' training data (e.g. GPT) is unknown. In this paper, we study a principled approach Altogether based on the key idea to edit and re-align existing alt-texts associated with the images. To generate training data, we perform human annotation where annotators start with the existing alt-text and re-align it to the image content in multiple rounds, consequently constructing captions with rich visual concepts. This differs from prior work that carries out human annotation as a one-time description task solely based on images and annotator knowledge. We train a captioner on this data that generalizes the process of re-aligning alt-texts at scale. Our results show our Altogether approach leads to richer image captions that also improve text-to-image generation and zero-shot image classification tasks.
Disentangled Training with Adversarial Examples For Robust Small-footprint Keyword Spotting
Aug 23, 2024



A keyword spotting (KWS) engine that is continuously running on device is exposed to various speech signals that are usually unseen before. It is a challenging problem to build a small-footprint and high-performing KWS model with robustness under different acoustic environments. In this paper, we explore how to effectively apply adversarial examples to improve KWS robustness. We propose datasource-aware disentangled learning with adversarial examples to reduce the mismatch between the original and adversarial data as well as the mismatch across original training datasources. The KWS model architecture is based on depth-wise separable convolution and a simple attention module. Experimental results demonstrate that the proposed learning strategy improves false reject rate by $40.31%$ at $1%$ false accept rate on the internal dataset, compared to the strongest baseline without using adversarial examples. Our best-performing system achieves $98.06%$ accuracy on the Google Speech Commands V1 dataset.
SpeechPrompt: Prompting Speech Language Models for Speech Processing Tasks
Aug 23, 2024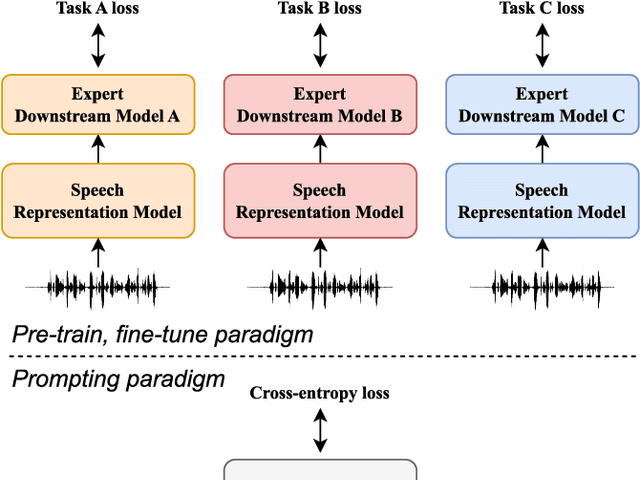
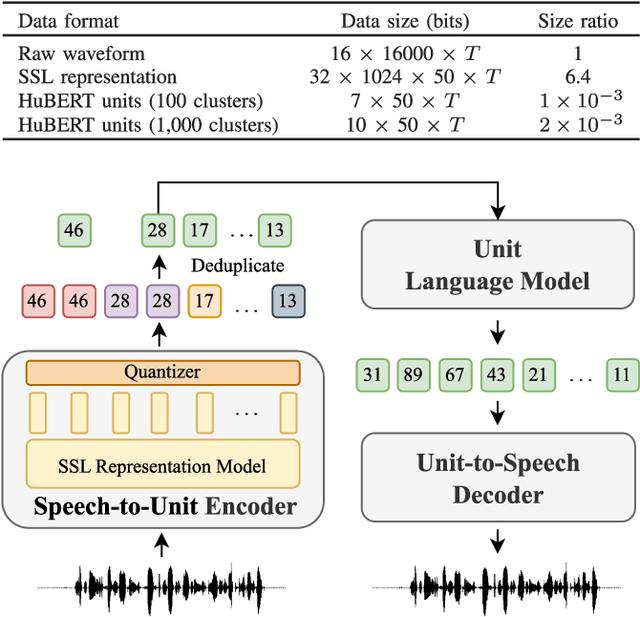
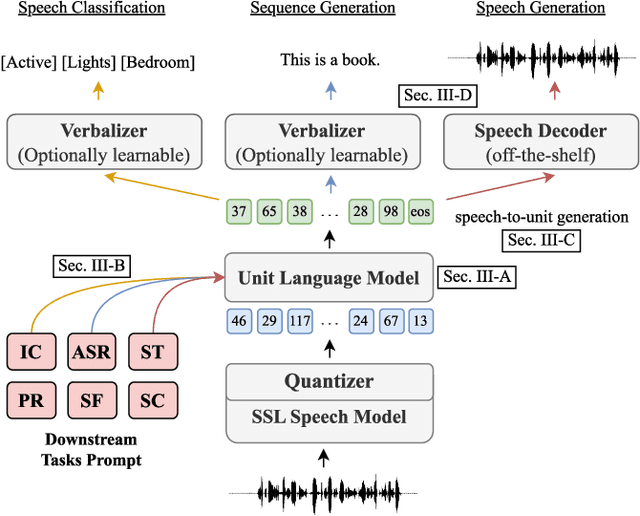
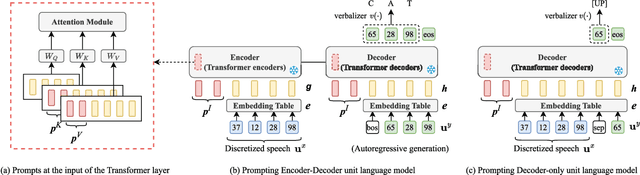
Prompting has become a practical method for utilizing pre-trained language models (LMs). This approach offers several advantages. It allows an LM to adapt to new tasks with minimal training and parameter updates, thus achieving efficiency in both storage and computation. Additionally, prompting modifies only the LM's inputs and harnesses the generative capabilities of language models to address various downstream tasks in a unified manner. This significantly reduces the need for human labor in designing task-specific models. These advantages become even more evident as the number of tasks served by the LM scales up. Motivated by the strengths of prompting, we are the first to explore the potential of prompting speech LMs in the domain of speech processing. Recently, there has been a growing interest in converting speech into discrete units for language modeling. Our pioneer research demonstrates that these quantized speech units are highly versatile within our unified prompting framework. Not only can they serve as class labels, but they also contain rich phonetic information that can be re-synthesized back into speech signals for speech generation tasks. Specifically, we reformulate speech processing tasks into speech-to-unit generation tasks. As a result, we can seamlessly integrate tasks such as speech classification, sequence generation, and speech generation within a single, unified prompting framework. The experiment results show that the prompting method can achieve competitive performance compared to the strong fine-tuning method based on self-supervised learning models with a similar number of trainable parameters. The prompting method also shows promising results in the few-shot setting. Moreover, with the advanced speech LMs coming into the stage, the proposed prompting framework attains great potential.
* Published in IEEE/ACM Transactions on Audio, Speech, and Language Processing (TASLP)